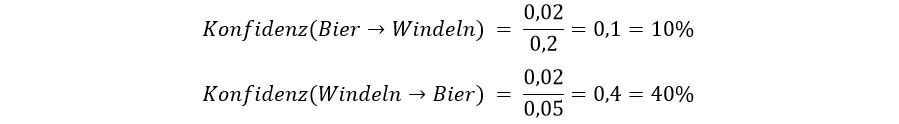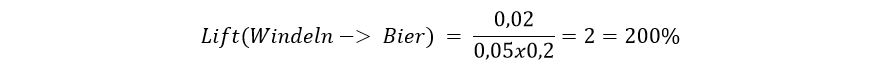Autorin: Lene-Christine Brammer
Bibliotheken haben den Auftrag, Medien und Informationen für Nutzerinnen und Nutzer aufzuarbeiten und bereitzustellen. Doch jedes Jahr werden mehrere Millionen Publikationen veröffentlicht. Die DNB allein verzeichnete den Zugang 2.352.693 neuer Einheiten im Jahre 2020[1]. Wer soll da den Überblick behalten? Text und Data Mining kann hier Abhilfe schaffen.
- Was ist Text und Data Mining?
- Anwendungsmöglichkeiten für Bibliotheken
- Herausforderungen
- Ausblick
- Quellen
Was ist Text und Data Mining?
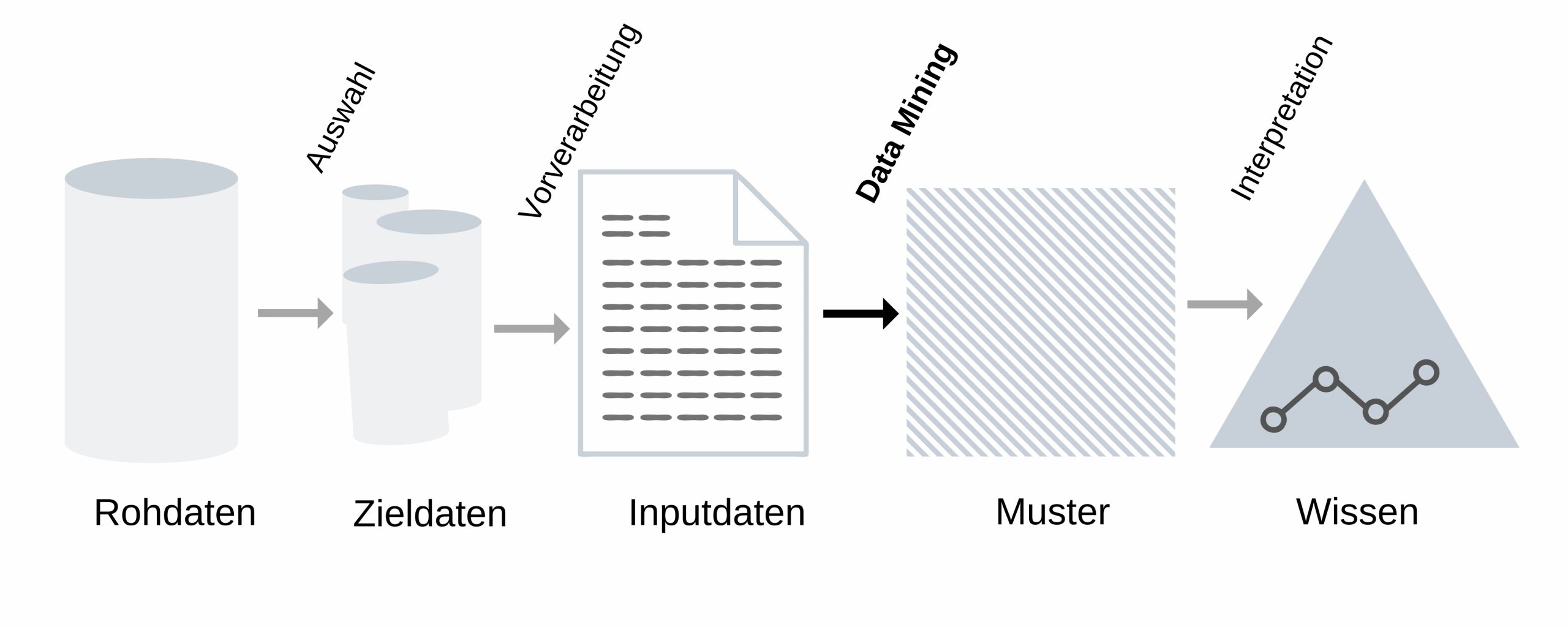
Text Mining, Data Mining, Text Data Mining, Textual Data Mining, Text Knowledge Engineering, Web Mining, Web Content Mining, Web Structure Mining, Web Usage Mining, Content Mining, Literature Mining und sogar Bibliomining[2] – viele Begriffe, die alle das selbe Konzept – teilweise mit unterschiedlichen Schwerpunkten – bezeichnen, welches im Folgenden Text und Data Mining, kurz TDM, genannt werden soll. Grob gesagt ist damit die algorithmusbasierte automatische Analyse digitaler Daten jeglicher Form gemeint.
TDM beinhaltet dabei explizit sowohl die Verarbeitung natürlichsprachiger Texte, sogenannter unstrukturierter Daten, als auch beispielsweise Tabellen und anderer strukturierter Daten, welche unterschiedliche Anwendungsfälle und Herausforderungen mit sich bringen. Dabei gibt es zwei große Aspekte: das Auffinden bereits bekannter Informationen und die Schaffung neuen Wissens durch die Verknüpfung oder Neuinterpretation von Bekanntem.[3]
Ganz allgemein lassen sich Verfahren des TDM in drei große Bereiche aufteilen:
- Musterextraktion (Programm analysiert, welche Daten oft gemeinsam auftreten)
- Segmentierung (Programm gruppiert ähnliche Daten zusammen)
- Klassifikation (Programm teilt Daten vorher bestimmten Klassen zu)
Es lässt sich natürlich noch feiner unterteilen in Regressionsanalysen, Abhängigkeits- oder Abweichungsanalyse, Beschreibung, Zusammenfassung, Prognose, Assoziation etc., was die große Bandbreite an Nutzungsmöglichkeiten des TDM aufzeigt[4], für uns aber gerade zu weit geht, da wir nur den Bereich der Bibliotheken betrachten wollen.
Anwendungsmöglichkeiten für Bibliotheken
Empfehlungssysteme
Eine Möglichkeit der Kataloganreicherung ist die Implementierung eines Empfehlungsdienstes. Dieser analysiert Recherche- und/oder Ausleihdaten, um Nutzenden während ihrer Recherche weitere Medien vorzuschlagen, die relevant für sie sein könnten[5]. Ein solcher Dienst ist BibTip, welcher an der Universität Karlsruhe entwickelt wurde und mittlerweile von vielen wissenschaftlichen und öffentlichen Bibliotheken in Deutschland verwendet wird.
Maschinelle Indexierung
Die inhaltliche Erschließung bietet einen großen Mehrwert bei der Recherche, ist jedoch ein zeit- und personalaufwendiger Aspekt der bibliothekarischen Arbeit. Schon 2009 begann die Deutsche Nationalbibliothek, diese Arbeit mit maschineller Unterstützung durchzuführen. Dabei wurden die in der GND hinterlegten Schlagwörter als Grundlage für die automatische Verschlagwortung mithilfe des Averbis-Programms verwendet.[6]
Herausforderungen
Urheberrecht
TDM war viele Jahre eine rechtliche Grauzone. Unklarheiten bezogen sich unter anderem darauf, ob maschinelle Verarbeitung durch die bestehenden Lizenzverträge abgedeckt war, ob temporäre für die Auswertung erstellte Kopien unerlaubte Vervielfältigung bedeuteten, inwieweit die Ergebnisse Dritten zugänglich gemacht werden durften und vieles mehr.[7] Die Urheberrechtsnovelle 2018 sorgte für mehr Klarheit, indem durch § 60d UrhG explizit die Nutzung von TDM für die wissenschaftliche Forschung erlaubt wurde.
Datenschutz
Datenschutz ist vor allem bei der Verarbeitung personenbezogener Daten wie der Analyse von Ausleih- oder Recherchevorgängen relevant. Im Sinne der Datensparsamkeit dürfen nur so viele Daten erhoben werden, wie erforderlich sind und diese auch nur so lange wie nötig gespeichert werden. Aus Datenschutzgründen werden die Daten deshalb anonymisiert gespeichert und verarbeitet. Dies schränkt beispielsweise die Empfehlungsdienste ein, da so nur die aufgerufenen oder ausgeliehenen Medien während eines einzelnen Vorgangs analysiert werden, diese jedoch nicht mit früheren Vorgängen der selben Person verknüpft werden können.
Formatvielfalt
TDM kann nur funktionieren, wenn die auszuwertenden Daten in geeigneter Form vorliegen. Dabei kann es verschiedene Hürden geben, sowohl rechtlicher Natur, wenn Daten im Besitz von Personen oder Institutionen sind, sowie technischer Natur, wenn Daten nicht in maschinenlesbarer Form vorliegen, oder zu viele verschiedene (inkompatible) Dateiformate genutzt werden.[8]
Ausblick
Schon heute profitieren Bibliotheken von TDM-Anwendungen, besonders Empfehlungsdienste sind verbreitet. Maschinelle Indexierung wird zumindest vereinzelt eingesetzt, bleibt in der Qualität aber noch weit hinter der intellektuellen Erschließung durch Menschen zurück.[9] Aufgrund des technischen Fortschritts und dem immer zuverlässiger werdenden natural language processing darf man hier jedoch hoffnungsvoll in die Zukunft blicken.
Doch Bibliotheken sind nicht nur Anwenderinnen, sondern können und sollten ebenfalls Sorge dafür tragen, dass ihre eigenen Bestände für TDM nutzbar sind. Dies wird erleichtert durch § 60d UrhG, aber sollte auch bei der Aushandlung von Lizenzverträgen, bei der Auswahl der anzubietenden Formate von elektronischen Medien wie auch bei der Retrodigitalisierung beachtet werden.
Quellen
[1] Deutsche Nationalbibliothek (2021): Jahresbericht 2020. S.45. Online unter urn:nbn:de:101-2021051859
[2] Mehler, Alexander; Wolff, Christian (2005): Einleitung: Perspektiven und Positionen des Text Mining. In: LDV-Forum, Jg. 20, Nr. 1, S. 1–18. Online unter urn:nbn:de:0070-bipr-1688
[3] Saffer, Jeffrey; Burnett, Vicki. (2014). Introduction to Biomedical Literature Text Mining: Context and Objectives. In Kumar, Vinod; & Tipney, Hannah (Hg.): Biomedical Literature Mining. New York: HumanaPress, Springer. S. 1–7. Online unter doi.org/10.1007/978-1-4939-0709-0_1
[4] Drees, Bastian (2016): Text und Data Mining: Herausforderungen und Möglichkeiten für Bibliotheken. In: Perspektive Bibliothek, Jg. 5, Nr. 1, S. 49-73. Online unter doi.org/10.11588/pb.2016.1.33691
[5] Mönnich, Michael; Spiering, Marcus (2008): Erschließung. Einsatz von BibTip als Recommendersystem im Bibliothekskatalog. In: Bibliotheksdienst, Jg. 42, Nr. 1, 54–59. Online unter doi.org/10.1515/bd.2008.42.1.54
[6] Uhlmann, Sandro (2013): Automatische Beschlagwortung von deutschsprachigen Netzpublikationen mit dem Vokabular der Gemeinsamen Normdatei (GND). In: Dialog mit Bibliotheken, Jg. 25, Nr. 2, S.26-36. Online unter urn:nbn:de:101-20161103148
[7] Okerson, Ann (2013): Text & Data Mining – A Librarian Overview [Konferenzbeitrag]. Herausgegeben von IFLA. Online unter http://library.ifla.org/252/1/165-okerson-en.pdf (Abruf am 29.01.2022)
[8] Brettschneider, Peter (2021): Text und Data-Mining – juristische Fallstricke und bibliotheksarische Handlungsfelder. In: Bibliotheksdienst, Jg. 55, Nr. 2, S. 104-126. Online unter doi.org/10.1515/bd-2021-0020
[9] Wiesenmüller, Heidrun (2018): Maschinelle Indexierung am Beispiel der DNB. Analyse und Entwicklungmöglichkeiten. In: O-Bib, Jg. 5, Nr. 4, S. 141-153. Online unter doi.org/10.5282/o-bib/2018H4S141-153
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2021/22, Dr. Stefanie Elbeshausen) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.


 Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.
Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.