in den vergangenen Jahrzehnten haben sich Fachgebiete wie Webtechnologie, Medieninformatik, interaktive Medien, Educational Technology oder Datenvisualisierung als eigenständige und zugleich anwendungsorientierte Disziplinen etabliert. Sie prägen maßgeblich, wie Informationen gestaltet, vermittelt und erfahrbar gemacht werden – ob im Web, in der Lehre (z.B. im Studiengang Informationsmanagement) oder in interaktiven Systemen.
Gleichzeitig verändert sich das Verständnis dieser Disziplinen im Zuge technologischer, gesellschaftlicher und kultureller Dynamiken. Insbesondere die zunehmende Verfügbarkeit intelligenter Systeme, generativer KI und interaktiver Real-Time-Technologien erweitert nicht nur die Werkzeugsets dieser Disziplinen, sondern verschiebt auch deren theoretische und gestalterische Grundlagen.
Interdisziplinär und integrativ: Information Design und Creative Technology
Vor diesem Hintergrund gewinnen Creative Technology und Information Design als interdisziplinäre und integrative Fachgebiete an Bedeutung. Sie verbinden kreative Gestaltungspraktiken mit technologischer Expertise und stellen den Menschen als Akteur im physisch-digitalen Raum in den Mittelpunkt. Dabei geht es nicht nur um die technische Umsetzung, sondern auch um Fragen wie z.B. der kritischen Reflektion, gesellschaftlichen Relevanz, Zugänglichkeit, Verständlichkeit, Ethik, Partizipation und Ästhetik.
Gerade im Zeitalter von Creative AI entstehen neue Formen der kollaborativen Gestaltung zwischen Mensch und Maschine, die tradierte Grenzen zwischen Entwickler*innen, Designer*innen und Nutzer*innen auflösen. Dies erfordert neue Kompetenzen – von der kritischen Reflexion über KI-generierte Inhalte bis zur gestalterischen Integration intelligenter Systeme in Lern-, Arbeits- und Kommunikationsprozesse.
Creative Technology und Information Design reagieren auf diese Entwicklungen mit offenen, experimentellen und zugleich praxisorientierten Ansätzen, die technisches Wissen, Designmethodik, Datenkompetenz und gesellschaftliche Verantwortung/Haltung vereinen – mit dem übergeordneten Ziel, eine humane, verstehbare und gestaltbare Zukunft mitzuentwickeln. Auch die Grenzen zwischen physischem und digitalem Raum verschwimmen immer mehr.
Mit Neuerungen des Curriculums im Studiengang Informationsmanagement in 2024 und unter Berücksichtigung gesellschaftlich-technologischen Entwicklungen vereint Information Design als Vertiefung im Studiengang Informationsmanagement klassische Kompetenzen mit neuen, interdisziplinären Anforderungen. Ein zentraler und integrativer Bestandteil von Information Design ist der Einsatz kreativer Technologien (Creative Technology) mit Fokus auf Creative AI.
In einer Welt, in der Künstliche Intelligenz immer mehr Aufgaben übernimmt, bleibt die Fragen: Verdienen wir Abschlüsse, wenn KI die Arbeit erledigt?&Welche Rolle spielt noch die Hochschulbildung?
Mal ehrlich, wie viele von uns haben bei der letzten Hausarbeit oder Prüfung nicht schon mal heimlich ChatGPT oder andere KI-Tools benutzt? Es ist so einfach: Frag die KI, lass sie dir was raushauen, und zack – fertig. Aber das wirft eine ziemlich große Frage auf: Wenn wir uns jetzt schon so sehr auf KI verlassen, wie fit sind wir dann wirklich für die Arbeitswelt nach dem Studium?
In diesem Beitrag geht’s genau darum: Wie verändert KI unsere Hochschulbildung und unsere Zukunft als Absolvent:innen? Werden wir noch die Skills haben, die wir wirklich brauchen, oder macht uns die KI ein bisschen zu bequem?
2. Die aktuelle Situation der KI in der Hochschulbildung
Die Nutzung von KI-Tools hat in der Hochschulbildung einen festen Platz eingenommen. Eine aktuelle Umfrage zeigt, dass über 63 % der Studierenden in Deutschland KI-Tools wie ChatGPT mindestens einmal während ihres Studiums verwendet haben. Besonders auffällig: 25 % setzen diese Tools regelmäßig oder sehr häufig ein. Dies verdeutlicht, wie stark KI in der Hochschulbildung bereits den Alltag an Universitäten und Hochschulen prägt.
Beliebte Tools und ihre Nutzung:
ChatGPT: Fast die Hälfte der Studierenden (49 %) setzt auf ChatGPT, vor allem für Ideenfindung, das Verfassen von Hausarbeiten und die Bearbeitung komplexer Themen.
DeepL: Etwa 12 % nutzen dieses Tool für präzise Übersetzungen und das Verständnis fremdsprachiger Literatur.
Grammarly: Dieses Tool wird zur Optimierung der Grammatik und Sprache von Texten genutzt und ist besonders beliebt für formale Aufgaben.
Die Einsatzbereiche dieser Tools sind vielfältig: Sie reichen von der Ideenfindung über Datenanalysen bis hin zur Verbesserung von Texten und Übersetzungen. Diese Tools bieten klare Vorteile, indem sie Routineaufgaben vereinfachen und Studierenden helfen, Zeit zu sparen – ein weiterer Beleg für die zunehmende Rolle von KI in der Hochschulbildung.
KI und Bildung: Einblicke in die Zukunft
Erfahren Sie, wie KI unser Lernen revolutioniert und Bildung neu definiert! Sehen Sie sich das spannende Video von ZDFheute an:
Video jetzt ansehen!
3. Die Folgen der KI in der Hochschulbildung für das Studium
Der verstärkte Einsatz von KI im Studium wirft eine wichtige Frage auf: Verlieren Studierende grundlegende Schlüsselkompetenzen, wenn immer mehr Aufgaben automatisiert erledigt werden? Wenn KI zunehmend die Ideenfindung und Problemlösung übernimmt, könnte es zu einem Rückgang des kritischen Denkens, der Selbstständigkeit und der Fähigkeit zum tiefen Lernen kommen. Doch was passiert, wenn Studierende sich zu sehr auf KI in der Hochschulbildung verlassen und die Herausforderung verlieren, selbst komplexe Problemlösungsprozesse zu durchlaufen?
Ein weiteres Risiko besteht darin, dass Studierende ihre Denkprozesse und Entscheidungsfindung immer stärker KI-Systemen überlassen. Diese Abhängigkeit könnte langfristig die Selbstständigkeit und Eigenverantwortung beeinträchtigen, da das Vertrauen in KI dazu führen könnte, dass eigenes analytisches Denken und Lernprozesse in den Hintergrund treten.
Stell dir vor, ein Python-Programmierer kann ohne KI nicht mal die einfachsten Codezeilen schreiben, oder ein Webentwickler ist nicht in der Lage, eine eigene Portfolio-Seite zu erstellen, ohne auf KI zurückzugreifen. Studien zeigen, dass Studierende oft mit hohen Noten durch Kurse kommen, ohne wirklich das tiefere Verständnis des Lernstoffs zu erlangen. Dies wirft eine wichtige Frage auf: Studieren wir wirklich, um Fähigkeiten zu erlernen, die uns in der Arbeitswelt voranbringen? Oder geht es uns am Ende nur darum, den Abschluss zu bekommen, ohne die nötigen praktischen Kompetenzen zu besitzen?
Aber: Kann KI in der Hochschulbildung uns auch produktiver machen?
Der gezielte Einsatz von KI-Tools kann Studierenden helfen, ihre Produktivität zu steigern und gleichzeitig ihre Lernprozesse zu optimieren. Studien zeigen, dass KI insbesondere bei der Recherche und Strukturierung von Lernmaterialien hilfreich sein kann. So ermöglicht etwa ChatGPT eine effiziente Ideensammlung und hilft, komplexe Themen in einfachere Abschnitte zu unterteilen. Das spart nicht nur Zeit, sondern fördert auch das Verständnis und die Retention von Wissen.
Darüber hinaus bieten Übersetzungs-Tools wie DeepL eine schnelle und präzise Möglichkeit, mehrsprachige Quellen zu nutzen, ohne die Qualität der Informationen zu verlieren. Das hilft Studierenden, einen breiteren Zugang zu wissenschaftlichen Arbeiten und Fachliteratur zu erhalten. Grammarly wiederum kann als Rechtschreib- und Grammatikhilfe nicht nur die sprachliche Qualität von Hausarbeiten verbessern, sondern auch Studierenden helfen, sich klarer und präziser auszudrücken.
Eine Studie von JISC und EAB zeigt, dass die Integration von KI-Tools in den Lernalltag zu einer besseren Zeitnutzung führt, da Studierende weniger Zeit mit administrativen oder repetitiven Aufgaben verbringen und sich stärker auf kreative und analytische Aufgaben konzentrieren können. So bietet KI in der Hochschulbildung nicht nur eine Entlastung, sondern fördert auch die Konzentration auf wesentliche Lerninhalte.
Insgesamt lässt sich sagen, dass KI in der Hochschulbildungdas Potenzial hat, Studierenden zu mehr Effizienz und Produktivität zu verhelfen – vorausgesetzt, sie wird verantwortungsvoll und gezielt eingesetzt. Die entscheidende Frage ist: Wie finden wir eine Balance zwischen der Nutzung von KI zur Steigerung der Produktivität und der Förderung eigener Kompetenzen, um sicherzustellen, dass wir nicht nur Abhängigkeiten schaffen, sondern auch Fähigkeiten aufbauen, die uns langfristig weiterbringen?
4. Wie können Hochschulen auf die Integration von KI in der Hochschulbildung reagieren?
Eine der zentralen Herausforderungen für Hochschulen im Umgang mit der zunehmenden Nutzung von KI durch Studierende liegt darin, sowohl Chancen als auch Risiken dieser Technologien zu erkennen und darauf gezielt zu reagieren. Um KI verantwortungsvoll in der Hochschulbildung zu integrieren, könnten Universitäten neue Ansätze entwickeln, die sowohl die Fähigkeiten der Studierenden als auch die Anforderungen des modernen Arbeitsmarktes berücksichtigen.
“AI in Schools: Cheater or Tutor?” von Paul Matthews, präsentiert bei TEDxHobart
Vorschläge zur Anpassung
Ein erster Schritt könnte die Einführung von KI-Literacy-Workshops sein, in denen Studierende lernen, wie sie KI-Tools wie ChatGPT effektiv und kritisch nutzen können. Diese Workshops sollten darauf abzielen, die Funktionsweise, Grenzen und Risiken solcher Technologien zu verdeutlichen, damit Studierende fundierte Entscheidungen treffen können. Darüber hinaus könnten KI-Projekte fest in die Curricula integriert werden, um den Studierenden praktische Fähigkeiten zu vermitteln, wie zum Beispiel das Programmieren von KI-Anwendungen oder die Nutzung von KI in der Datenanalyse.
Auch die Lehrenden könnten stärker unterstützt werden. KI-gestützte Lehrmethoden könnten helfen, repetitive Aufgaben wie das Korrigieren von Hausarbeiten zu automatisieren, während mehr Zeit für direkte Interaktion mit den Studierenden bleibt. Interaktive Lernplattformen, die auf KI basieren, könnten zudem eingesetzt werden, um individuelle Lernwege zu fördern.
Anpassungen in der Hochschulpolitik zur Förderung von KI in der Hochschulbildung
Ein weiterer wichtiger Ansatzpunkt ist die Anpassung der Richtlinien zur Nutzung von KI in der Hochschulbildung. Universitäten sollten klare Leitlinien entwickeln, die festlegen, in welchen Kontexten KI-Tools erlaubt sind und wann deren Nutzung als Verstoß gegen akademische Integrität gilt. Gleichzeitig könnte von den Studierenden verlangt werden, die Nutzung von KI in ihren Arbeiten transparent offenzulegen.
Um dem Risiko von Plagiaten entgegenzuwirken, könnten neue Tools eingeführt werden, die KI-generierte Inhalte identifizieren können. Für Programmieraufgaben könnten spezielle Analyseprogramme eingesetzt werden, die zeigen, wann und wie Tools wie GitHub Copilot oder ChatGPT verwendet wurden. Dies würde nicht nur den Missbrauch von KI eindämmen, sondern auch eine gezielte Nachverfolgung der Lernfortschritte ermöglichen.
Neue Prüfungsformen
Schließlich sollten auch die Prüfungsformate überdacht werden. Praktische Prüfungen, die persönliche und praxisnahe Fähigkeiten betonen, könnten sicherstellen, dass Studierende den Stoff wirklich beherrschen. Gleichzeitig könnten offene Aufgabenstellungen, bei denen der Einsatz von KI erlaubt ist, die Reflexionsfähigkeit fördern. Studierende könnten aufgefordert werden, detailliert zu dokumentieren, wie sie KI eingesetzt haben und warum sie diese Ansätze gewählt haben.
Durch diese Maßnahmen könnten Hochschulen eine Balance zwischen der Nutzung von KI in der Hochschulbildung und der Förderung eigenständiger Kompetenzen schaffen, sodass Studierende bestmöglich auf eine zunehmend digitalisierte Arbeitswelt vorbereitet werden.
5. Fazit: KI in der Hochschulbildung zeigt, dass Abschlüsse allein nicht mehr ausreichen – die Art und Weise, wie wir lernen, muss sich anpassen.
Die zunehmende Integration von KI in Bildungsprozesse stellt uns vor die Herausforderung, unser Verständnis von Lernen neu zu definieren. Während KI das Potenzial hat, Studierende produktiver und effizienter zu machen, darf dies nicht auf Kosten grundlegender Kompetenzen wie kritischem Denken, Kreativität und Selbstständigkeit geschehen.
Ein reiner Fokus auf Abschlüsse ohne die dahinterliegenden Fähigkeiten ist in einer sich schnell wandelnden Arbeitswelt nicht mehr ausreichend. ielmehr müssen sowohl Studierende als auch Hochschulen den bewussten und reflektierten Einsatz von KI in der Hochschulbildung im Lernalltag integrieren. Hochschulen tragen dabei eine besondere Verantwortung, die Studierenden nicht nur mit theoretischem Wissen, sondern auch mit den praktischen Werkzeugen auszustatten, um in einer KI-getriebenen Welt erfolgreich zu sein.
Abschließend bleibt zu sagen: Lernen bedeutet mehr als nur Wissen anzusammeln – es geht darum, dieses Wissen aktiv anwenden zu können. Nur durch eine bewusste Kombination von Technologie und menschlichen Fähigkeiten kann eine zukunftsfähige Bildung gewährleistet werden.
Was denkt ihr über die Nutzung von KI in der Hochschulbildung? Teile gerne eure Meinung in den Kommentaren! 🚀
Ach ja, btw: KI hat bei der Erstellung dieses Beitrags mitgeholfen. ☺️
JISC & EAB. (n.d.). Study on AI integration in educational practices. Insights from their research were referenced conceptually regarding productivity and focus improvements through AI tools in education. Retrieved November 24, 2024, from
https://www.jisc.ac.uk
Der Begriff „Dritter Ort“ wurde von Ray Oldenburg geprägt und beschreibt Orte, die als Ausgleich zu Familie und Beruf dienen. Aus einer amerikanischen Perspektive schaut Oldenburg sehnsüchtig nach Europa – Hier gibt es Pubs, Kaffeehäuser und Biergärten. Aber was ist eigentlich mit Bibliotheken?
The wonder is that so little attention has been paid to the benefits attaching to the third place. It is curious that its features and inner workings have remained virtually undescribed in this present age when they are so sorely needed and when any number of lesser substitutes are described in tiresome detail. Volumes are written on sensitivity and encounter groups, on meditation and exotic rituals for attaining states of relaxation and transcendence, on jogging and massaging. But the third place, the people’s own remedy for stress, loneliness, and alienation, seems easy to ignore.
– Ray Oldenburg, the great good place
Was sind Dritte Orte?
Um die Frage zu beantworten, ist es zunächst wichtig, die Eigenschaften des ersten und zweiten Ortes zu definieren. Der erste Ort beschreibt das Zuhause – ein persönlicher Rückzugsort, in dem die engsten Beziehungen gepflegt werden. Es handelt sich dabei um einen informellen Raum, der zugleich Schutz und Geborgenheit bietet, jedoch auch isolierend wirken kann. Der zweite Ort hingegen steht für das berufliche oder akademische Umfeld. Dieser Raum ist geprägt von Produktivität, Verantwortung und klaren Strukturen. Hier zählt weniger die individuelle Persönlichkeit als vielmehr die Erfüllung von Pflichten und die eigene Leistungsfähigkeit. Dritte Orte unterscheiden sich grundlegend von diesen beiden: Dritte Orte sind Räume der Gemeinschaft, in dem Menschen ungezwungen zusammenkommen können. Gesellschaftliche Merkmale wie Status oder Herkunft spielen hier keine Rolle und werden symbolisch an der Eingangstür abgelegt – ähnlich wie ein Mantel an der Garderobe eines Theaters oder Clubs. Diese neutrale Atmosphäre schafft die Grundlage für ein soziales Miteinander, das frei von äußeren Zuschreibungen ist.
Dritte Orte und ihr Hintergrund
Während meines Studiums bin ich auf das Konzept der „Dritten Orte“ gestoßen und war sofort fasziniert von ihrer Bedeutung für unsere Gesellschaft. Besonders Bibliotheken als dritte Orte haben mich angesprochen, da sie nicht nur Räume des Wissens, sondern auch der Begegnung und des Austauschs sind. In einer Zeit, in der Technologienutzung oft den direkten Kontakt mit Menschen ersetzt, halte ich solche Orte für unverzichtbar. Sie bieten die Möglichkeit, echte Gemeinschaft zu erleben und fördern das persönliche Wachstum, das nur durch zwischenmenschliche Interaktionen entstehen kann. Das Konzept der dritten Orte geht auf Ray Oldenburg (7. April 1932 – 21. November 2022) zurück. Oldenburg war ein amerikanischer Soziologe, der die Bedeutung informeller öffentlicher Treffpunkte für eine funktionierende Zivilgesellschaft, Demokratie und bürgerschaftliches Engagement betonte. Er prägte den Begriff des „Third Place“ (Dritter Ort) und schrieb das Buch The Great Good Place, das 1989 von der New York Times Book Review als Editor’s Choice ausgezeichnet wurde. 2001 veröffentlichte er zudem Celebrating The Third Place, das die Rolle und Bedeutung dritter Orte weiter vertieft.
Warum eignen sich gerade Bibliotheken als Dritte Orte?
Um dies genauer zu beleuchten, habe ich mir fachnahe Unterstützung geholt. Ich hatte die Gelegenheit, mit Herrn Michael Stünkel, dem Leiter der Zentralbibliothek Hannover, zu sprechen. Herr Stünkel arbeitet seit 1999 in der Stadtbibliothek Hannover und konnte gute Einblicke in die Transformation der öffentlichen Bibliotheken zu einem „Dritten Ort“ geben. Möchtest du das Interview lesen oder erstmal herausfinden, was dein Dritter Ort ist?
Betritt man die Zentralbibliothek Hannover, sieht man hier und da Menschen, die Zeitung lesen und Kaffee trinken. Man hört die Schüler, die ihre Hausaufgaben erledigen. All das erstreckt sich über fünf Etagen, die durch eine innenliegende Treppe miteinander verbunden sind. Die Zentralbibliothek Hannover ist offen und lebendig.
Bibliotheken umzugestalten bzw. anders zu führen bringt mehr Arbeit mit sich – das Büro von Herrn Stünkel ist chaotisch. Bücher und Papier stapeln sich. Das war nicht immer so, sagt Stünkel. Wandel heißt Arbeit.
Interview mit Michael Stünkel, Leiter der Zentralbibliothek Hannover
Smilla Kolbe (SK): Welche Funktion erfüllt Ihre Bibliothek für die Gemeinschaft abseits des klassischen Lesens und der Medienausleihe?
Michael Stünkel (MS): Ja, Klassisch ist [es] schon fast, ein „Dritter Ort“ zu sein. Ein Treffpunkt zu sein, Austausch zu haben untereinander. Manchmal auch allein in Gemeinschaft sein, also wir beobachten hier viele Menschen die hier einzeln sitzen, aber es genießen, das rundherum auch Menschen einzeln sitzen und so kommt man ins Gespräch. Also der Ort des Treffpunkts, auch der Auseinandersetzung. Es gibt hier viele Veranstaltungsformate, wo diskutiert wird – kontrovers diskutiert wird. [Diese Veranstaltungen] kann man konsumieren, man kann aber auch mitmachen.
SK: Was sind das für Veranstaltungen?
MS: Wir machen zu bestimmten Themen Diskussionsveranstaltungen. Literarische Lesungen eher weniger, weil das in Hannover anders abgedeckt ist. Zum Beispiel zum Tag der Demokratie oder zum Tag der Bibliotheken. Wir hatten jetzt das Queere Wohnzimmer für vier Monate mit Workshops Lesungen, Diskussionen und Beratungsterminen rund um das Thema in unserem Haus.
SK: Was bedeuten Dritte Orte für Sie im Zusammenhang mit Bibliotheken? Wahrscheinlich genau das, oder?
MS: Genau das. Der klassische Ort zwischen Zuhause und Arbeit. Nicht kommerziell, ohne Verzehrzwang, niederschwellig zu benutzen, gute Öffnungszeiten [lacht]. Das ist auch ein Punkt, an dem wir weiter arbeiten. Wir haben jetzt die Öffnungszeiten Anfang des Jahres von 11 Uhr bis 19 Uhr auf 9 Uhr bis 19 Uhr erweitert.
SK: Wie werden die neuen Öffnungszeiten angenommen?
MS: Die werden sehr gut angenommen. Ganz schnell ging das. Wir haben im Januar angefangen, in der Hoffnung, ein bisschen zu üben, bis die Leute das alle mitbekommen haben, dass sie früher kommen können. Es waren aber relativ schnell sehr gute Zahlen.
SK: Schön, dass das so gut funktioniert. Ich hab mir ein paar Interviews mit anderen Bibliothekaren, die von Bibliotheken nicht als Orte, sondern als Konzepte gesprochen haben, angesehen. Also insofern, dass die Räumlichkeiten geboten durch die Bibliothek werden und dann die Gemeinschaft etwas eigenes draus macht. Würden Sie dieser Aussage zustimmen? Trifft das auf die Stadtbibliothek Hannover zu?
MS: Ja, da sind wir gerade dabei. Wir haben zum Beispiel das Repair-Café. [Das] ist etwas, was auf uns zugekommen ist und von Ehrenamtlichen, insbesondere von einer Person, [betrieben wird]. Das bedeutete eine gewisse Anlaufzeit und inzwischen läuft es vollkommen ohne uns. Ein wenig organisatorische Arbeit durch den Hausdienst, aber nachdem wir Versicherungsfragen, Datenschutz und solche Sachen geklärt hatten, organisiert sich das selber. [Die Veranstalter des Repair-Café] sind einmal im Monat hier. Das versuchen wir mit anderen Konzepten auch umzusetzen. Zum Beispiel die Methothek, kein ganz schönes Wort [lacht], aber gemeint ist damit, dass Menschen die etwas können zum Thema Coaching, Kommunikationstraining, Selbstoptimierung im positiven Sinne, Bewerbungsgespräche vorbereiten,… andere Menschen bei ihrem Vorhaben unterstützen. Diese Personen kommen zu einem bestimmten Tag und machen eine Coffee-Lecture, also kleine Vorträge, aber auch mit Beteiligung der Teilnehmer. Da wünschen wir uns auch, dass sich das mehr verselbstständigt. Wir organisieren das bisher, wir akquirieren auch die Vortragenden, aber es sieht so aus, als würde das auch eine Eigendynamik bekommen, sodass das Bibliotheksbenutzer für Bibliotheksbenutzer dann anbieten.
SK: Also selbstverwaltet dann quasi.
MS: Ja genau. Und da gibt es mehrere Sachen, die auf diese Schiene gestellt werden sollen.
SK: Interessant. Man braucht ein hohes Vertrauen in die Leute, dass das alles so funktioniert, oder?
MS: Ja, unbedingt. Daran muss man auch bei den Kollegen etwas arbeiten. Aber das ist relativ schnell aufgebaut, dieses Vertrauen, wenn sich bewahrheitet, dass nichts passiert. Also, alle wollen ja was Gutes.
SK: Sie meinten im Vorgespräch bereits, dass hier nicht alles neu gebaut werden kann, aber auch, dass sie sich Räume schaffen wollen, sodass die Zentralbibliothek Hannover zu einem „Dritten Ort“ wird. Haben Sie sich da bestimmte Kriterien bei der räumlichen Gestaltung aufgestellt um eine einladende Atmosphäre zu schaffen?
MS: Mehrere Kriterien. Durch die Haushaltssituation, oder überhaupt auch durch nachhaltiges Handeln, was auch zu unseren Leitthemen gehört, haben wir nicht neu gekauft, sondern „upgecycelt“, also vorhandenes Material umgebaut, weiter verwendet. Aber sehr radikal, also man sieht nicht unbedingt, dass das Regalsystem aus den 70er Jahren stammt, sondern es ist so neu gestaltet, dass es gut in die Zeit passt. Dann haben wir festgestellt, dass wir wenig, viel viel weniger Bestand brauchen, als wir oder auch viele andere gedacht haben. Wir haben nach festen bibliothekarischen Kriterien ganz viel Medien ausgesondert und dann Platz geschaffen [für eine einladende Atmosphäre]. Anstatt Bücherregale haben wir jetzt freie Flächen. Wir haben viele Einzelarbeitsplätze und Lernzonen geschaffen. [Wir] sind jetzt dabei, auch diese zu möblieren, Steckdosen nachzurüsten. Das ist in jeder Bibliothek, die nicht aus diesem Jahrzehnt stammt, immer eine offene Stelle, weil man hat damals nicht mit Steckdosen geplant.
SK: Warum auch.
MS: Ja, warum auch. Aber es ist ein großes Thema auch für die Kunden hier. Zusätzlich haben wir in einem Partizipationsprozess einerseits intern mit unseren Mitarbeitern aber auch extern mit (Nicht-)Nutzern eine Zukunftswerkstatt durchgeführt. Üblich mit Kritikphase, Utopiephase und abschließender Realisierungsphase. Außerhalb des Hauses auch. Da sollten die Teilnehmer sich die Bibliothek der Zukunft vorstellen. [Es gab] bestimmte Methoden. Einmal mit Lego Serious Play oder auch mit Mood-Boards. Jedenfalls extern moderiert, nicht, dass wir als Korrektur dabei waren. Die Ergebnisse der Zukunftswerkstatt sind auch Kriterien für uns. Wir versuchen, die Vorstellung einer Bibliothek der Zukunft unserer Mitarbeiter, aber auch der Kunden und Nicht-Kunden, umzusetzen.
SK: Das fließt also auch in die Überlegung [der Gestaltung] mit ein?
MS: Ja, das war sogar auch oft Rechtfertigung oder Auslöser für bestimmte Sachen, die wir gemacht haben.
SK: Das ist ist sehr schön. Wie kommt die Gestaltung der Bibliothek bei den Nutzern an?
MS: Also einmal sieht man, dass das Haus voll ist. So verkehrt kann es also nicht gewesen sein [lacht]. Es gibt viel positive Resonanz zur Reduzierung der Medien, einerseits, natürlich gibt es aber da auch große Kritik.
SK: Ja?
MS: Also, das Aussondern von Büchern ist für manche Menschen einfach ein Tabu. Und das muss man natürlich auch aushalten. Und es ist auch kein demokratischer Abstimmungsprozess. Wer sich positiv oder negativ äußert, das ist nicht in Zahlen zu messen, sondern es sind nur die Menschen, die sich eben äußern. Was daraus resultiert ist, dass man merkt, wie positiv es angenommen wird, dass wir Veranstaltungen machen, die auch in der Öffnungszeit schon beginnen. Das haben wir früher nicht gemacht. Wir haben immer erst geschlossen und dann um 19.30 Uhr was angefangen. Das war personell aufwendig und außerdem war es auch für die Kunden oder die Besucher gar nicht so optimal. Jetzt bleiben sie zum Teil hier, kriegen mit, um 17 Uhr beginnt hier irgendwas, beteiligen sich sogar. Also, das hat einen echten Mehrwert und das spricht auch dafür, dass die Kunden das gut finden. Also es gibt eine positive Resonanz. Es gibt immer Einzelne, die sagen „Ich möchte hier meine Ruhe haben.“, aber auch dafür haben wir einen Raum geschaffen. Der zwar auch manchmal sehr gut gefüllt ist und dann wird es da doch lauter, aber wir sind immer noch dabei, die Zonen ein bisschen schärfer zu definieren.
SK: Gibt es Maßnahmen, um genau diese Balance zu halten, zwischen einem ruhigen Ort und einem belebten Ort?
MS: Das ist bei uns einfacher als in anderen Bibliotheken, weil wir gestapelt sind. Wir haben fünf Etagen. Andere Bibliotheken haben es eher in der Fläche und da ist es schwierig. Hier kann man schon die Etage ein bisschen anders definieren. Also im fünften Stock hinter dem Aufzug, das ist eine wunderschöne Ecke, da haben wir die Methothek angesiedelt. Die sind da für sich sozusagen. Dann gibt es Arbeitsräume mit Einzeltischen und Arbeitsräume mit Gruppenmöglichkeit. Das Untergeschoss, da sind wir jetzt dabei, da ist es auch noch mal stiller. [Dort] wollen wir Arbeitsplätze einrichten, aber eben auch ein bisschen gemütlichere, also keine Büroarbeitsplätze und nur Tisch und Stuhl, sondern auch mit ein bisschen Atmosphäre.
SK: Ich war schon einige Zeit vor unserem Termin da und habe so ein bisschen beobachtet, wer hier so reingeht, das scheint mir eine bunte Mischung zu sein. Gibt es dennoch eine Personengruppe, die die Bibliothek am häufigsten nutzt? Oder ist das schwer zu sagen?
MS: Das ist ein bisschen saisonabhängig, also die Sekundarstufe 2, die Schüler die Facharbeiten schreiben und vor dem Abitur stehen, das ist eine große Gruppe, die auch unheimlich fleißig ist [lacht]. Das ist aber nur eine Gruppe; es gibt viele mittelalte Erwachsene, die sich hier aufhalten. Es gibt auch trotzdem noch die typischen Romanleser…
SK: Sind noch nicht ausgestorben?
MS: Nee [lacht], die bedürfen auch einer besonderen Pflege, weil da ist der Inhalt eben nicht so objektivierbar, wie es jetzt gerade im Trend ist. Bei BWL braucht man das, bei Technik und EDV das… [Bei Romanen] muss schon ein fachlicher Input von uns kommen. Menschen in Ausbildung, Deutschlernende, ganz viel. Und Menschen, die einfach miteinander sprechen wollen, das sieht man auch. Erfassen kann man das schlecht. Da müsste man ja wirklich gucken, für wen hält man jemanden. Ist das ein Schüler oder ist das ein Auszubildender. Lernt [die Person] Deutsch oder ist sie schon viele Jahre hier und liest einfach irgendeine Fachzeitschrift? Also das ist schwierig.
SK: Gab es trotzdem Veränderungen im Laufe der Jahre von den Besuchern oder war das ähnlich, wie sie es jetzt beschrieben haben?
MS: Also diese Tendenz, dass junge Leute hier sind, die ist gestiegen. Das kann man sagen, ja. Leute mit einer höheren Lärmtoleranz auch. Das ist schon richtig trubelig hier. Da sagen manche – ich bin ja auch schon lange hier – viele ältere Kunden, das ihnen das hier jetzt oft auch zu laut ist. Nicht, weil es undiszipliniert laut ist, [es sind] einfach viele Menschen, die sich unterhalten. Das erhöht den Lärmpegel und das möchten manche nicht, aber das ist, glaube ich, die Minderheit.
SK: Dann bietet es sich mit den Etagen ja tatsächlich an, dass man diese thematisch gestaltet.
MS: Ja, wobei man trotzdem sagen muss, wir haben ja den großen Innenhof und alles ist offen, so [geschlossen] sind die Etagen dann doch nicht, aber es ist zumindest ein Angebot.
SK: Wie spricht die Stadtbibliothek Hannover Menschen an, die normalerweise wenig Zugang zu kulturellen oder sozialen Räumen haben?
MS: Also wir gehen zunehmend auch raus aus dem Haus. Kennen Sie das Aufhof-Projekt?
SK: Ja.
MS: Da waren wir auch, mit mäßigem Erfolg, aber wir waren da und das ist erstmal schon richtig [lacht]. Dann sind wir bei den Smart City Days dabei, bei jugendlichen Technikfreaks sozusagen [lacht], mit Robotik gehen wir um. Wir haben Anfang nächsten Jahres, Mitte nächsten Jahres, eine Technothek. Ganz kultur- und bildungsferne Menschen kriegen wir nur durch Kindergärten [und] Schulen oder durch andere Vermittler. Die Technothek soll eher die MINT-Fächer propagieren.
SK: Also Sie gehen dann auch aktiv in Schulen und Kindergärten?
MS: Ja, das ist aber schon lange Standard.
SK: Das ist dann nochmal niederschwelliger, oder?
MS: Ja. Und die Zielgruppen, auf die muss man eben oft zugehen. Man muss nicht um die Aufmerksamkeit betteln, sondern man muss sich einfach nur zeigen. Das ist ja oft das Problem, dass man nicht bekannt genug ist und wenn es dann bekannt wird, ist großes Erstaunen da.
SK: Welche Herausforderungen bestehen denn bei der Etablierung der Bibliothek als Dritter Ort? Bezogen auf Ressourcen, Personal,… Wie ist da Ihre Einschätzung?
MS: Also Herausforderungen gibt es zum Teil an die Mitarbeiter, weil auch ein anderes Publikum kommt. Es kann Konflikte geben, weil die Auffassung, wie man sich in einer Bibliothek verhält, eben doch verschieden sein können. Ich will das aber gar nicht so betonen, weil das für mich erstens nicht so eklatant ist und zweitens nicht so viel ist. [Es ist] kein Grund, sich von dem Konzept der Bibliothek als sozialer Raum wieder abzuwenden, aber man muss es natürlich sehen. Das Thema Wohnungslosigkeit haben wir schon immer gehabt, damit muss man umgehen. Die kümmert es aber nicht, ob wir als Dritte Orte definieren oder nicht. Wenn es hier warm und trocken ist und draußen nass und kalt, dann kommen sie natürlich und sollen auch kommen, das ist völlig in Ordnung. Herausforderung sonst ist, dass es ein anderes Arbeiten ist. Also die klassische Auskunft zum Beispiel. Da kommt jemand und möchte wissen, wo steht welches Buch, das ist nicht mehr die Hauptarbeit.
SK: Sondern?
MS: Die meisten kommen dann mit ihrem Handy und sagen, ich hab das Buch recherchiert und brauchen nur einen Hinweis, wo das jetzt ist. Das geht aber auch mit einer Ausschilderung. Es ist eher, dass man auch diese ganzen Begegnungen etwas moderiert, die hier stattfinden. Sehr viel Komplikationen und extrovertierteres Verhalten als früher vielleicht [lacht]. Aber auch nicht zu viel Regeln. Man muss schon auch als Mitarbeiter, der hier im Hause arbeitet, zulassen können, dass zum Beispiel die Möbel flexibel genutzt werden.
SK: Dann habe ich noch eine Frage zur Digitalisierung. Inwiefern werden Bibliotheken als Dritte Orte durch aktuelle Entwicklungen wie Digitalisierung und veränderte Lesekulturen beeinflusst?
MS: Also es ist schon so, dass die Leute die Begegnung suchen, auch wenn sie das herkömmliche Bibliothekserleben nicht so haben, sondern ein anderes. Wir haben hier mehrere Personen, die um 9 Uhr kommen, mit ihrer Tasche und ihrem Laptop, und dann bis 14 Uhr hier sitzen, zwischendurch Kaffee trinken gehen, offenbar hier arbeiten. Also die nutzen den digitalen Raum, ein gutes WLAN, also eine relativ ideale Arbeitsatmosphäre. Man ist nicht allein und muss sich selber auch irgendwie disziplinieren. Aber Digitalisierung meinen Sie jetzt nicht [insofern als dass] wir die Medien digital zur Verfügung stellen?
SK: Vielleicht ist das auch eher eine persönliche Frage. Durch Social Media ist es schwerer, die Verbindung zu anderen Leuten aufrecht zu erhalten. Man lebt quasi halb im Internet. [In dem Rahmen interessiert es mich], ob die Bibliothek ein Raum sein kann, um die Gemeinschaft zu fördern.
MS: Die persönliche, dann?
SK: Ja, genau.
MS: Ja das könnte ich so bestätigen. Wir merken das zum Beispiel im Queeren Wohnzimmer. [Dort] hatten wir mehrere Lesungen mit hauptsächlich jungen Autoren, die offenbar eine Szene bedienen. Da kommen die Leute aus Oldenburg mit ihren Eltern, weil sie diese Person lesen/sehen/hören wollen und andere treffen [wollen], die [den Autor] auch toll finden. Also das Phänomen, Lesen, Vorlesen, Lesungen, ist schon dann auch wieder im Plus und im Fluß.
SK: Werden Bibliotheken auch in Zukunft noch relevant sein?
MS: Wenn sie so weitermachen, wie wir, ja [lacht]. Also das ist glaube ich der springende Punkt. Wenn sie sich an den Bedürfnisse der Bevölkerung orientieren, ohne das Erbe, oder banal gesagt, das Buch, aufzugeben. Das ist ja kein entweder oder sondern es ist beides. Und es gibt Phasen, da hat der Bestand das Vorrecht gehabt und dann kommt die Welle: jetzt hat der Raum das Vorrecht und es wird sich irgendwie einpendeln zu einem bestimmten Maß.
SK: Das ist eine schöne Zukunftsaussicht. Abschlißende Frage. Welche neuen Projekte oder Ideen gibt es, um die Stadtbibliothek Hannover als Treffpunkt und sozialen Ort noch stärker zu etablieren?
MS: Wir hatten zwei Jahre lang einen Raum unten, das war ein Garderobenraum, mit hässlichen Schränken [lacht], den haben wir leer geräumt und zum Experimentierraum gemacht und haben [diesen Raum] verschiedenen Akteuren zur Verfügung gestellt. Jeweils vier Monate. Da gab es einmal das Thema Job und Karriere. Da war das Jobcenter dabei und die Sparkasse hat den Jugendlichen erzählt, wie man ein Konto eröffnet, mit Geld umgeht. Das andere war die Artothek. Kennen Sie die?
SK: Ja, die kenne ich.
MS: Die war hier für vier Monate und hat den Raum völlig anders umgestaltet und hat hier eine ganz andere Atmosphäre reingebracht. [Danach hat die Artothek] eine andere Unterkunft bekommen und wir hatten dann wieder ein neues Projekt. Das wollen wir noch ein bisschen weitermachen, dass einfach die Menschen hierherkommen können und was machen können. Das wollen wir ausbauen. Die Projekte, die wir angefangen haben sind auch noch am laufen, es ist noch nicht zu Ende. Was unten im Experimentierraum startet, soll verstetigt werden. Die Methothek, startete auch im Experimentierraum und hat jetzt einen Ort bekommen. Genauso das Queere Wohnzimmer. Die Veranstaltungsreihe ist vorbei, aber für die Community sind wir weiter als Ort da, den sie eigenständig bespielen können. Das wird ein ideeller Ort werden, also das ist… wir haben so ein quietschbuntes Sofa aus dem Schauspielhaus. Haben Sie das gesehen?
SK: Ja.
MS: [lacht] Ja, das ist ne Leihgabe, das Wohnzimmer ist jetzt auch aufgelöst. Aber wir haben gesagt, von der Idee zum Ort. Nee, umgekehrt. Vom Ort zur Idee. Also die Idee bleibt erhalten, so als Haltung oder als Statement oder als Raum für Aktion.
Fazit
Durch das Interview mit Michael Stünkel über Bibliotheken als Dritte Orte konnte ich wertvolle Einblicke gewinnen und besser verstehen, wie Bibliotheken der Zukunft den sozialen Aspekt in den Mittelpunkt stellen, um Gemeinschaft zu fördern. Besonders faszinierend ist, dass Bibliotheken ein besonders niedrigschwelliges Angebot schaffen, um als Dritte Orte zu fungieren. Man muss kein konkretes Ziel haben, um eine Bibliothek zu besuchen: Vielleicht schaut man sich einfach die Neuzugänge an, liest die Zeitung oder bringt Bücher zurück – und entdeckt plötzlich eine Veranstaltung, die einen zum Bleiben einlädt. Diese Ungezwungenheit ermöglicht es, soziale Teilhabe ohne die Verpflichtung zu erleben, gezielt an einem Angebot teilnehmen zu müssen. Dabei wurde deutlich, dass dieser Ansatz zwar nicht alle Bedürfnisse gleichermaßen erfüllen kann, jedoch essenziell für die Weiterentwicklung moderner Bibliotheken ist. Es ist ein Thema, das sich kontinuierlich wandelt und weiterentwickelt – eine Dynamik, die besonders spannend und bedeutsam bleibt. Weißt du, was dein Dritter Ort ist? Mache das Quiz und finde es heraus!
Durch den kontinuierlichen und raschen Fortschritt in jüngster Zeit auf den Gebieten von Big Data und KI-Technologien sind heutzutage insbesondere Teilbereiche des Informationsmanagements gefragter als je zuvor. Die Rolle des Informationsmanagers und Data Scientists besteht darin, Methoden zur Erfassung und Verarbeitung von Informationen aus unterschiedlichen Datenquellen anzuwenden. Zudem ist er befähigt, Entscheidungen darüber zu treffen, welche Verarbeitungsprozesse zur gezielten Knowledge Discovery aus umfangreichen Datensätzen geeignet sind. Hierbei kommt Data Mining ins Spiel, eine Methode, die die systematische Extraktion relevanter Informationen und Erkenntnisse aus großen Datenmengen umfasst.
In diesem Blogbeitrag werden wir tiefer in das Thema eintauchen und uns einem von vielen Verfahren des Data Mining, genauer der Sentimentanalyse im Text Mining, praxisnah annähern. Dabei bin ich der Ansicht, dass ein tieferes Verständnis erreicht wird, wenn das theoretisch Gelernte eigenständig umgesetzt werden kann, anstatt lediglich neue Buzzwörter kennenzulernen. Ziel ist eine Sentimentanalyse zu Beiträgen auf der Social Media Plattform X (ehemals Twitter) mit Verfahren aus dem Machine Learning bzw. einem passenden Modell aus Hugging Face umzusetzen.
Ihr könnt euch in die Hintergründe einlesen oder direkt zum Coden überspringen.
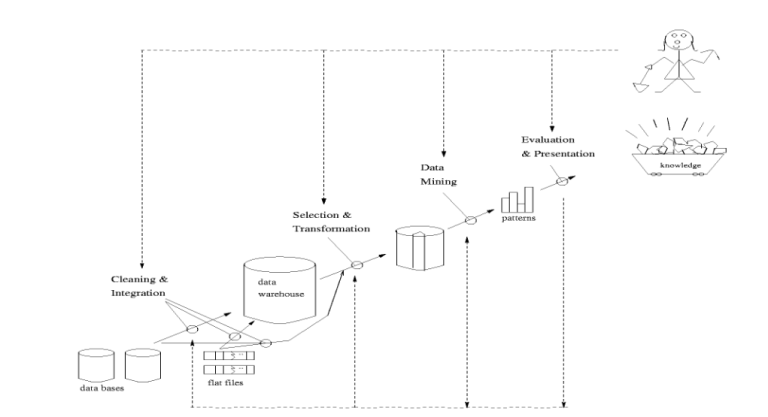
Data Mining umfasst die Extraktion von relevanten Informationen und Erkenntnissen aus umfangreichen Datensammlungen. Ähnlich wird auch der Begriff „Knowledge Discovery in Databases“ (KDD) verwendet. Die Hauptaufgabe besteht darin, Verhaltensmuster und Prognosen aus den Daten zu identifizieren, um darauf basierend Trends zu erkennen und angemessen darauf zu reagieren. Dieser analytische Prozess des Data Mining erfolgt mithilfe von computergestützten Methoden, deren Wurzeln in den Bereichen Mathematik, Informatik und insbesondere Statistik liegen. Data Mining kann als Teilprozess innerhalb des umfassenden Datenanalyseprozesses verstanden werden, der folgendermaßen strukturiert ist:
Datenselektion (Auswahl relevanter Daten aus einer Datenbank)
Datentransformation (Aufbereitung/Konsolidierung der Daten in eine für das Data Mining passende Form)
Data Mining (Prozess gestützt von intelligenten Methoden zum Extrahieren von Daten-/Verhaltensmustern)
Pattern Evaluation (Identifikation interessanter Muster und Messwerte)
Knowledge Presentation (Präsentieren von mined knowledge durch Visualisierung und andere Repräsenationstechniken)
Data Mining als Teilprozess der Knowledge Discovery / Jiawei Han, Data Mining: Concepts and Techniques (2006)
Die Data Mining Verfahren dienen dazu, den Datenbestand zu beschreiben und zukünftige Entwicklungen vorherzusagen. Hierbei kommen Klassifikations- und Regressionsmethoden aus dem statistischen Bereich zum Einsatz. Zuvor ist es jedoch notwendig, die Zielvariable festzulegen, die Daten aufzubereiten und Modelle zu erstellen. Die gebräuchlichen Methoden ermöglichen die Analyse spezifischer Kriterien wie Ausreißer- und Clusteranalyse, die Verallgemeinerung von Datensätzen, die Klassifizierung von Daten und die Untersuchung von Datenabhängigkeiten.
Zusätzlich zu den herkömmlichen statistischen Methoden können auch Deep Learning-Algorithmen verwendet werden. Hierbei werden Modelle aus dem Bereich des Machine Learning unter Anwendung von überwachtem (bei gelabelten Daten) oder unüberwachtem (bei nicht gelabelten Daten) Lernen eingesetzt, um die Zielvariablen möglichst präzise vorherzusagen. Eine wesentliche Voraussetzung für das Vorhersagemodell ist ein Trainingsdatensatz mit bereits definierten Zielvariablen, auf den das Modell anschließend trainiert wird.
ML-Based Text Mining 🤖
Ein Teilbereich des Data Mining, der auch maßgeblich maschinelles Lernen einbezieht, ist das Text Mining. Hierbei zielt das Text Mining darauf ab, unstrukturierte Daten aus Texten, wie beispielsweise in sozialen Netzwerken veröffentlichte Inhalte, Kundenbewertungen auf Online-Marktplätzen oder lokal gespeicherte Textdateien, in strukturierte Daten umzuwandeln. Für das Text Mining dienen oft Datenquellen, die nicht direkt zugänglich sind, weshalb Daten über APIs oder Web-Scraping beschafft werden. Im darauf folgenden Schritt werden Merkmale (Features) gebildet und die Daten vorverarbeitet. Hierbei erfolgt die Analyse der Texte mithilfe von natürlicher Sprachverarbeitung (Natural Language Processing – NLP) unter Berücksichtigung von Eigenschaften wie Wortfrequenz, Satzlänge und Sprache.
Maschinelles Lernen für Datenvorverarbeitung
Die Vorverarbeitung der Daten wird durch Techniken des maschinellen Lernens ermöglicht, zu denen Folgendes gehört:
Tokenisierung: Hierbei werden die Texte in kleinere Einheiten wie Wörter oder Satzteile, sogenannte Tokens, aufgespalten. Das erleichtert die spätere Analyse und Verarbeitung.
Stoppwortentfernung: Häufige Wörter wie „und“, „oder“ oder „aber“, die wenig spezifische Informationen liefern, werden entfernt, um die Datenmenge zu reduzieren und die Analyse effizienter zu gestalten.
Wortstamm- oder Lemmatisierung: Die Formen von Wörtern werden auf ihre Grundformen zurückgeführt, um verschiedene Variationen eines Wortes zu einer einzigen Form zu konsolidieren. Zum Beispiel werden „läuft“, „lief“ und „gelaufen“ auf „laufen“ reduziert.
Entfernen von Sonderzeichen und Zahlen: Nicht-textuelle Zeichen wie Satzzeichen, Symbole und Zahlen können entfernt werden, um die Texte auf die reinen sprachlichen Elemente zu fokussieren.
Niedrige Frequenzfilterung: Seltene Wörter, die in vielen Texten nur selten vorkommen, können entfernt werden, um Rauschen zu reduzieren und die Analyse zu verbessern.
Wortvektorenbildung: Durch Techniken wie Word Embeddings können Wörter in numerische Vektoren umgewandelt werden, wodurch maschinelles Lernen und Analyseverfahren angewendet werden können.
Named Entity Recognition (NER): Diese Technik identifiziert in Texten genannte Entitäten wie Personen, Orte und Organisationen, was zur Identifizierung wichtiger Informationen beiträgt.
Sentimentanalyse: Diese Methode bewertet den emotionalen Ton eines Textes, indem sie versucht, positive, negative oder neutrale Stimmungen zu erkennen.
Textklassifikation: Mithilfe von Trainingsdaten werden Algorithmen trainiert, um Texte automatisch in vordefinierte Kategorien oder Klassen einzuteilen.
Topic Modeling: Diese Methode extrahiert automatisch Themen aus Texten, indem sie gemeinsame Wörter und Konzepte gruppiert.
Insgesamt kann der Text Mining-Prozess als Teil einer breiteren Datenanalyse oder Wissensentdeckung verstanden werden, bei dem die vorverarbeiteten Textdaten als Ausgangspunkt für weitere Schritte dienen.
The effort of using machines to mimic the human mind has always struck me as rather silly. I would rather use them to mimic something better.
In unserem nächsten Abschnitt werden wir auf die Sentimentanalyse eingehen und schrittweise demonstrieren, wie sie mit Hilfe von Modellen auf Hugging Face für Beiträge auf der Plattform X (ehemalig Twitter) durchgeführt werden kann.
In my feelings mit Hugging Face 🤗
Das 2016 gegründete Unternehmen Hugging Face mit Sitz in New York City ist eine Data Science und Machine Learning Plattform. Ähnlich wie GitHub ist Hugging Face gleichzeitig ein Open Source Hub für AI-Experten und -Enthusiasten. Der Einsatz von Huggin Face ist es, KI-Modelle durch Open Source Infrastruktur und Repositories für die breite Maße zugänglicher zu machen. Populär ist die Plattform unter anderem für seine hauseigene Open Source Bibliothek Transformers, die auf ML-Frameworks wie PyTorch, TensorFlow und JAX aufbauend verschiedene vortrainierte Modelle aus den Bereichen NLP, Computer Vision, Audio und Multimodale anhand von APIs zur Verfügung stellt.
Drake Meme by me
Für die Sentimentanalyse stehen uns über 200 Modelle auf der Plattform zur Verfügung. Wir werden im folgenden eine einfache Sentimentanalyse unter Verwendung von Transformers und Python durchführen. Unsere KI soll am Ende Ton, Gefühl und Stimmung eines Social Media Posts erkennen können.
Viel Spaß beim Bauen! 🦾
Let’s build! Sentimentanalyse mit Python 🐍
Zunächst brauchen wir Daten aus X/Twitter. Da im Anschluss auf die neuen Richtlinien die Twitter API jedoch extrem eingeschränkt wurde (rate limits, kostenspielige read Berechtigung) und es nun auch viele Scraping-Methoden getroffen hat, werden wir bereits vorhandene Daten aus Kaggle verwenden.
Elon Musk übernimmt Twitter und ändert den Namen um zu „X“
1. Datenbereitstellung: Kaggle
Wir entscheiden uns für einen Datensatz, der sich für eine Sentimentanalyse eignet. Da wir mit einem Text-Mining Modell in Transformers arbeiten werden, welches NLP verwendet um das Sentiment eines Textes zuordnen zu können, sollten wir uns für einen Datensatz entscheiden, in dem sich Texte für unsere Zielvariable (das Sentiment) befinden.
Hier kann ein Datensatz aus Kaggle verwendet werden, in dem über 80 Tausend englische Tweets über das Thema „Crypto“ in dem Zeitraum vom 28.08.2022 – 29.08.2022 gesammelt wurde: 🐦 🪙 💸 Crypto Tweets | 80k in English | Aug 2022 🐦 🪙 💸
Wir laden das Archiv herunter und entpacken die crypto-query-tweets.csv in unseren Projektordner.
2. Zielsetzung und Datenvorverarbeitung: Python + Pandas
Wir wollen in einer überschaubaren Anzahl an Tweets das jeweilige Sentiment zuordnen. Dazu schauen wir uns den Datensatz aus der CSV Datei genauer an. Uns interessieren dabei besonders Tweets von verifizierten Usern. Mit der Pandas Bibliothekt läss sich der Datensatz in Dataframes laden und nach bestimmten kriterien filtern.
wir installieren zunächst per pip-install die gewünschte Bibliothek und importieren diese in unsere Codebase.
pip install pandas
Anschließends lesen wir die CSV-Datei ein und filtern entsprechend unseren Wünschen den Datensatz und geben diesen als Dataframe aus.
import pandas as pd
# CSV Datei lesen
csv_file_path = "crypto-query-tweets.csv"
df = pd.read_csv(csv_file_path, usecols=['date_time', 'username', 'verified', 'tweet_text'])
# Filter anwenden um nur verifizierte User zu erhalten
filtered_df = df[df['verified'] == True]
# Printe Dataframe
print(filtered_df)
Wir erhalten folgende Ausgabe von 695 Zeilen und 4 Spalten:
date_time username verified tweet_text
19 2022-08-29 11:44:47+00:00 RR2Capital True #Ethereum (ETH)\n\nEthereum is currently the s...24 2022-08-29 11:44:45+00:00 RR2Capital True #Bitcoin (BTC)\n\nThe world’s first and larges...
25 2022-08-29 11:44:43+00:00 RR2Capital True TOP 10 TRENDING CRYPTO COINS FOR 2023\n \nWe h...
146 2022-08-29 11:42:39+00:00 ELLEmagazine True A Weekend in the Woods With Crypto’s Cool Kids...
155 2022-08-29 11:42:32+00:00 sofizamolo True Shill me your favorite #crypto project👇🏻🤩
... ... ... ... ...
79383 2022-08-28 12:36:34+00:00 hernanlafalce True @VerseOort My proposal is as good as your proj...
79813 2022-08-28 12:30:15+00:00 NEARProtocol True 💫NEARCON Speaker Announcement💫\n\nWe're bringi...
79846 2022-08-28 12:30:00+00:00 lcx True 🚀@LCX enables project teams to focus on produc...
79919 2022-08-28 12:28:56+00:00 iSocialFanz True Friday.. Heading to Columbus Ohio for a Web 3....
79995 2022-08-28 12:27:46+00:00 BloombergAsia True Bitcoin appeared stuck around $20,000 on Sunda...
[695 rows x 4 columns]
3. Twitter-roBERTa-base for Sentiment Analysis+TweetEval
Nun können wir mit Hugging Face Transformers eine vortrainiertes Modell verwenden, um allen Tweets entsprechende Sentiment Scores zuzuweisen. Wir nehmen hierfür das Modell Twitter-roBERTa-base for Sentiment Analysis, welches mit über 50 Millionen Tweets trainiert wurde und auf das TweetEval Benchmark für Tweet-Klassifizierung aufbaut. Weitere Infos unter dieser BibTex entry:
@inproceedings{barbieri-etal-2020-tweeteval,
title = "{T}weet{E}val: Unified Benchmark and Comparative Evaluation for Tweet Classification",
author = "Barbieri, Francesco and
Camacho-Collados, Jose and
Espinosa Anke, Luis and
Neves, Leonardo",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.findings-emnlp.148",
doi = "10.18653/v1/2020.findings-emnlp.148",
pages = "1644--1650"
}
Wir installieren alle für den weiteren Verlauf benötigten Bibliotheken.
pip install transformers numpy scipy
Die Transformers Bibliothekt erlaubt uns den Zugriff auf das benötigte Modell für die Sentimentanalyse. Mit scipy softmax und numpy werden wir die Sentiment Scores ausgeben mit Werten zwischen 0.0 und 1.0, die folgendermaßen für alle 3 Labels ausgegeben werden:
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
import numpy as np
from scipy.special import softmax
import csv
import urllib.request
Wir schreiben eine Methode zum vorverarbeiten des Texts. Hier sollen später Usernamen und Links aussortiert werden. Außerdem vergeben wir das gewünschte Modell mit dem gewünschten Task (’sentiment‘) in eine vorgesehene Variable und laden einen AutoTokenizer ein, um später eine einfach Eingabe-Enkodierung zu generieren.
# Vorverarbeitung des texts
def preprocess(text):
new_text = []
for t in text.split(" "):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
task='sentiment'
MODEL = f"cardiffnlp/twitter-roberta-base-{task}"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
Als nächstes laden wir das Label Mapping aus TweetEval für das zugeordnete Task ’sentiment‘ herunter. Das Modell für die Sequenzklassifizierung kann nun gespeichert und in der ‚model‘ Variable hinterlegt werden.
# download label mapping
labels=[]
mapping_link = f"https://raw.githubusercontent.com/cardiffnlp/tweeteval/main/datasets/{task}/mapping.txt"
with urllib.request.urlopen(mapping_link) as f:
html = f.read().decode('utf-8').split("\n")
csvreader = csv.reader(html, delimiter='\t')
labels = [row[1] for row in csvreader if len(row) > 1]
# Modell laden
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
model.save_pretrained(MODEL)
Im nächsten Schritt schreiben wir zwei Methoden, die dabei helfen sollen zeilenweise Tweet-Texte zu enkodieren und ein Sentiment Score zu vergeben. In einem Array sentiment_results legen wir alle Labels und entsprechende Scores ab.
# Sentiment Scores für alle Tweets erhalten
def get_sentiment(text):
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
scores = output.logits[0].detach().numpy()
scores = softmax(scores)
return scores
# Sentimentanalyse für jede Zeile im Datensatz anwenden
def analyze_sentiment(row):
scores = get_sentiment(row['tweet_text'])
ranking = np.argsort(scores)
ranking = ranking[::-1]
sentiment_results = []
for i in range(scores.shape[0]):
l = labels[ranking[i]]
s = scores[ranking[i]]
sentiment_results.append((l, np.round(float(s), 4)))
return sentiment_results
Zum Schluss wir das Dataframe um unser Ergebnis erweitert. Hierzu erstellen wir eine neue Spalte ’sentiment‘ und fügen mit der apply-Funktion die Ergebnisse aus unserer vorherigen Methode analyze_sentiement hinzu. Am Ende geben wir unser neues Dataframe in der Konsole aus.
# Ergebnisse in neue Spalte "sentiment" speichern
filtered_df['sentiment'] = filtered_df.apply(analyze_sentiment, axis=1)
# Ausgabe des neuen DataFrames
print(filtered_df)
Wir erhalten ein neues Dataframe mit einer weiteren Spalte in der das Label und die Sentiment-Scores festgehalten werden! 🤗🚀
Den gesamten Code könnt ihr euch auch auf meinem GitHub Profil ansehen oder klonen.
Referenzen
Han, Jiawei (2006). Data Mining: Concepts and Techniques, Simon Fraser University.
Barbieri, F., Camacho-Collados, J., Espinosa Anke, L., & Neves, L. (2020). Tweet Eval: Unified Benchmark and Comparative Evaluation for Tweet Classification. In Findings of the Association for Computational Linguistics: EMNLP 2020, S. 1644-1650. https://aclanthology.org/2020.findings-emnlp.148.
Wartena, Christian & Koraljka Golub (2021). Evaluierung von Verschlagwortung im Kontext des Information Retrievals. In Qualität in der Inhaltserschließung, 70:325–48. Bibliotheks- und Informationspraxis. De Gruyter, 2021. https://doi.org/10.1515/9783110691597.
Künstliche Intelligenz (KI) wird normalerweise damit in Verbindung gebracht, Menschen bei Aufgaben zu unterstützen, die durch Automatisierung besser erledigt werden können. Mit dem fortschreitenden technischen Wandel ist es der KI heutzutage aber nicht nur möglich, fortschriftliche visuelle Effekte in Filmen zu liefern oder den Videoschnitt zu erleichtern, sondern auch Prognosen hinsichtlich des möglichen Erfolgs eines Filmes zu liefern und ganze Storyboards zu verfassen. Die KI entwickelt sich immer mehr zu einer unausweichlichen Kraft, die Filme zukünftig weiter aufarbeiten und stetig verbessern wird. 1
Die KI „Benjamin“ und ihr Kurzfilm „Sunspring“
Hinsichtlich der Verwendung von KI in der Filmproduktion sticht besonders der Science-Fiction-Kurzfilm „Sunspring“ ins Auge, welcher 2016 debütierte. Das Interessante an diesem Film ist, dass er auf den ersten Blick wie viele andere Science-Fiction-Filme wirken mag – bis zur Erkenntnis, dass dessen Drehbuch ausschließlich von einer KI geschrieben wurde, welche sich selbst den Namen „Benjamin“ zuteilte. Es handelt sich hierbei um ein rekurrentes neuronales Netzwerknamens LSTM (long short-term memory), welches vorher mit Drehbüchern verschiedenster Science-Fiction-Filme sowie -Serien gespeist wurde. Trotz oder gerade wegen dieses daraus resultierenden, sehr kuriosen Drehbuchs wurde der Kurzfilm mit drei Schauspielenden gedreht und erhielt dadurch große Aufmerksamkeit. 2
Benjamin kreierte im selben Kurzfilm auch die Musik. Das neuronale Netzwerk wurde hier, ähnlich wie bei der vorangegangenen Vorgehensweise, mit vielen verschiedenen Einflüssen trainiert. In diesem Fall mit über 30.000 verschiedensten Popsongs. 3
Visuelle Effekte und Unterstützung in der Postproduktion
Als weitere Art der Unterstützung wird KI inzwischen im Zuge von weiteren bestehenden Produktionsabläufen sogar in Schnittprogramme implementiert. Dort kann sie unter anderem durch nur einen Klick Audio- oder auch Farbanpassungen vornehmen. 4 Doch nicht nur dort kommt künstliche Intelligenz in der Filmwelt der Postproduktion zum Einsatz. Im Bereich der visuellen Effekte kommt sie gerade beim Rotoskopieren zum Tragen, wo bestimmte Teile des Filmmaterials vom Hintergrund separiert werden. Rotoskopieren ist eine Technik, um animierte Filme und komplexe Bewegungsabläufe in Animationsfilmen realistischer wirken zu lassen. Als Beispiel dient hier das Unternehmen Array. Deren neuronales Netzwerk wurde mit Material gefüttert, welches von Visual Effect Artists arrangiert wurde. Nach ausreichendem Training kann das neuronale Netzwerk sogar ohne Unterstützung durch einen Greenscreen arbeiten. 5
Auch die Computersoftware „Massive“ sticht im Zuge der visuellen Effekte ins Auge. Ursprünglich für die „Herr der Ringe“-Trilogie entwickelt war diese mit Hilfe von künstlicher Intelligenz in der Lage, computergenerierte Armeen zu erstellen sowie realistische Schlachten in enormen Ausmaßen zu simulieren. „Massiv“ erschuf auch andere ikonische Kampfszenen der letzten Jahre, darunter Szenen aus „Game of Thrones“ sowie „Marvel’s Avengers: Endgame“. 6
Podcast „The Daily Charge“: How Lord of the Rings changed filmmaking
Den Erfolg eines Filmes vorhersagen
Ein ganz anderer Bereich, welcher durch KI revolutioniert wird, ist die prognostische Ebene. Denn sie ist inzwischen auch dazu in der Lage, Prognosen über den möglichen Erfolg eines Filmes zu treffen. Zum Beispiel soll die vom Datenwissenschaftler Yves Bergquist entwickelte KI „Corto“ dank künstlicher neuronaler Netze in der Lage sein, den Erfolg eines Films vorherzusagen. Das funktioniert nicht nur durch Analyse verschiedenster Elemente aus dem Film direkt, sondern auch über Daten aus sozialen Medien, wo die KI durch verschiedene Äußerungen die Stimmung sowie den kognitiven Zustand der Nutzenden ermittelt, die verschiedene Medieninhalte zugeführt bekommen haben. 7
Umwandlung alter Filmaufnahmen
Aber Künstliche Intelligenz kann auch für ganz andere Zwecke genutzt werden. So konvertierte ein YouTuber namens Denis Shiryaev eine über 100 Jahre alte Filmaufnahme der französischen Lumière-Brüder aus dem Jahr 1895 durch die Unterstützung einer KI auf das Videoformat 4k sowie die Bildrate auf 60 Bilder pro Sekunde. Somit verfrachtete er den Film durch Unterstützung einer KI technisch ins aktuelle Zeitalter. Hier bestand zwar durchaus noch Verbesserungspotential, allerdings geschah der Vorgang mit wenig Aufwand und wies erneut eindrucksvoll auf, zu was künstliche Intelligenz inzwischen in der Lage ist. 8
Quelle: Vimeo
Ersetzt die KI den Menschen?
Es ist wirklich erstaunlich zu sehen, was für einen großen Einfluss KI in der Welt der Filmproduktion hat und wie viele Bereiche dieser durch sie bereits vereinfacht werden können. Der damit verbundene technische Fortschritt eröffnete die letzten Jahre viele neue innovative Anwendungen in der gesamten Branche und ermöglicht Unternehmen nicht nur, die Effizienz ihrer Arbeitsabläufe zu steigern, sondern auch, ihre Arbeitskosten zu senken und mehr Umsatz zu generieren. 9
Trotz all dieser Vorteile sollte gerade ein Aspekt im Kopf verbleiben:
„KI ist weder nur ein Werkzeug noch ein vollständiger Ersatz für einen Schriftsteller. Man braucht eine Symbiose, um gemeinsam mit der Maschine Kunst zu kreieren.“ 10
Die Filmindustrie und vor allem der Streaming-Anbieter Netflix haben in den letzten Jahren mit einem selbst produzierten Aufgebot an interaktiven Filmen eine Art Hype geschaffen.
Ob mit der ganzen Familie auf der Couch oder alleine in den öffentlichen Verkehrsmitteln: Zuschauer*innen empfinden eine starke Bindung zum Geschehen im Film. Mehr noch: durch die gefühlte Partizipation, die suggeriert wird und durch die Aufmerksamkeit, die vorausgesetzt wird um ein erfolgreiches interaktives Erlebnis zu erfahren, entsteht fast ein ähnlich starkes Gefühl von Teilhabe den Verlauf zu beeinflussen, wie bei modernen Videospielen.
Doch der Wunsch nach Interaktion mit dem Filmgeschehen ist keine neue Idee und hat seinen Ursprung schon gar nicht in der Streamingindustrie.
„Einen ersten Versuch mit interaktiven Filmelementen unternahm beispielsweise Winsor McCays Zeichentrick-Experiment Gertie the Dinosaur (USA 1914), für das der Regisseur sich bei jeder Vorführung vor der Leinwand positionierte und mit der gezeichneten Dinosaurierdame Gertie ‹interagierte›, die seine Befehle ‹befolgte› „
Auch wenn es sich hierbei zweifelsfrei nicht mal annähernd um tatsächliche Interaktion zwischen Publikum und Filmgeschehen handelt, wird deutlich, dass die Idee schon früh Wurzeln in der Filmindustrie geschlagen hat.
Aber was macht interaktive Filmelemente so interessant und in welchen Bereichen kann man Sie heute und in Zukunft nutzen?
„Videos zählen aktuell und vermutlich auch künftig zu den bedeutendsten digitalen Medien im Internet. Sie lassen sich für fast alle Anwendungsbereiche verwenden und können Sachverhalte und Zusammenhänge so anschaulich und authentisch darstellen, wie es mit keinem anderen Medientyp möglich ist.“
Die Filmindustrie entwickelt sich stetig weiter, immer auf der Suche nach einem neuen Trend, in den letzten 10 Jahren ging es beispielsweise von 3D über 4D zu interaktiven Filmen. Ziel ist es dabei dem Zuschauer immer mehr das Gefühl zu geben er wäre in das Geschehen involviert, ein Wandel von Betrachtung hin zur echten Interaktion.
Trailer von „Du gegen die Wildnis“ (2019)
Beispiele für interaktive Filme aus den letzten Jahren
Die Möglichkeit mitzuentscheiden, wie sich die Handlung im Film gestaltet erweckt im Betrachter zwar die glaubhafte Illusion von Interaktivität, dabei ist dies natürlich keine freie, selbst gefällte Entscheidung, wie wir sie aus dem realen Leben kennen.Denn Interaktivität im Film hat ihre Grenzen. Auch wenn vermeintliche Partizipation suggeriert wird, sind Entscheidungsmöglichkeiten, dadurch, dass sie schon bei der Produktion erdacht wurden, vorbestimmt und in einer Art Baum-Struktur deklariert. So ist es dem Zuschauer zwar nicht möglich irgendwie die Handlung zu beeinflussen, aber er kann in manchen Fällen doch zwischen zwei oder mehr vorgegebenen Möglichkeiten wählen.
Die Filmindustrie steht noch am Beginn der Entwicklung interaktiver Kinoerlebnisse, die zukünftigen Veröffentlichungen versprechen spannend zu werden, werden aber nie unser Bedürfnis nach echter Interaktivität decken können.
Während die künstliche Intelligenz „AlphaZero“ Schach und „MuZero“ als Nachfolger verschiedene Spiele der Spielkonsole Atari meisterte, veröffentlichte die Firma Deepmind die nächste Entwicklungsstufe. Diese KI trägt den Namen DeepNash. AlphaZero meisterte Brettspiele mit klaren Regeln über ein modell-basiertes Training und MuZero, die schwer in Regeln auszudrückenden Atari-Spiele durch ein modell-freies Training. DeepNash hingegen legt sowohl die Spielregeln wie auch das Modell eines Spiels für die Planung fest. Die Besonderheit ist hierbei, dass von der gängigen Methode der Monte-Carlo-Baumsuche abgewichen wird. In der nachfolgenden Tabelle wird die unterschiedliche Komplexität von Brettspielen nochmals deutlich. [1][6]
Schach
Poker
Go 19*19
Stratego
durchschnittliche Züge je Spiel
60
15
300
1000
mögliche Startaufstellungen
1
106
1
1066
Komplexität des Spielbaums
10123
1017
10360
10535
Übersicht der Komplexität unterschiedlicher Brettspiele [3]
Die Nash-Spieltheorie
Das Besondere an DeepNash ist, dass es in den Spielen versucht ein Nash-Gleichgewicht zu erreichen. Hierdurch verläuft das Spiel stabil. Das Nash-Gleichgewicht ist nach dem Spieltheorie-Mathematiker Jon Forbes Nash benannt. Die Theorie folgt der Annahme, dass ein Abweichen der Strategie zu einem schlechteren Ergebnis führt. DeepNash und das Nash-Gleichgewicht folgen also konstant einer Strategie. Infolgedessen hat DeepNash mindestens eine 50%ige Chance zu gewinnen. [1][3]
Die KI DeepNash spielt Stratego
Youtube-Kanal Deepmind: Die erste Stratego Partie von DeepNash gegen einen menschlichen Gegner[2]
Die KI DeepNash nahm als Trainingsgrundlage das Brettspiel Stratego. Das Brettspiel hat im Schnitt 381 Spielzüge und die besondere Schwierigkeit, dass nicht alle Informationen von Beginn an gegeben sind, da mit verdeckten Figuren gespielt wird und der Gegner mit Hilfe von Bluffs i.d.R. seine Taktik verschleiert. Optimale Spielabläufe gibt es nicht, da die Züge inkonsequent sind, das heißt jederzeit ist das Spielergebnis offen. Es wird daher anders als beim Schach nicht in Zügen, sondern in Spielen gedacht. [1][3]
Die optimale Strategie in Stratego erreicht die KI nach 5,5 Milliarden simulierten Partien. [1] DeepNash besiegte damit 97% der derzeitigen Computersysteme und erreichte eine Siegesquote von 84% gegen menschliche Spieler auf der Online-Stratego-Plattform Gravon. DeepNash gelangte damit in die Top 3 der dortigen Bestenliste. Eine weitere Besonderheit der KI stellte die Anwendung menschlicher Spielstrategien dar. So zeigte DeepNash das Bluffen oder auch das Opfern von Figuren als Taktik. Der Algorithmus „Regularised Nash Dynamics“ (R-NaD) wird außerdem für Forschende als OpenSource Download auf Github zur Verfügung gestellt. [1][4][5]
Ausschnitt aus der OpenSource Publikation zu DeepNash[7]
Zukünftige KI Anwendungsfelder
DeepNash ist die nächste Weiterentwicklung, um Menschen in Brettspielen zu übertrumpfen und wird künftig als Grundlage für alltägliche Herausforderungen genutzt werden können. Insbesondere mit unvollständigen Informationen zu arbeiten stellt einen weiteren Meilenstein dar, der in der Lage ist bei komplexen Problemen wie der Optimierung des Verkehrssystems oder auch im Bereich des autonomen Fahrens – wie auch MuZero zuvor – einen Beitrag leisten zu können. [3][4][6]
Quiz
Teste nun dein Wissen über DeepNash in einem kleinen Quiz.
Über die Autoren
Die Autorin Jessica Arnold arbeitet derzeit in der Hochschulbibliothek Emden und studiert berufsbegleitend Informationsmanagement an der Hochschule Hannover.
Der Autor Jan Heinemeyer arbeitet derzeit in der Stadtbücherei Penzberg und studiert berufsbegleitend Informationsmanagement an der Hochschule Hannover.
Beide Autoren eint das private Interesse an Informatik, Gaming, KI und Brettspielen.
DeepMind (2023): DeepNash Stratego game 1. Online verfügbar unter https://www.youtube.com/watch?v=HaUdWoSMjSY, zuletzt aktualisiert am 05.01.2023, zuletzt geprüft am 05.01.2023.
Perolat, Julien u.a. (2022): Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning. Online unter https://arxiv.org/pdf/2206.15378.pdf [Abruf am 07.01.2023]
Die weltweite Musikindustrie ist im Wandel. 2017 wurde erstmals mehr Geld durch Musikstreaming eingenommen als durch den Verkauf von CDs, Schallplatten & Co. Somit liegt auch der Fokus großer Plattenlabel auf dem digitalen Musikmarkt. Führt diese Änderung der Marktsituation auch zu einer Veränderung der Musik als solches?
Früher ging man in einen Plattenladen, um ein Album zu kaufen. Im Anschluss konnte man diese Schallplatte so häufig hören, wie man wollte, der Interpret und das Label sahen kein zusätzliches Geld. Beim Musikstreaming wird heute jeder gehörte Song, jeder Play einzeln bezahlt. Je nach Streamingdienst werden pro 1000 Streams zwischen 70 ct und 27 € ausgezahlt.
Zur Vereinfachung konzentrieren wir uns auf Spotify, welche ca. 4 € für 1000 Streams auszahlen.1 Dabei gilt jedoch: nicht jeder Stream zählt gleich viel. So sind bspw. Streams aus den USA mehr wert als Streams aus Portugal. Außerdem kommt es darauf an, ob der Nutzer ein Spotify-Abo hat oder die werbefinanzierte Gratisversion nutzt.2 Streams werden zudem erst gezählt, wenn der Song mindestens 30 Sekunden langlief.3Diese 4 € gehen zudem nicht vollständig an die Interpreten, da auch die Musiklabels mitverdienen wollen.
Doch welchen Einfluss auf die Musik hat es, wenn Musikschaffende nicht mehr für Verkäufe, sondern für Plays bezahlt werden?
3 Minuten Spiellänge und über 77 Millionen Aufrufe. Mit 22 Nummer-Eins-Hits ist der Rapper Capital Bra erfolgreicher als die Beatles.
Der Algorithmus
Hinter Spotify steckt ein großer Algorithmus, welcher allen Nutzenden auf Basis ihres Hörverhaltens ständig neue Songs empfiehlt. Songs, die in den ersten 30 Sekunden abgebrochen werden, zählen nicht als Play – werden also weder bezahlt noch vom Algorithmus für Empfehlungen berücksichtigt. Ziel der Musikschaffenden sollte es demnach sein, die Hörer:innen direkt zu Beginn des Songs zu fesseln. Dies führt dazu, dass das durchschnittliche Intro eines Songs in den 80er-Jahren noch 20 Sekunden lang war – heutzutage nur noch 5 Sekunden.4
Wie funktioniert eigentlich der Spotify-Algorithmus?
Auch die Länge eines Songs hat sich seit dem Siegeszug der Streamingdienste geändert. In den letzten 20 Jahren sank die durchschnittliche Songlänge um 73 Sekunden. Logisch, denn es macht sowohl finanziell als auch für den Algorithmus einen großen Unterschied, ob ein Song 20 oder 30 Plays in einer Stunde erzielen kann. Hinzu kommt, dass bei längeren Songs die Wahrscheinlichkeit eines Abbruchs größer ist als bei kürzeren Songs. Dies würde dazu führen, dass der Song seltener empfohlen wird.5 Die Anzahl der Songs in den amerikanischen Billboard Top 100-Charts, die kürzer sind als 2:30 Minuten, steigt dadurch seit Jahren stark an.6
Songs werden immer kürzer – auch durch Spotify?
Einfluss von Musikstreaming auf Musikcharts
Seit einigen Jahren werden die Charts von den Streamingzahlen beeinflusst.7 Da dadurch nicht nur eigens ausgekoppelte Singles bewertet werden, kommt es häufiger dazu, dass viele Songs eines Albums die vorderen Plätze belegen, so geschehen u.a. bei Taylor Swift in den USA. Durch die generelle Schnelllebigkeit und die Fixierung auf Plays statt Albumkäufen veröffentlichen viele Musikschaffende zudem (fast) nur noch Singles. Der Deutsch-Ukrainer Capital Bra schaffte es so in nur zweieinhalb Jahren 22 Nummer-Eins-Hits zu veröffentlichen – doppelt so viele wie die Beatles in ihrer gesamten Karriere.8
Belegte gleichzeitig alle Top-10-Plätze in den USA: Taylor Swift
Um bekannt und erfolgreich zu werden ist es für Musikschaffende am wichtigsten, auf den von Spotify erstellten Playlists zu landen. Neben den von Mitarbeiter:innen kuratierten Playlists gibt es auch komplett automatisch vom Algorithmus erstellte (und ständig aktualisierte) Playlists, die ganz auf den Geschmack jedes einzelnen Nutzers zugeschnitten sind. So werden Nutzer mit ähnlichem Musikgeschmack ähnliche Songs empfohlen. Ganz wichtig ist auch hierbei wieder die bekannte 30-Sekunden-Grenze.9
Der perfekte Musikstreaming-Song?
Aber gibt es den perfekten, erfolgsversprechenden Spotify-Song? Nicht wirklich. Zwar hilft es, einen kurzen Song ohne Intro zu haben, eine Garantie ist das jedoch noch lange nicht. Unabhängig davon gilt noch immer: ein Hit ist ein Hit ist ein Hit.
Wie auch in vielen anderen Bereichen der Technik macht auch das Internet of Things (IoT) große Entwicklungsschritte. Dazu gehören auch sogenannte Smart-Home-Systeme, die eine immer weitere Verbreitung in deutschen Haushalten finden. Aus den vielseitigen Anwendungsbereichen ergeben sich neben komfortablen Alltagshilfen auch einige Fragen zur Sicherheit, gerade hinsichtlich Datenschutzes und Künstliche Intelligenz (KI) . In diesem Artikel sollen einige der Sicherheitslücken aufgedeckt und Lösungsansätze erläutert werden.
KI, was ist das eigentlich?
Immer häufiger hört man heutzutage diesen Begriff, aber was zeichnet die KI eigentlich aus? Normalerweise verarbeitet eine Maschine stumpf Daten. Eine KI ist allerdings in der Lage bestimmte Muster zu erlernen, um Entscheidungen auf der Basis von Informationen zu treffen. Dieses Vorgehen nennt man „Machine Learning“. Damit ist eine menschenähnliche kognitive Leistung möglich. Übertragen wir das auf unsere Smart-Home-Systeme bedeutet, dass, die Geräte erlernen unsere Verhaltensmuster und reagieren entsprechend darauf. Der aktuelle technische Stand ermöglicht das noch nicht umfangreich, zielt aber darauf ab. Bislang entscheiden sind das Erkennen und Befolgen von Wenn-Dann-Regeln.
KI im eigenen Zuhause:
@Smartest Home 2020
Smart-Home-Anwendungen bieten einige Vorteile
Smart-Home-Anwendungen haben einige Vorteile zu bieten, andernfalls würden sie sich nicht immer wachsender Beliebtheit erfreuen. Dazu gehören unter anderem:
Erhöhter Komfort: viele Aufgaben müssen nicht mehr selbst erledigt werden, sondern werden bequem von den Smart-Home Anwendungen übernommen. Beispiele hierfür sind z.B. das Saugen von Böden, Rasen mähen oder das automatische Angehen der Kaffeemaschine am Morgen
Vereinfachte Bedienung: durch die Steuerung per App kann man alle Anwendungen aus einer Stelle heraus bedienen, noch einfacher wird das Ganze mit Spracherkennung/Sprachbefehlen
mehr Sicherheit: durch das vernetzte System kann der Besitzer durch Push-Nachrichten auf sein Handy informiert werden, wenn z.B. ein Alarm ausgelöst wird. Gleichzeitig kann ein ausgelöster Alarm dazu führen, dass sich Türen und Fenster verriegeln
Senkung des Energieverbrauch: Geräte sind so programmiert, dass sie möglichst wenig Strom verbrauchen. So kann man z.B. mit Hilfe von einem Timer einstellen, wann das Licht ausgehen soll
Sicherheitslücken in den Systemen
Die komplexe technische Vernetzungbringt auch einige Risiken mit sich, wie sich in den Bereichen des Datenschutzes und der IT-Sicherheit zeigt. Die Smart-Home-Anwendungen sind durchgehend mit dem Internet verbunden. Das macht sie sehr anfällig für den unautorisierten Zugriff durch Hackerangriffe, die sich so den Zugriff zu sämtlichen Geräten in einem Haushalt verschaffen können. Um das zu vermeiden ist das regelmäßige Durchführen von Updates essenziell. Viele Risiken entstehen durch den Anwender selbst. So können fehlende technische Vorkenntnisse und die daraus resultierenden Bedienungsfehler zu schwerwiegenden Sicherheitslücken führen. Daher ist es wichtig, sich mit der Technik der Geräte auseinander zu setzen und ggfs. nochmal die richtige Funktionsweise zu überprüfen. Es stellt sich zudem die Frage, inwiefern die Daten gespeichert und verarbeitet werden. Das ist oft nicht transparent für den Benutzer, und da es sich um sensible personenbezogene Daten wie Kameraaufzeichnungen handelt, ist dieser Punkt nicht zu missachten.
Personenbedingte Fehler
Neben den technischen Fehlerquellen können natürlich auch von Menschenhand erzeugte Fehler Sicherheislücken hervorrufen. Zum einen ist es wichtig, dass sich Anwender vor der Anschaffung intensiv mit der Technik befassen. Oftmals scheitert es an fehlender Planung und das dem Informationsmangel über die Anwendung. Das kann wiederrum zu Anwendungsfehlern führen, die schwerwiegende Sicherheitsmängel bilden können. Wir tendieren oft dazu, zu günstigeren Alternativen zu greifen, was in diesem Fall aber eine fehlende Sicherheitszertifizierung bedeutet und ebenfalls vermehrt Sicherheitslücken aufweißt. Eine noch ausführlichere Hilfe bietet der folgende Artikel: Diese 5 Fehler machen fast alle Smart Home Einsteiger (homeandsmart.de)
Einfacher Schutz im Alltag
Wie kann ich mich also vor den vielfältigen Angriffsmöglichkeiten schützen? Es sind eigentlich ein paar ganz simple Tipps, wie man den Sicherheitsstandard der Smart-Home-Anwendung hochhält:
keinen direkten Internetzugriff: ist ein System direkt mit dem Internet verbunden, ist es leichter für z.B. Hacker dieses zu finden und zu hacken. Am sichersten ist es, denn Zugriff über ein VPN zu nutzen
System regelmäßig aktualisieren: für jedes System gibt es reglemäßig Updates, diese sollte man zeitnah durchführen um Bugs und Fehler in der Software zu beheben.
sichere Passwörter: ein simpler, aber oft missachteter Tipp ist es, ein sicheres Passwort zu vergeben, dass eine Kompination aus Groß- und Kleinschrift, Sonderzeichen und Zahlen beinhaltet. Dieses sollte in regelmäßigen Abständen geändert werden.
unnötige Dienste ausschalten: schalten Sie nicht benötigte Anwendungen aus, denn was nicht läuft, kann nicht angegriffen werden
Fazit: trotz Sicherheitslücken wachsender Trend mit Luft nach oben
Was lässt sich nun abschließend festhalten? Wenn man einige grundlegende Sicherheitsvorkehrungen beachtet und sich selbst mit den technischen Anwendungen befasst bieten Smart-Home-Anwendungen eine gute Möglichkeit sich den Alltag einfacher zu gestalten. Smart-Home-Anwendungen stehen noch relativ am Anfang ihrer technischen Möglichkeiten und sind auch noch lange kein fester Bestandteil in einem durchschnittlichen Haushalt. Auch die Zukunftserwartungen sind noch nicht erfüllt worden.
«Wir glaubten damals, dass es eine allmächtige, zentrale Intelligenz geben werde, die je nach Stimmung eine automatische Lichtauswahl trifft, ohne unser Zutun Essen für den Kühlschrank nachbestellt und so weiter. Diese Vision ist nicht eingetreten, zumal die Installation und Konfiguration einer einzigen, zentralen Lösung viel zu komplex wäre. Stattdessen gibt es heute viele partielle Lösungen, beispielsweise für die Beleuchtung, die Soundanlagen oder die Sicherheit.»
Baumann, Melanie (2020): Diese 5 Fehler machen fast alle Smart Home Einsteiger. Smart Home Anfängerfehler und wie sie Einsteiger vermeiden. Zuletzt aktualisiert am 02.02.2020. Online unter https://www.homeandsmart.de/fehler-smart-home-einsteiger [Abruf am 24.01.2023]
Hüwe, Peter ; Hüwe, Stephan (2019): IoT at Home. Smart Gadgets mit Arduino, Rasperry Pi, ESP8266 und Calliope entwickeln. München : Carl Hanser Verlag
In einem TikTok-Video berichtet eine etwa 30-jährige Frau von einem tragischen Vorfall.
Ein 16 Jahre alter Junge namens Daniel engagierte sich ehrenamtlich in einer Flüchtlingsunterkunft. Als Daniel jedoch in Gegenwart der ukrainischen Flüchtlinge russisch sprach, wurden einige von ihnen aggressiv und schlugen den Jungen zusammen. Dieser starb an seinen Verletzungen. Die Täter wurden straffrei zurück in ihre Unterkunft geschickt.
Die Frau berichtete in Ihrem Video den Vorfall sehr detailliert und emotional. Sie brach in Tränen aus und verstand nicht, wie so etwas passieren konnte.
Was geht in Ihnen vor, wenn Sie das lesen? Verwirrung? Wut? Mitleid? Es ist ganz normal, dass man einem so aufrichtigen Statement zunächst erst einmal Glauben schenkt und nicht weiter hinterfragt.
Die Rede ist von dem Mord in Euskirchen, der nie stattgefunden hat.
Die Bundespolizei NRW bezieht zeitnah Stellung zum geschilderten Vorfall.
Zahlreiche Nachrichtenagenturen berichten von dieser Falschmeldung, wie z.B. die Frankfurter Allgemeine[1], t-online[2] und der ZDF[3].
Zusammenhang
Doch was hat der Gefühlsausbruch der TikTokerin mit KI-Bots zu tun?
Die Dame, die die o.g. Falschmeldung verbreitet hat, erklärte, sie habe diese Information über mehrere Ecken erfahren und hätte selbst fest geglaubt, dass es wahr sei. Sie hat also in erster Linie darauf vertraut, dass eine Meldung, die Freunde von ihr teilten, wahr sein müsste und deshalb nicht auf ihren Wahrheitsgehalt überprüft werden müsse.
Ferngesteuerte Demonstrationen
Am 21. Mai 2016 fand eine größere Demonstration gegen die Islamisierung in Texas statt. Diese wurde von der Facebook-Gruppe “Heart of Texas” organisiert. Dem entgegen organisierte die Gruppe “United Muslims of America“ einen Gegenprotest[4].
Durch diese Positionierung wurde das politische Augenmerk auf das Thema Muslime gelenkt und andere Themen verschwanden aus dem Fokus.
Aber ausgelöst und organisiert wurden die Demos pro und kontra Muslime von Menschen, bzw. Rechnern, die in Petersburg stehen. Es wurde keiner der Organisatoren vor Ort gesichtet, weil alles inszeniert war.
Es versammelten sich echte Menschen, weil für sie relevante Themen angesprochen, verschärft und anschließend durch Social-Bots kommentiert, geteilt und geliked werden. So werden sie gesehen und je mehr Interaktion stattfindet, desto offizieller kommt die Information beim Konsumenten an.
Hasskommentare sind ebenfalls ein fester Bestandteil von Social-Bots. Oft sind diese sehr polarisiert, wenig kreativ und schnell verfasst. Ihr Ziel ist es, Vertreter einer ungeteilten Meinung zum Schweigen zu bringen. Selbst vor Morddrohungen wird nicht zurückgeschreckt.
Einen Blick in die Vergangeneit
Es ist in Ordnung, anderer Meinung zu sein. Aber warum gibt sich jemand die Mühe, mehrere Menschen zu beschäftigen, damit sie ausgewählte Nachrichten teilen, oder gegen bestimmte Personen anzugehen?
Häufig wird bei den organisierten Troll-Aktionen auch von Propaganda gesprochen.[6]
So ähnlich wurde bereits der zweite Weltkrieg eingeläutet. Durch Falschmeldungen hatte man glauben lassen, dass Polen Deutschland angegriffen habe und dass der erste Angriff lediglich eine Gegenmaßnahme sei .[7] In der damaligen Zeit konnte man noch nicht so einfach wie heute durch das Internet überprüfen, wie hoch der Wahrheitsgehalt einer Nachricht sein kann. Jedoch ist es heute umso leichter eine Falschmeldung zu verbreiten und jeder Rechercheaufwand ist eben mit einem Aufwand verbunden.
Doch das Ziel solcher Aktionen wird mit einem Vergleich klar. Der Hintergrund von Fake-News ist die Lenkung von politischen Positionen.
Bot-Produktion
Nun wurden in diesem Artikel oft die “Social-Bots” genannt. Aber woher kommen diese Social Bots und wie viel Mensch und wie viel KI steckt dahinter?
Zunächst werden Bots von einem Menschen erstellt und mit verschiedenen Accounts versorgt. Ein Algorithmus mit typischen wenn-dann-Abfolgen lässt diese dann auf Sozialen Netzwerken interagieren. Bestimmte Wörter triggern diese Bots zu vorgeschrieben Ineratkionen, wie einem Kommentar, einem Like oder das Teilen bestimmter Beiträge.[8]
Nicht alle werden dafür genutzt, Meinungen zu manipulieren. Viel häufiger werden Social-Bots zu Marketing-Zwecken genutzt. Die einfachste Form ist, einen Anbieter entsprechender Bots dafür zu bezahlen, um eine erste Followerschaft zusammenzustellen. Das heißt, dass mehrere Hundert Fake-Accounts einem Unternehmen folgen und mit Beiträgen interagieren. Diese Interaktion ist zwar nicht komplex, reicht aber, um eine gewisse Nachfrage und Bekanntheit vorzugaukeln und den Algorithmus der Plattform zu triggern, wodurch die eigenen Beiträge öfter von verschiedenen Menschen gesehen werden.
Wie erkenne ich einen Bot?
Ein Erfolgsrezept existiert leider nicht.
Aber obwohl man es niemals wirklich wissen kann, gibt es ein paar Anhaltspunkte, an denen man sich orientieren kann. Wie allgemein ist die Account-Beschreibung gehalten und wie neu ist der betreffende Account? Bei prominenten Persönlichkeiten gibt es Merkmale zur Verifizierung, wie es den blauen Haken bis vor kurzem bei Twitter gab. Wenn ein Account neu ist und sehr viel Zeit nur mit dem Verfassen von Kommentaren und dem Teilen von Beiträgen verbringt, ist es ein weiteres Indiz, dass ein Social-Bot dahinterstecken könnte. Manchmal ist ein Antworttext in sekundenschnelle Geschrieben, obwohl man so aktiv ist und Lesen und Verfassen i.d.R. mehr Zeit in Anspruch nehmen müsste. Zudem scheitert ein Bot, wenn eine Unterhaltung komplexer wird, da die geschriebenen Programme nicht jede Eventualität, die ein Gespräch einschlagen kann, berücksichtigen.[9]
Kommentare werden geladen …
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.