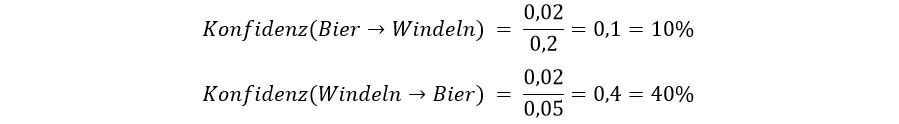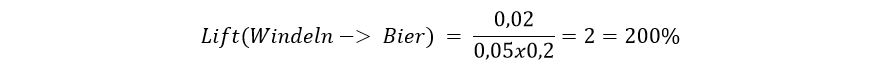Autor: Esben Christian Pedersen
Inhalt
Was ist Flask überhaupt?
Flask ist ein WSGI Micro-Framework für Webapplikationen. Ursprünglich wurde Flask als Aprilscherz von Armin Ronacher im Jahr 2010 entwickelt. Auf Grund steigender Beliebtheit unter den Usern, gründete Armin Ronacher die „The Pallets Project“-Sammlung von Open Source Code Bibliotheken. Diese Sammlung dient nun als Organisation hinter Flask und weiteren Bibliotheken wie Werkzeug und Jinja, um die Flask aufgebaut ist. Dabei stützt sich Flask nur auf die nötigsten Komponenten die für die Webentwicklung benötigt werden ( routing, request handling, session). Alle anderen Komponenten müssen dementsprechende entweder selbst entwickelt oder über zusätzliche Pakete hinzugefügt werden.[1]
Was Flask so außergewöhnlich macht ist der simple Einstieg und die Effizienz im Zusammenspiel mit anderen Python Bibliotheken. Was dem Entwickler erlaubt Web-Applikationen mit Flask im größeren Stil zu entwickeln und auszubauen, ohne dem Entwickler etwas aufzuzwingen. Da die „The Pallets Project“-Sammlung sich einer großen Unterstützer Community erfreut, gibt es viele Erweiterungsmöglichkeiten welche die Funktionalität erhöhen und Flask äußerst flexibel werden lässt.[2]
Wie das Micro-Framwork Flask funktioniert soll in den folgenden Teilen dieses Beitrags deutlich werden. Sei es die simple installation, oder die einfach Handhabung.
Installation
Wie einfach es ist mit Flask eine Web-Applikation mit Flask zu erstellen soll in den folgenden Abschnitten deutlich werden.
Des Weiteren bietet es sich an beim Entwickeln einer Flask Web-Applikation eine virtuelle Entwicklungsumgebung wie Pythons hauseigene virtualenv zu verwenden um Projektabhängigkeiten und Bibliotheken für jedes Projekt entsprechend zu verwalten. Außerdem ermöglicht die virtualenv eine schnelle und einfach Portierung bzw. ein schnelles unkompliziertes Deployment einer Applikation.
Wie Pythons virtuelle Entwicklungsumgebung funktioniert ist hier näher beschrieben „virtualenv“.
Um Flask zu installieren kann man einfach „pip“ benutzen. Dies ist der Package Installer für Python:
$ pip install FlaskSo einfach lässt sich Flask installieren mit seinen benötigten Paketen installieren.[3]
Hello World!
Wie einfach das erstellen einer Web Applikation mit Python und Flask ist soll an einem simplen „Hello World“ Beispiel verdeutlicht werden. Dazu wird die Datei „app.py“ angelegt. Diese lässt sich einfach mit einem Texteditor öffnen und bearbeiten (z.B. PyCharm oder VS Code).
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return "Hello World!"
if __name__ == '__main___':
app.run()
Zur Erklärung: In Zeile 1 importieren wir Flask und in initieren in Zeile 3 eine neue Instanz der Flask-Klasse und weisen sie der Variable „app“ zu. In Zeile 5 wird ein „Decorator“ benutzt um die Route/View „/“ der View-Funktion „index()“ zuzuweisen. Also einfach gesagt: Wird die Seite „/“ des Servers im Browser angefragt, so führt dieser die View-Funktion aus die den Content „Hello World!“ bereitstellt.[4]
Der letzt Abschnitt des Codes startet den Server sobald die Datei für den Interpreter aufgerufen wird. Wenn alles richtig installiert ist sollte nun folgender output zu sehen sein:
(webapp) $ py app.py
* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
Die im Code erstellte Seite „/“ mit der „index()“-Funktion lässt sich einfach über den Webbrowser öffnen. Dazu lediglich in der Adresszeile des Browser auf „http://localhost:5000/“ oder „http://127.0.0.1:5000/“ aufrufen. Die aufgerufene Seite sollte nun „Hello World!“ in der linken oberen Ecke zeigen.
Routing and Views
Routing bezeichnet das auflösen und händeln von URLs. Dabei soll beim aufrufen einer URL der korrekte Inhalt im Browser dargestellt werden. Bei Flask wird dies mit dem Route- „Decorator“ eine Funktion an eine URL gebunden um ihren Content nach dem Aufrufen der URL bereitzustellen. Das folgende Bild soll den Ablauf der URL Auflösung und dem damit verbunden bereitstellen von Content verdeutlichen.[5]
Im vorangegangenen Hello World Beispiel wird dies in Zeile 5 und 6 gemacht. Nach dem aufrufen der URL „http://localhost:5000/“ sollte in der Konsole/der Shell folgendes zu sehen sein:
(webapp) $ py app.py
* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [29/Jan/2021 11:56:33] "GET / HTTP/1.1" 200 –Es ist zu sehen das der Browser eine Anfrage für die „/“-Route an den Server stellt. Dieser verarbeitet die Anfrage entsprechend der mit der Route verbundenen View-Funktion „index()“. Im Anschluss sendet der Server http-status: 200 (OK) und rendert „Hello World!“.
In der Konsole stehen sämtliche Anfragen und http-status codes die vom Flask-Server verarbeitet werden.
Routen und http-Methoden:
Der „Decorator“ kann ein weiteres Argument annehmen. Dieses Argument ist eine Liste mit den für den „Decorator“ erlaubten http-Methoden.
from flask import Flask
app = Flask(__name__)
@app.route(„/users/“, methods=['GET', 'POST'])
def users():
# Routr Logic #
Somit lassen sich Routen in der Nutzung bestimmter http-Methoden einschränken. Ist jedoch keine Liste angegeben so ist die „GET“-Methode als Standard festgelegt.
Mithilfe der „Decorator“ lassen sich auch dynamische und variable Regeln für Routen festlegen, da statische Routen eine Website stark einschränken können. So lässt sich im folgenden Beispiel eine Profilseite für registrierte User anlegen oder gepostete Artikel/Beiträge bekommen eine eigene URL basierend auf dem Datum an dem sie Online gestellt worden und ihrem Titel.
Dabei geben die „<>“ an ob es sich um eine Variable handelt. So lassen sich Routen dynamisch generieren. Zusätzlich lässt sich der Variablen-Typ angeben der verarbeitet werden soll „<datatype:variablename>“. Folgende Variablentypen sind für Routen vorgesehen und möglich:
- string: Akzeptiert Text ohne „/“.
- int: Akzeptiert ganze Zahlen (integers).
- float: akzeptiert numerische Werte die einen Dezimalpunkt enthalten.
- path: Akzeptiert Text mit „/“ (Pfadangaben)
Dynamische Routen können dementsprechend im Gegensatz zu statischen Routen Parameter entgegennehmen und verarbeiten. Somit ließe sich auch eine API mit Flask umsetzen um Daten für User zugänglicher und nutzbarer zu machen oder einen erhöhten Automatisierungsgrad für Datenabfragen zu ermöglichen. Um dies deutlich zu machen dienen die folgenden Beispiele:[6]
from flask import Flask, escape
app = Flask(__name__)
@app.route(„/users/<username>“)
def profile(username):
return f'<h1>Welcome { escape(username) }</h1>'
from flask import Flask, escape
app = Flask(__name__)
@app.route(„/article/<int:year>/<int:month>/<title>“)
def article(year, month, title):
month_dict = {
"1": "January",
"2": "February",
"3": "March",
"4": "April",
"5": "May",
"6": "June",
"7": "July",
"8": "August",
"9": "September",
"10": "October",
"11": "November",
"12": "December"
}
return f'<h1>"{ escape(title) }" from { escape(month_dict[str(month)]) } { escape(year) }</h1>'
So einfach diese Beispiele sind, so geben sie doch einen deutlichen Ausblick auf die Möglichkeiten, welche sich mit Flask bieten. Welche Unternehmen Flask in ihrer Entwicklung benutzen kann hier eingesehen werden.
Die Template Engine
Wie werden jetzt aus statischen HTML-Dateien dynamische Websiten mit Flask? Ganz einfach, mit Hilfe der eingebauten Template Engine Jinja. Jinja ist eine vielseitige und einfache Templete Engine mit der sich unter anderem auch dynamische HTML-Inhalte erstellen lassen. Sie basiert dabei auf der „Django“ Template Engine bietet jedoch viel mehr Möglichkeiten wie volle „unicode“ Unterstützung und „automatic escaping“ für mehr Sicherheit in Webanwendungen. Zusätzlich lassen sich die gängisten verwendeten Codeblöcke der html-templates immer wieder verwenden und vielseitig einsetzen. Dabei verwendet die Template Engine Variablen, Ablauflogiken und Anweisungen um im Template verwendete Ausdrücke mit Inhalt zu füllen.[7]
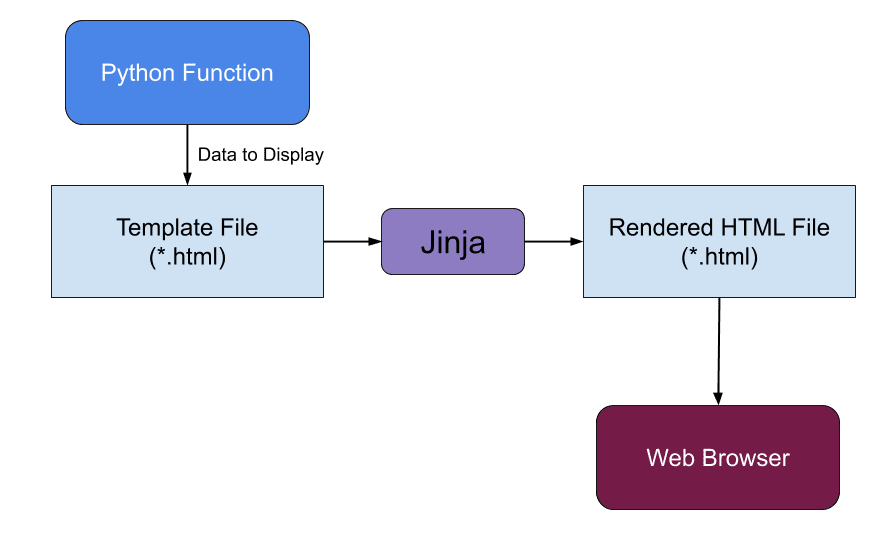
Um das ganze noch mehr zu veranschaulichen dient der folgende Beispiel Code mit der angegeben Projektstruktur:
|-- app.py
|-- static
| `-- css
| `-- main.css
-- templates
|-- about.html
|-- index.html
|-- layout.html
`-- page1.html<!DOCTYPE html>
<html lang="en">
<head>
<!-- meta tags -->
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<!-- Title: -->
<title>Flask App</title>
<link rel="stylesheet" href="{{ url_for('static', filename='css/main.css') }}">
</head>
<!-- Start of body -->
<body>
<header>
<h1>Flask Web App</h1>
</header>
<div class="navbar">
<strong><ul class="navmenu">
<li><a href="{{ url_for('home') }}">Home</a></li>
<li><a href="{{ url_for('page1') }}">Page 1</a></li>
<li><a href="{{ url_for('about') }}">About</a></li>
</ul></strong>
</div>
<content>
<div class="container">
<!-- At this place the child templates get rendered by Flask -->
{% block content %}
{% endblock %}
</div>
</content>
</body>
</html>
{% extends "layout.html" %}
{% block content %}
<br>
<br>
<h1> Welcome to the Flask Web App</h1>
<br>
<br>
{% endblock %}
{% extends "layout.html" %}
{% block content %}
<br>
<br>
<h1> Page 1 example</h1>
<br>
<br>
{% endblock %}
{% extends "layout.html" %}
{% block content %}
<br>
<h2> About this Web App:</h2>
<br>
<h3> This App was build using Flask</h3>
{% endblock %}
/* main.css file containing the styling information for the flask webapp */
body {
margin: 10;
padding: 5;
font-family: "Helvetica Neue", Arial, Helvetica, sans-serif;
color: #444;
}
/* Header */
header {
background-color: lightblue;
height: 40px;
width: 100%;
opacity: .9;
margin-bottom: 10px;
}
header h1 {
margin: 0;
font-size: 1.7em;
color: black;
text-transform: uppercase;
float: left;
}
/* Body content */
.container {
width: 100%;
margin: 15;
}
/* navbar */
.navbar {
margin: 5px;
padding: 5px;
border: 5px;
}
.navmenu {
float: left;
margin-top: 8px;
margin-bottom: 8px;
padding: 5px;
}
.navmenu li {
display: inline;
}
.navmenu li a {
color:slategray;
text-decoration: none;
}
from flask import Flask, escape, render_template
app = Flask(__name__)
# Routes and Views:
@app.route("/")
def home():
return render_template('index.html')
@app.route("/about/")
def about():
return render_template('about.html')
@app.route("/page1/")
def page1():
return render_template('page1.html')
# run flask server:
if __name__ == '__main__':
app.run()
Wird der Server nun gestartet und im Browser die einzelnen Seiten der Applikation aufgerufen werden die html-templates für die entsprechende Seite gerendert.
Die Möglichkeiten zum nutzen von Templates sind schier endlos für Flask und bieten viel Raum für eigene Ideen und Umsetzungsmöglichkeiten in der Webentwicklung.
Fazit
Flask ist eine tolle Möglichkeit zum Einstieg in die Webentwicklung und bietet vielseitige Umsetzungsmöglichkeiten für Applikation, Websites oder APIs. Zudem ist es einfach zu lernen. Die dahinter stehende Community, die Umfangreiche Dokumentation, die Möglichkeit jedes Python Package miteinzubeziehen und die Masse an Tutorials bieten viel Raum um sich, Flask und die eigene App zu entwickeln/weiterzuentwickeln. Ohne das Flask dabei den Entwickelnden Rahmenbedingungen aufzwingt. Zusätzlich ist Lernkurve recht klein und der Entwickler wächst schnell in die Anforderungen und Möglichkeiten hinein.
- Stender, Daniel (2017): Tropfen um Tropfen. In: Entwickler Magazin, Jg. 2017, H. 6. Online unter: https://kiosk.entwickler.de/entwickler-magazin/entwickler-magazin-6-2017/tropfen-um-tropfen/ [Abruf am 10.01.2021]
- Stender, Daniel (2017): Tropfen um Tropfen. In: Entwickler Magazin, Jg. 2017, H. 6. Online unter: https://kiosk.entwickler.de/entwickler-magazin/entwickler-magazin-6-2017/tropfen-um-tropfen/ [Abruf am 10.01.2021]
- The Pallets Project (2020): Installation. Online unter https://flask.palletsprojects.com/en/1.1.x/installation/ [Abruf am 04.01.2021]
- The Pallets Project (2020): A minimal application. Online unter https://flask.palletsprojects.com/en/1.1.x/quickstart/#a-minimal-application [Abruf am 04.01.2021]
- The Pallets Project (2020): Routing. Online unter https://flask.palletsprojects.com/en/1.1.x/quickstart/#routing [Abruf am 04.01.2021]
- The Pallets Project (2020): Variable Rules. Online unter: https://flask.palletsprojects.com/en/1.1.x/quickstart/#variable-rules [Abruf am 04.01.2021]
- The Pallets Project (2020): Templating. Online unter: https://flask.palletsprojects.com/en/1.1.x/templating/ [Abruf am 04.01.2021]
Alle Codebeispiele sind selbst erarbeitet und getestet.
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2020/21, Prof. Dr.-Ing. Steinberg) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.


 Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.
Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.