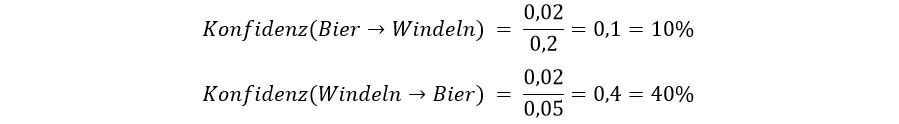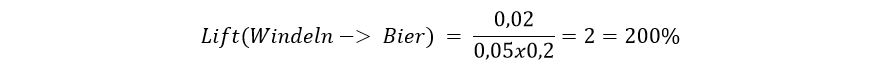Autor*in: Melanie Hartkopf
Ihr habt euch für die Webentwicklung entschieden – Glückwunsch. Ein Feld, so überlaufen wie kaum ein anderes. Hinter jeder Ecke wartet ein neues Projekt mit dem die Entwicklung einfacher, effektiver, schneller und sicherer sein soll. In dem Dschungel an Möglichkeiten ist es leicht, sich zu verirren. Deswegen stelle ich euch heute zwei der beliebtesten Frameworkes in Sachen Single-Page-Webanwendungen vor und vergleiche. React oder Angular (nicht zu verwechseln mit der Vorgängerversion AngularJS) – welches Framework passt am besten zu dir?
Der Beitrag in der Übersicht
Du kennst dich bereits aus? Dann spring doch gleich an die Stelle, die dich interessiert!
Die Welt der Single-Page-Webanwendungen
Single-Page-Applications, kurz SPA unterscheiden sich von herkömmlichen Webanwendungen insbesondere in einem Punkt – es gibt nur eine einzige HTML-Datei. Hierauf können Daten verändert und/oder dynamisch geladen werden. Die Verarbeitung ist somit client-seitig. Soll also beispielsweise etwas durch User-Interaktion geändert werden, wird keine neue HTML-Datei geladen, sondern die Datei client-seitig verändert.

Veranschaulicht seht ihr den Vorgang in dieser Grafik. Am Anfang arbeiten normale Webanwendungen genau wie SPAs. Die allererste Anfrage wird vom Client an den Server geschickt, welche mit einer HTML-Datei antwortet. Während sich bei der SPA diese niemals ändert, wird bei einer herkömmlichen Webanwendung dieser Vorgang wiederholt (sieht rote Pfeile). Findet eine neue Abfrage mittel POST statt, wird auch eine neue HTML-Datei von dem Server an den Client geschickt – und die Seite lädt neu. Bei SPAs (siehe grüne Pfeile) wird eine Anfrage mittels AJAX gesendet und mittels JSON wird die HTML Datei verändert.
Kein neues Laden, keine langen Wartezeiten. SPAs sind schneller und genau deshalb in der Webentwicklung immer beliebter.1 Nun aber zurück zu unseren SPAs Angular und React.
Angular & React – Was haben sie gemein?
Beide Plattformen sind Vorreiter in der Webentwicklung, genauer gesagt der Frontend-Entwicklung, da sowohl Angular, wie auch React eine Komponentenhierachie verwenden.
Kleiner Exkurs: Komponenten verwalten immer einen Teil einer View und können Unterkomponenten haben. Beide Projekte sind Open Source unter MIT Lizenz. Freier Zugang also. Auch auf die Community hinter beiden Plattformen könnt ihr euch verlassen.2 So glänzt insbesondere React mit inzwischen rund 149.000 Sternen auf Github. So gut wie jede Frage, die während der Entwicklung aufkommen wird, wurde bereits gefragt und beantwortet. Aber was zeichnet Angular und React aus? Und wer steht dahinter?
Wenn ihr einen schnellen Einblick über den Aufbau von Angular und React sucht, dann schaut am besten auf Stackblitz oder einer ähnlichen Seite vorbei. Dort könnt ihr ohne großen Aufwand ein Projekt mittels Angular oder React starten und euch mit den Strukturen vertraut machen, bevor ihr euch entscheidet.
Angular – Googles Framework 2.0

So könnte auch euer erstes Projekt in Angular starten. Das Hello World der komplexen Ordnerstruktur von Angular.
Ihr fangt grade erst mit der Webentwicklung an und versteht schon jetzt die Welt nicht mehr? Ihr habt noch nie etwas von Angular gehört? Dann schaut dieses Video, in dem Angular simpel für Beginner erklärt wird und lest danach weiter.
Angular ist ein Framework von Google, welches 2016 auf dem Markt erschienen ist, es ist also relativ „frisch“. Allerdings ist Angular kein Neuling, denn schon lange vor Angular gab es AngularJS. Die Vorgängerversion erschien bereits 2010. AngularJS und Angular sind nicht kompatibel, da Angular ein komplett neues Konzept vertritt und auch in einer neuen Sprache geschrieben ist – TypeScript. Diese Sprache wird auch in der Entwicklung mittels Angular verwendet.3
TypeScript? Aber ich kann doch nur JavaScript? Muss ich für Angular eine komplett neue Sprache lernen?
Keine Sorge, Angular ist für jeden verwendbar. Zwar empfiehlt das Team von Angular, TypeScript zu verwenden, aber auch reines JavaScript ist möglich. Die Chancen, die TypeScript bietet, sind aber nicht zu verachten. Und der Unterschied zwischen TypeScript und JavaScript ist gar nicht groß. Der Name sagt schon alles, was ihr Wissen müsst. TypeScript arbeitet mit Typen, erkennt, wenn falsche Typen deklariert werden – und warnt, was JavaScript allein nicht tut.4 Ein schneller Einstieg gelingt euch beispielsweise mit diesem Kurs.
Angular verwendet das Model-View-View Model. Sagt dir nichts? Macht nichts, im nachfolgenden Video wird es schnell und simpel erklärt.
React – Facebooks mächtige Bibliothek

Simple Ordnerstrukturen, verwirrender Code. So beginnt das Hello World von React.
Ein großes Fragezeichen steht über euren Köpfen, wenn Ihr React hört? Dann schaut am besten dieses Video als fixen Einstieg.
React ist genaugenommen gar kein Framework, sondern nur eine JavaScript Bibliothek. Geschaffen 2011, von niemand anderem als Facebook, ist React wohl der beste Indikator dafür, dass eine einfache Bibliothek mächtiger sein kann, als man denkt. Der wichtigste Unterschied zu einem Framework ist, dass React sich einzig auf die View Ebene beschränkt. Zwar ist React relativ simpel aufgebaut, es lassen sich aber viele weitere Bibliotheken sehr einfach integrieren.5
Hinzu bietet React eine JavaScript-Syntax-Erweiterung mittels JSX, was vergleichbar mit XML ist. Aber wieso? Das Ziel von JSX ist es, das komplette User-Interface mittels einzelner Komponenten nachzubauen, um HTML in JavaScript zu integrieren. Richtig gehört, die Realität ist bei React einmal komplett verdreht worden. Standardgemäß wird nämlich JavaScript in HTML integriert. So wird nicht nur der Code übersichtlicher, sondern auch DOM-Manipulation fast unmöglich gemacht.6
Was solltest du wählen?
Viel Input, aber immer noch keine klare Empfehlung. Ich entschuldige mich – auch dafür, dass ihr vielleicht noch immer eine klare Empfehlung erwartet. Denn leider ist es nicht einfach zu sagen, zu wem React und zu wem Angular passt. Ein paar einfache Tipps kann ich euch aber mit auf den Weg geben.

Angular gilt im allgemeinen als einsteigerfreundlicher, sowohl für Neulinge in der Web-Entwicklungswelt, als auch für Entwickler, die bereits Erfahrungen mit Java oder C++ gesammelt haben. Aber auch React hat viele Vorteile und ist nicht umsonst das beliebteste Framework, ohne überhaupt ein Framework zu sein.

Ein Anreiz für React ist der Virtueller DOM, wodurch alles deutlich schneller wird, Angular kann hier nicht mithalten. Hinzu ist React auch bei kleineren Projekten gut geeignet, Angular wirkt dahingehend schnell überladen. Durch die schnell hinzufügbaren Bibliotheken ist React sehr flexibel und auch bei großer Interaktivität nützlich. Angular ist durch seine vielen vordefinierten Funktionen eher funktionabel als flexibel und bei geringer Interaktivität besser.7
React arbeitet mit JSX, was für Einsteiger abschreckend wirken kann. Oft kommt viel Code in einer Datei zusammen. Angular hingegen arbeitet mit HTML, erweitert mit Direktiven. React arbeitet mit dem One-Way-Binding, wodurch die Applikation schneller und flüssiger wird, aber insbesondere wird das Debuggen erleichtert. Angular arbeitet mit einem Double-Blind-Feature, wird also auf der einen Seite etwas verändert, verändert sich die andere Seite ohne, dass dafür etwas getan werden muss. So wird die Seite sehr schnell und responsiv, ein wichtiger Faktor.8
Angulars größter Anreiz ist wohl das, was viele Neulinge auf den ersten Blick abschreckt – TypeScript. Diese Sprache ist allerdings nicht mehr aufzuhalten und wird immer mehr verwendet. Sie ist relativ schnell zu lernen und öffnet viele neue Möglichkeiten. Wenn nicht jetzt, wann dann?
React oder Angular? And the winner is …
Auf wen fällt meine Wahl? Das wird wohl immer davon abhängen, was ich mit meiner Single-Page-Webanwendung erreichen will und wie. Arbeite ich allein oder im Team? Wie ist die Vorerfahrung von jedem einzelnen und wie die Vorlieben? Was ist das Ziel des Projekts?
Eine richtige oder falsche Wahl gibt es kaum. Eher zählt das subjektive Empfinden jedes Einzelnen. Also, wie fällt deine Wahl aus? React oder Angular?
Erstellen Sie Ihre eigene Umfrage zu Nutzerfeedback.
Quellen
1 Domin, Andreas (2018): Was ist eigentlich eine Single-Page-Webanwendung? Online unter https://t3n.de/news/single-page-webanwendung-1023623/ [Abruf am 11.05.2020]
2 Schlemmer, Frederik (2019): Angular, React oder vue.js? Eine Entscheidungshilfe. Online unter am 19.05.2020]
3 Gosebrink, Fabian (2017): Ein Überblick über Angular. Online unter https://www.digicomp.ch/blog/2017/01/16/angular-ein-uberblick [Abruf am 16.05.2020]
4 Tillmann, Janna (2017): Was ist eigentlich Typescript? Online unter https://t3n.de/news/eigentlich-typescript-859869/ [Abruf am 14.05.2020]
5 Österle, Jonas (2017): React — Eine Einführung in fünf Minuten. Online unter https://medium.com/brickmakers/react-eine-einf%C3%BChrung-in-f%C3%BCnf-minuten-515dc38ceb73 [Abruf am 12.05.2020]
6 Gude, Thomas (2016): React und seine Alternativen. Online unter https://entwickler.de/online/javascript/react-244922.html [Abruf am 12.05.2020]
7 Ventzke Media (2018): Angular vs. React – Ein ausführlicher Vergleich. Welche Bibliothek passt zu Ihrem Projekt? Online unter https://www.ventzke-media.de/blog/angular-vs-react-vergleich.html [Abruf am 19.05.2020]
8 Tillmann, Janna (2017): React vs. Angular – wann ist was besser? Online unter https://t3n.de/news/react-vs-angular-besser-845241/2/ [Abruf am 19.05.2020]
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Sommersemester 2020, Andre Kreutzmann) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.



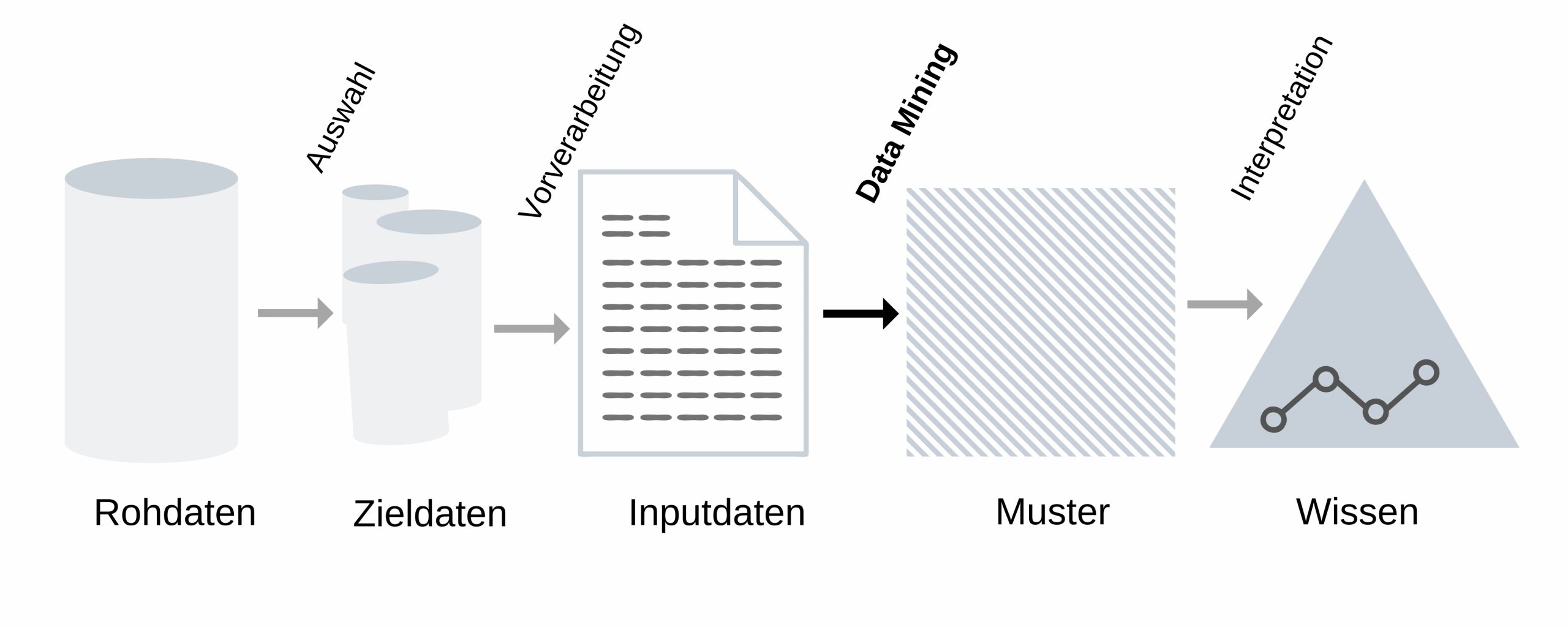
 Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.
Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.