

Autori*nnen: Judith Hauschulz und Verena-Christin Schmidt
Oder: Werden Windeln und Bier wirklich oft zusammen gekauft?
Die Warenkorbanalyse gehört zum Data Mining und ist ein Anwendungs-gebiet der Assoziationsanalyse. Wenn du diese Begriffe hörst, ist dir wahrscheinlich klar, dass es um Daten geht. Aber das klingt nun vielleicht etwas trocken, deshalb fangen wir nochmal neu an:
-
- Du wolltest schon immer wissen, warum
 dir beim Online-Shopping „passende“ Artikel vorgeschlagen werden?
dir beim Online-Shopping „passende“ Artikel vorgeschlagen werden? - Dich interessiert, wieso sich die Süßigkeiten im Supermarkt immer auf dem Weg zur Kasse befinden?
- Oder du willst einfach endlich erfahren, was da eigentlich dahintersteckt?
- Du wolltest schon immer wissen, warum
Dann bist du hier genau richtig! Wir erklären dir, wie das funktioniert. Doch dazu fangen wir erst einmal beim Allgemeinen an: dem Data Mining.
Was bedeutet Data Mining?
Eigentlich heißt Data Mining nur „Datenschürfen“. Dabei soll aus Daten Wissen erzeugt werden.1 Mit Wissen ist hier ein Muster gemeint, das für NutzerInnen interessant ist oder auch interessant sein kann. Ein Muster besteht dann wiederum aus Beziehungen zwischen Daten oder Regelmäßigkeiten und wird Datenmustererkennung genannt. 2
In der Graphik kannst du den Ablauf des Data Minings ablesen. Das Ganze stellt einen Prozess dar, bei dem das Ziel ist, dass man neue Erkenntnisse gewinnt. Dabei beschränkt man zuerst eine große Menge an Rohdaten auf eine kleinere Auswahl, sodass sie anschließend verarbeitet werden können. So dienen sie also als Grundlage für die Muster, die das Data Mining aufdecken soll.3
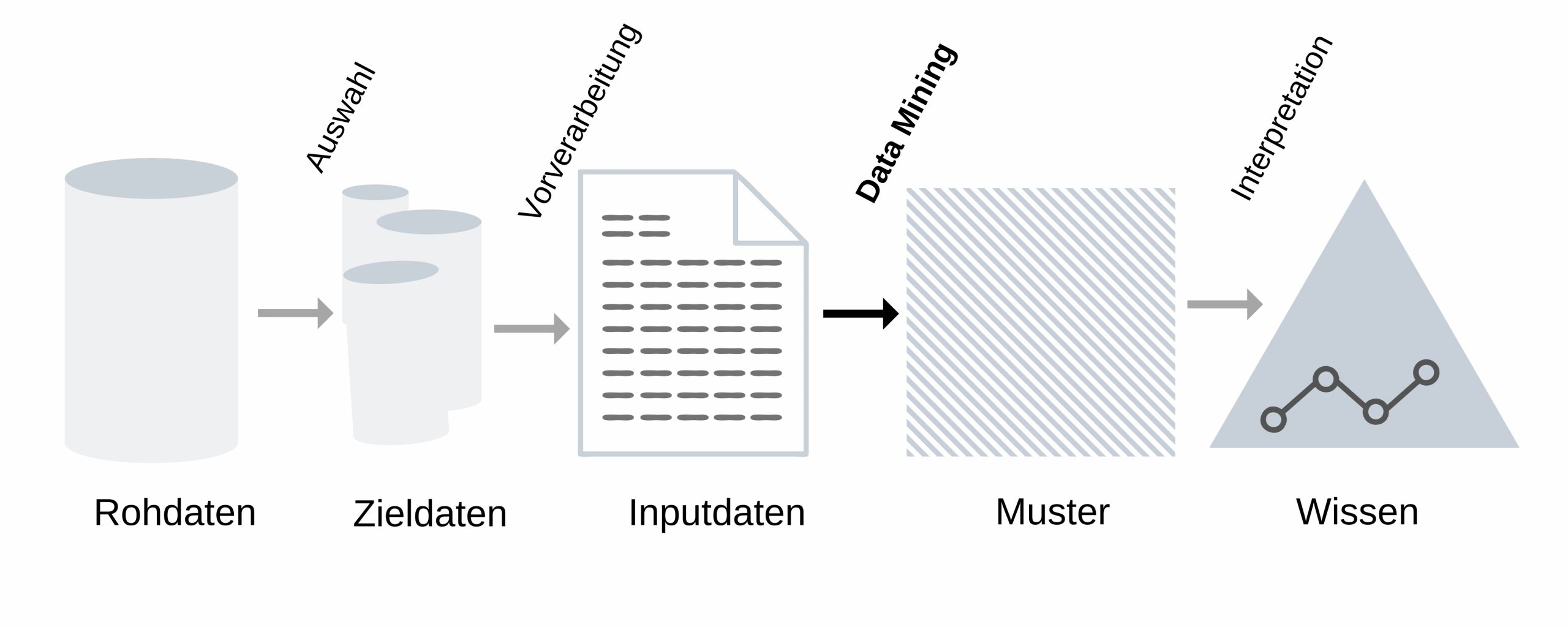
Es gibt sehr viele Verfahren im Data Mining. Wir erklären dir aber nur die Assoziationsanalyse, weil sie relevant für die Analyse von Waren ist. Sie zählt zu den bekannteren beziehungsweise typischen Methoden des Data Minings.4
Assoziationen im Data Mining
"Die Assoziationsanalyse gehört zu einem der grundlegendsten Verfahren in der Datenanalyse und spielt im wirtschaftlichen Bereich eine große Rolle."5
Mit der Assoziationsanalyse kannst du Abhängigkeiten und Zusammenhänge in großen Datenmengen ermitteln. Dazu benutzt man sogenannte Items. Stell sie dir am besten wie Produkte im Supermarkt vor! Mit diesen Items können wir dann Berechnungen durchführen. Wir könnten also schauen, ob zwei von ihnen auffällig oft gemeinsam vorkommen.
Es kann aber auch passieren, dass ein Item besonders dann auftritt, wenn ein anderes Item vorhanden ist. Ein Item kann sogar das Vorkommen eines anderen Items begünstigen. Wenn das eintritt, lassen sich da-raus Assoziationsregeln ableiten.1 Aus ihnen können wir beispielsweise Vorhersagen treffen oder Empfehlungen aussprechen.
Als Ergebnis erhalten wir Regeln, die folgende Form haben:
"Wenn Item A vorliegt, dann tritt in X Prozent
"6
Diese Regeln der Assoziationsanalyse können wir benutzen, um zum Beispiel Wechselwirkungen verschiedener Medikamente zu erforschen. Und auch wenn man Zusammenhänge bei der Wahl von Anlageformen bei Banken aufdecken möchte, ist sie nützlich.7 Ein wesentlich bekannteres Beispiel ist aber die Empfehlung von Artikeln im Online-Handel. Wenn wir einen Artikel aufrufen, dann zeigt uns die Seite oft, was andere KundInnen noch gekauft haben.8 Solche Vorhersagen lassen sich auch aufgrund von Warenkorbanalysen treffen.
Warenkorbanalyse mit Bier und Windeln
In einer Folge der Serie “Numb3rs – Die Logik des Verbrechens” geht es um ein beliebtes Beispiel der Warenkorbanalyse. Windeln und Bier werden hier sehr oft zusammen gekauft. Auch wenn es erstaunlich erscheint, so haben sie eine logische Erklärung dafür: Männer, die von ihren Frauen zum Windelkauf aufgefordert werden, kaufen gerne noch Bier dazu. Damit haben sie etwas, worauf sie sich nach der „Arbeit mit dem Kind“ freuen und was sie genießen können. Darum kommt es zu dem Ergebnis, dass das Bierregal auf dem Weg von den Windeln zur Kasse platziert und so der Umsatz gesteigert wird.9
Die Warenkorbanalyse unter den Data Mining-Verfahren
Bei der Warenkorbanalyse wertet man die Einkäufe von KundInnen aus, um dadurch verschiedene Items zu untersuchen. Die Items bestehen hier aus den Artikeln von zum Beispiel Supermärkten. Alle Kaufaktionen zusammengefasst ergeben die Datenbasis.7
Fast alle Unternehmen, die Waren verkaufen, haben die Daten, die für das Data Mining mit der Warenkorbanalyse nötig sind. Schon einige Kassenbons reichen aus und es wird kein spezielles System benötigt. Damit lassen sich dann stark nachgefragte Produkte ermitteln oder Verbindungen zwischen verschiedenen Waren untersuchen.10 Mit der Analyse können wir also auch erfahren, wie oft ein Produkt mit einem anderen im Warenkorb landet. Um dabei die „Spreu vom Weizen“ zu trennen, werden Assoziationsregeln erstellt.11 Aber wie können wir denn nun Muster finden?
 Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.12
Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.12
Werden Bier und Windeln wirklich oft zusammengekauft?
Wenn wir Zusammenhänge und Abhängigkeiten berechnen wollen, müssen wir (leider) etwas mathematisch werden. Aber keine Angst, wir benutzen dafür ein leicht verständliches und nachvollziehbares Beispiel.
Zuerst brauchen wir die drei Kennzahlen Support, Konfidenz und Lift. In der Tabelle steht ein Beispiel, dass dir helfen wird, um diese Kennzahlen zu verstehen. Bei uns geht es lediglich um zwei Produkte. Insgesamt untersuchen wir hier aber 1.000.000 Transaktionen beziehungsweise Einkäufe. Darin kommen auch 200.000-mal der Kauf von Bier und 50.000-mal der Kauf von Windeln vor. Die KundInnen dieses Supermarkts haben Bier und Windeln sogar 20.000-mal gleichzeitig gekauft.
| Anzahl | Waren |
|---|---|
| 1.000.000 | Transaktionen insgesamt |
| 200.000 | Bier |
| 50.000 | Windeln |
| 20.000 | Windeln und Bier |
Los geht die Warenkorbanalyse…
Wie oft werden Bier und Windeln denn nun zusammen gekauft? Um das zu erfahren, berechnen wir den Support. Dafür setzen wir zuerst die Anzahl der Käufe von Bier und Windeln separat ins Verhältnis aller vorliegenden Einkäufe. Danach machen wir das genauso mit der Anzahl der gemeinsamen Käufe, sodass wir einen Support von 2% erhalten.

Die Konfidenz sagt uns, wie oft eine Assoziationsregel („Wenn Bier gekauft wird, dann werden auch Windeln gekauft“) richtig ist. Sie gibt außerdem einen Hinweis darauf, wie stark der Zusammenhang zwischen Bier und Windeln ist.11
Wenn wir die Konfidenz berechnen wollen, brauchen wir die Support-Werte. Zu Beginn teilen wir dabei den gemeinsamen Support durch den einzelnen Support des Biers. Daraus ergibt sich eine Konfidenz von 10%. Weil das noch nicht besonders viel ist, drehen wir die Assoziationsregel einfach mal um. Somit ergibt sich eine Konfidenz von 40%, da nun die Anzahl der Windel-Einkäufe die Bezugsgröße darstellt.
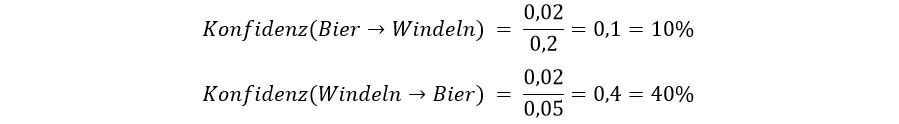
Die zweite Regel zeigt also ein Muster auf, das der Supermarkt so nutzen kann: Wenn das Bier in Sichtweite der Windeln positioniert wird, dann wird beides häufiger zusammen gekauft werden.7
Ob der Kauf von Bier und Windeln nun wirklich zusammenhängt, verrät der Lift. Er sagt uns auch, um wieviel wahrscheinlicher Windeln den Kauf von Bier machen. Dafür müssen wir den gemeinsamen Support durch das Produkt der einzelnen Support-Werte teilen.
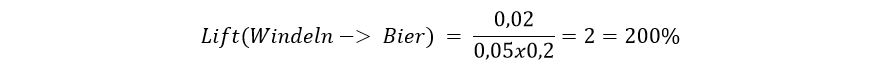
Das Ergebnis ist ein Lift von 200%. Das heißt, dass der Kauf von Windeln die Wahrscheinlichkeit für den zusätzlichen Kauf von Bier sogar verdoppelt!
Zur Erklärung: Ein Lift von 100% würde stattdessen bedeuten, dass beide Items unabhängig voneinander sind. Bei einem Lift, der kleiner als 100% ist, ist es unwahrscheinlich ist, dass beide Items zusammen auftreten.11
Was bringt die Warenkorbanalyse?
Wie du siehst, ist es eigentlich doch ganz einfach, Muster und Abhängigkeiten zu entdecken. Wenn wir uns aber nicht nur mit zwei, sondern mit allen Artikeln eines Supermarkts beschäftigen würden, so wäre es deutlich schwieriger. Wir hätten dann ja viel mehr Daten, wodurch sich der Umfang der Berechnungen massiv erhöhen würde. Umso besser ist aber dadurch das Endergebnis. Aus einer großen und umfangreichen Warenkorbanalyse gewinnt man nämlich nicht nur ein paar Muster, sondern das gesamte Einkaufsverhalten der KundInnen. Das können Unternehmen für Dinge nutzen, wie zum Beispiel:
-
- Regalplatzierungen
- Preisgestaltung
- Rabatt-Aktionen
- zielgerichtetes Marketing12
Sobald Unternehmen die Warenkorbanalyse benutzen, geht es aber auch immer darum, das Angebot zu optimieren und den Umsatz zu steigern.10
Gut aufgepasst? Überprüfe jetzt dein Wissen mit dem Quiz zum Data Mining mit der Warenkorbanalyse!
Wenn du mehr darüber erfahren willst, warum wir diesen Beitrag geschrieben haben, dann lies dir doch unser Konzept durch. Darin erklären wir auch, wie wir beim Verfassen von „Data Mining mit der Warenkorbanalyse“ vorgegangen sind.
Quellenverzeichnis
1 vgl. Cleve, Jürgen; Lämmel, Uwe (2016): Data Mining. 2. Auflage. Berlin, Boston: De Gruyter Saur
5 Begerow, Markus u.a. (2019): Assoziationsanalyse. Online unter https://www.datenbanken-verstehen.de/lexikon/assoziationsanalyse/ [Abruf am 20.12.2019]
8 vgl. Zaki, Mohammed J. ; Meira Jr., Wagner (2013): Data Mining and Analysis. Fundamental Concepts and Algorithms. Online unter https://repo.palkeo.com/algo/information-retrieval/Data%20mining%20and%20analysis.pdf [Abruf am 16.12.2019]
9 vgl. Swoyer, Stephen (2016): Beer and Diapers. The impossible correlation. Online unter https://tdwi.org/articles/2016/11/15/beer-and-diapers-impossible-correlation.aspx [Abruf am 17.12.2019]
10 vgl. Poliakov, Vladimir (2019): Data Science. Warenkorbanalyse in 30 Minuten. Online unter https://www.heise.de/developer/artikel/Data-Science-Warenkorbanalyse-in-30-Minuten-4425737.html [Abruf am 13.12.2019]
11 vgl.Rabanser, Alexander (2018): Warenkorbanalyse Teil 1. Analytische Grundlagen und Korrelationsanalyse in Excel. Online unter https://linearis.at/blog/2018/04/06/warenkorbanalyse-teil-1-analytische-grundlagen-und-korrelationsanalyse-in-excel/ [Abruf am 13.12.2019]
Dieser Beitrag ist im Rahmen der Lehrveranstaltung Content Management im Wintersemester 2019/20 bei Andre Kreutzmann (und Monika Steinberg) entstanden.


