Autorin: Annika Bleich
Ein Prompt ist eine Texteingabe bestehend aus wenigen Stichworten. Sie dient der KI eines Bildgenerators als Grundlage für das Erzeugen von Bildern und ermöglicht es jeder Person, auch dir, die eigenen kreativen Ideen in Bildern umzusetzen. Aber können einzelne Stichworte wirklich das Potenzial eines Kunstwerks innehaben?
Inhalt
Einführung
Zur Definition von Kunst schreibt Brockhaus: „die Gesamtheit des vom Menschen Hervorgebrachten […] zu dessen Voraussetzungen die Verbindung von hervorragendem Können und großem geistigem Vermögen gehören.“[1] Eine KI benötigt nur ein paar Stichworte, sogenannte Prompts, und wenige Sekunden, um ein Bild zu generieren und liefert zusätzlich verschiedene Varianten.[2] Das Ergebnis kann von unzufrieden bis überragend präzise reichen. Dies steht in Abhängigkeit zum Prompt und der jeweiligen KI.[3]
Sei PromptkünstlerIn
Am Anfang steht nur eine Zeile und in diese gibst du ein paar Stichworte ein. Die Zeile gehört zu einer der zahlreichen meist offen zugänglichen Bildgeneratoren. Darunter zählen unter anderem Midjourney, Dall-E und Stable Diffusion. Wie sie im Einzelnen funktionieren, kann der jeweiligen Webseite entnommen werden. Was alle gemeinsam haben:
- Du entscheidest über den Prompt. Deine Fantasie ist Voraussetzung für den Bildinhalt.
- Nach wenigen Sekunden erhältst du in Anlehnung an deinen Prompt ein Bild. Meistens in mehreren Variationen.
Jetzt hast du ein Bild, an dem die Urheberrechte alleine dir gehören. Aber wie ist es zustande gekommen?
Wie funktioniert Text-zu-Bildsynthese?
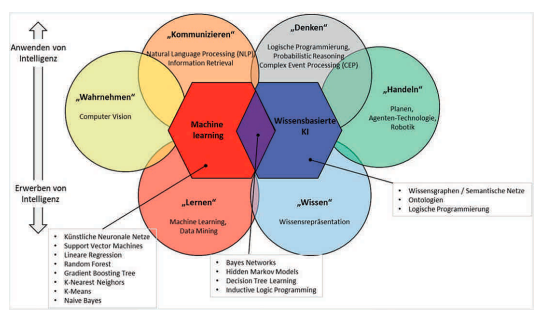
Zunächst wird eine Trainingsdatenbank mit Millionen von Bildern mit Bildbeschreibungen benötigt.[4] Die Bildbeschreibungen stammen unter anderem aus dem „alt“ Text, wie man ihn bei Html verwendet, um Bildinhalte zu beschreiben.[5] Der KI wird diese Datenbank zur Verfügung gestellt, um mittels Deep Learning, einem Lernverfahren, ihr neuronales Netz zu trainieren. Das neuronale Netz stellt, in Anlehnung an die im menschlichen Gehirn befindlichen Neuronen, eine Struktur aus miteinander vernetzten Informationen dar.[6] Es ergibt sich eine für die KI logische Verbindung zwischen Text und Bildinhalt.[7]
Die KI nutzt einen Prozess namens „Diffusion“. Ein Muster aus zufälligen Pixeln wird soweit modifiziert, bis sich daraus ein sinnvolles Bild ergibt.[8] Da es sich um einen zufälligen Prozess handelt, wird bei gleichbleibendem Prompt niemals dasselbe Bild entstehen.[9]
Dall-E und die Welt der Kunst
Unter anderem befinden sich in der Trainingsdatenbank die Bilder bekannter KünstlerInnen. Du hast also die Möglichkeit, einen Prompt dazu zu verwenden, deren Technik zu imitieren. Die UrheberInnen wurden allerdings nicht gefragt, ob sie mit der Verwendung ihrer Werke in der Datenbank und dem daraus resultierenden Nachahmen ihrer Kunst, einverstanden sind. [10]
Einerseits wird es dir und jedem anderen ermöglicht, eure künstlerischen Ideen mit wenigen Einschränkungen zu verwirklichen, ohne zuvor jahrelang benötigte handwerkliche Erfahrung sammeln zu müssen. Andererseits gefährdet dies die Arbeit unzähliger freischaffender KünstlerInnen, deren Einkommen darauf beruht, Grafiken, Illustrationen, Fotografien, Konzepte und dergleichen zu schaffen.[11] Das synthetische Werk von Jason Allen, der damit einen Kunstwettbewerb gewann, führte erst kürzlich zu regen Diskussionen.
Prompkunst und ihre Grenzen
Auch wenn dich nun das Promptfieber gepackt hat, im Universum der synthetischen Bilder unterliegt deine Fantasie gewissen Einschränkungen. Grundsätzlich unzulässig ist die Erstellung von illegalem, gewalttätigem, sexuell explizitem oder anderweitig unangemessenem Inhalt.[12] Dies soll eine missbräuchliche Nutzung der KI und das Verbreiten problematischen Bildmaterials verhindern.[13]
Die Entwickler versuchen solche Bilder unter anderem durch Wortfilter bei der Prompteingabe und durch das Filtern unangemessener Inhalte in der Trainingsdatenbank zu verhindern.[14] Hierfür muss zunächst, beruhend auf individuellem Empfinden, definiert werden, welche Inhalte unangemessen sind.[15] Das Filtern hat unter anderem zur Folge, dass sich, wie im Fall von Dall-E, bei den Ergebnissen eine deutlichere Tendenz zu Genderstereotypen, wie beispielsweise nur noch Bilder von männlichen Geschäftsführern, abzeichnet. [16]
Einen genauen Grund konnten die Entwickler für diese Tendenz nicht nennen. Unter anderem stellten sie am Beispiel des männlichen Geschäftsführers die Hypothese auf, dass, auch wenn Männer und Frauen in der ursprünglichen Trainingsdatenbank in etwa gleichmäßig repräsentiert sind, Frauen häufiger in einem sexuellen Kontext dargestellt und somit gefiltert werden. Dem so entstehenden Ungleichgewicht der Geschlechter kann unter anderem dadurch entgegen gewirkt werden, indem die gefilterte Datenbank nun mit mehr Bildern von weiblichen Geschäftsführerinnen angereichert wird.[17]
Neben Filtern arbeiten die Entwickler der Bildgeneratoren auch an weiteren Schwierigkeiten. Dazu gehören unter anderem ein fehlendes Textverständnis der KI gegenüber bestimmten Prompts oder die teils unrealistische Abbildung von Personen oder Tieren in synthetischen Bildern.[18]
Ein Blick in die Zukunft
„our mission of creating AI that benefits humanity“
OpenAI
OpenAI, die Entwickler von Dall-E, formulieren auf ihrer Webseite diesen ambitionierten Wunsch. Unrealistisch ist dieser Anspruch nicht. Irgendwann soll die Leistung von KIs menschenähnliches Niveau erreichen, was in vielen wichtigen Bereichen wie zum Beispiel der Landwirtschaft, Automobilindustrie oder Pflege enorm hilfreich sein wird. [19]
Neben Bildern kann eine KI wie NUWA-Infinity mittlerweile sogar kurze Videoclips generieren. Zwar sind diese noch lange nicht perfekt, betrachtet man jedoch allein die rasante Entwicklung in den letzten Wochen, stellt sich die Frage, ob KIs irgendwann sogar in der Lage sind, ganze Filme synthetisch zu erstellen. Eine weitere Open Source KI von OpenAi namens ChatGPT, veröffentlicht im November 2022, ist bereits dazu in der Lage, wissenschaftliche Texte auf Grundlage von Texteingaben zu formulieren. [20]
Der Beginn einer neuen Kunstepoche?
Bislang reicht noch längst nicht jeder Prompt für ein Kunstwerk aus. Jason Allen investierte bereits mehrere Tage Arbeit mit Unterstützung eines Bildbearbeitungsprogramms, um sein beim Kunstwettbewerb eingereichtes Bild zu kreieren.[21] Die Gefährdung von KünstlerInnen durch Bildgeneratoren scheint zunächst zwar greifbar, aber wann die Arbeit von KIs tatsächlich menschenähnliches Niveau erreicht, bleibt vorerst eine Frage der Zeit.[22]
Ein Blick in die Vergangenheit hilft, um zu sehen, dass zumindest eine Definition von Kunst schon immer anpassungsfähig war. Auch die Entwicklung der Fotografie wurde lange Zeit nicht als Kunst anerkannt.[23] Und vielleicht wird eines Tages das Generieren synthetischer Bilder zu den Kunstmaßstäben einer zukünftigen Epoche gehören.
“Die Einschätzung von Kunst hängt von den Maßstäben einer Epoche und von der individuellen Sicht ab.”
Brockhaus Enzyklopädie Online
Literaturquellen
AI IMPACTS (2022): Will Superhuman AI be created? Online unter https://aiimpacts.org/argument-for-likelihood-of-superhuman-ai/ [Abruf am 10.01.2023]➝[19]
Brockhaus Enzyklopädie Online (o.J.): neuronale Netze (künstliche Intelligenz). Online unter https://brockhaus.de/ecs/enzy/article/neuronale-netze-kunstliche-intelligenz [Abruf am 10.01.2023]➝[1]➝[7]
Ford, Martin (2019): Die Intelligenz der Maschinen. Frechen: mitp Verlags GmbH & Co (mitp Professionals). Online unter https://content-select.com/de/portal/media/view/5e4ba26b-d1d4-49a1-93de-6b1fb0dd2d03 [Abruf am 10.01.2023] S. 9 ➝[6] ; S. 525 – 526 ➝[22]
Jäger, Jens (2009): Fotografie und Geschichte. Frankfurt am Main: Campus Verlag (Historische Einführungen). Online unter https://content-select.com/de/portal/media/view/519cc341-67b0-479d-9047-290f5dbbeaba [Abruf am 10.01.2023] S. 56➝[23]
Midjourney (2022): Content and Moderation. Online unter https://midjourney.gitbook.io/docs/content-and-moderation-policy [Abruf am 10.01.2023]➝[12] ➝[13] ➝[14]
Nichol, Alex (2022): Dall-E 2 Pre-Training Mitigations. Online unter https://openai.com/blog/dall-e-2-pre-training-mitigations/?itid=lk_inline_enhanced-template [Abruf am 10.01.2023]➝[16] ➝[17]
OpenAI (o.J.): Dall-E 2. Online unter https://openai.com/dall-e-2/ [Abruf am 10.01.2023]➝[8]
Rentjes, Thomas (2022): Foto-Synthese mit KI. Die Revolution der künstlichen Bilder. Online unter https://www.deutschlandfunkkultur.de/ki-technologie-revolution-kuenstliche-bilder-100.html [Abruf am 10.01.2023]➝[2] ➝[3] ➝[4] ➝[11] ➝[14] ➝[15] ➝[18] ➝[20]
Tiku, Nitasha (2022): AI can nox create any image in seconds, bringing wonder and danger. In: The Washington Post vom 22.09.2022. Online unter https://www.washingtonpost.com/technology/interactive/2022/artificial-intelligence-images-dall-e/ [Abruf am 10.01.2023]➝[10] ➝[21]
Vox (2022): The text-to-image revolution, explained. Video publiziert am 01.06.2022 auf YouTube. Online unter https://www.youtube.com/watch?v=SVcsDDABEkM [Abruf am 10.01.2023] (06:09)➝[5]; (09:35) ➝[9]
Bildquellen
Alle verwendeten Bilder stehen unter dem Copyright der Autorin © Annika Bleich (cc by-nc)
Videoquelle
tagesschau (2023): Software ChatGPT: Möglichkeiten und Grenzen künstlicher Intelligenz. Video publiziert am 12.01.2023 auf YouTube. Online unter https://www.youtube.com/watch?v=_ab6L50HlcI [Abruf am 29.01.2023]