in den vergangenen Jahrzehnten haben sich Fachgebiete wie Webtechnologie, Medieninformatik, interaktive Medien, Educational Technology oder Datenvisualisierung als eigenständige und zugleich anwendungsorientierte Disziplinen etabliert. Sie prägen maßgeblich, wie Informationen gestaltet, vermittelt und erfahrbar gemacht werden – ob im Web, in der Lehre (z.B. im Studiengang Informationsmanagement) oder in interaktiven Systemen.
Gleichzeitig verändert sich das Verständnis dieser Disziplinen im Zuge technologischer, gesellschaftlicher und kultureller Dynamiken. Insbesondere die zunehmende Verfügbarkeit intelligenter Systeme, generativer KI und interaktiver Real-Time-Technologien erweitert nicht nur die Werkzeugsets dieser Disziplinen, sondern verschiebt auch deren theoretische und gestalterische Grundlagen.
Interdisziplinär und integrativ: Information Design und Creative Technology
Vor diesem Hintergrund gewinnen Creative Technology und Information Design als interdisziplinäre und integrative Fachgebiete an Bedeutung. Sie verbinden kreative Gestaltungspraktiken mit technologischer Expertise und stellen den Menschen als Akteur im physisch-digitalen Raum in den Mittelpunkt. Dabei geht es nicht nur um die technische Umsetzung, sondern auch um Fragen wie z.B. der kritischen Reflektion, gesellschaftlichen Relevanz, Zugänglichkeit, Verständlichkeit, Ethik, Partizipation und Ästhetik.
Gerade im Zeitalter von Creative AI entstehen neue Formen der kollaborativen Gestaltung zwischen Mensch und Maschine, die tradierte Grenzen zwischen Entwickler*innen, Designer*innen und Nutzer*innen auflösen. Dies erfordert neue Kompetenzen – von der kritischen Reflexion über KI-generierte Inhalte bis zur gestalterischen Integration intelligenter Systeme in Lern-, Arbeits- und Kommunikationsprozesse.
Creative Technology und Information Design reagieren auf diese Entwicklungen mit offenen, experimentellen und zugleich praxisorientierten Ansätzen, die technisches Wissen, Designmethodik, Datenkompetenz und gesellschaftliche Verantwortung/Haltung vereinen – mit dem übergeordneten Ziel, eine humane, verstehbare und gestaltbare Zukunft mitzuentwickeln. Auch die Grenzen zwischen physischem und digitalem Raum verschwimmen immer mehr.
Mit Neuerungen des Curriculums im Studiengang Informationsmanagement in 2024 und unter Berücksichtigung gesellschaftlich-technologischen Entwicklungen vereint Information Design als Vertiefung im Studiengang Informationsmanagement klassische Kompetenzen mit neuen, interdisziplinären Anforderungen. Ein zentraler und integrativer Bestandteil von Information Design ist der Einsatz kreativer Technologien (Creative Technology) mit Fokus auf Creative AI.
Durch den kontinuierlichen und raschen Fortschritt in jüngster Zeit auf den Gebieten von Big Data und KI-Technologien sind heutzutage insbesondere Teilbereiche des Informationsmanagements gefragter als je zuvor. Die Rolle des Informationsmanagers und Data Scientists besteht darin, Methoden zur Erfassung und Verarbeitung von Informationen aus unterschiedlichen Datenquellen anzuwenden. Zudem ist er befähigt, Entscheidungen darüber zu treffen, welche Verarbeitungsprozesse zur gezielten Knowledge Discovery aus umfangreichen Datensätzen geeignet sind. Hierbei kommt Data Mining ins Spiel, eine Methode, die die systematische Extraktion relevanter Informationen und Erkenntnisse aus großen Datenmengen umfasst.
In diesem Blogbeitrag werden wir tiefer in das Thema eintauchen und uns einem von vielen Verfahren des Data Mining, genauer der Sentimentanalyse im Text Mining, praxisnah annähern. Dabei bin ich der Ansicht, dass ein tieferes Verständnis erreicht wird, wenn das theoretisch Gelernte eigenständig umgesetzt werden kann, anstatt lediglich neue Buzzwörter kennenzulernen. Ziel ist eine Sentimentanalyse zu Beiträgen auf der Social Media Plattform X (ehemals Twitter) mit Verfahren aus dem Machine Learning bzw. einem passenden Modell aus Hugging Face umzusetzen.
Ihr könnt euch in die Hintergründe einlesen oder direkt zum Coden überspringen.
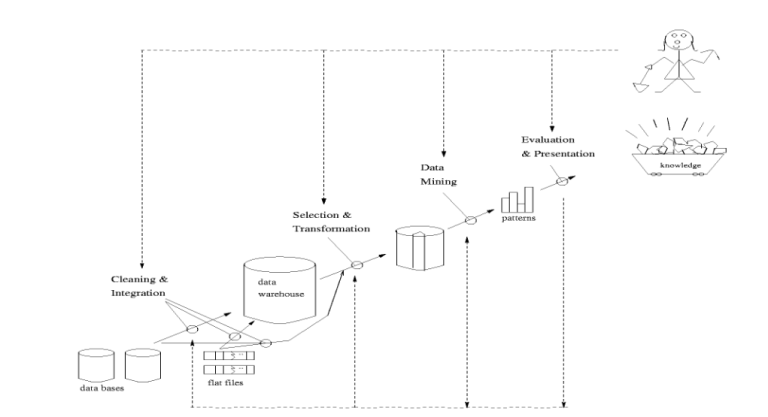
Data Mining umfasst die Extraktion von relevanten Informationen und Erkenntnissen aus umfangreichen Datensammlungen. Ähnlich wird auch der Begriff „Knowledge Discovery in Databases“ (KDD) verwendet. Die Hauptaufgabe besteht darin, Verhaltensmuster und Prognosen aus den Daten zu identifizieren, um darauf basierend Trends zu erkennen und angemessen darauf zu reagieren. Dieser analytische Prozess des Data Mining erfolgt mithilfe von computergestützten Methoden, deren Wurzeln in den Bereichen Mathematik, Informatik und insbesondere Statistik liegen. Data Mining kann als Teilprozess innerhalb des umfassenden Datenanalyseprozesses verstanden werden, der folgendermaßen strukturiert ist:
Datenselektion (Auswahl relevanter Daten aus einer Datenbank)
Datentransformation (Aufbereitung/Konsolidierung der Daten in eine für das Data Mining passende Form)
Data Mining (Prozess gestützt von intelligenten Methoden zum Extrahieren von Daten-/Verhaltensmustern)
Pattern Evaluation (Identifikation interessanter Muster und Messwerte)
Knowledge Presentation (Präsentieren von mined knowledge durch Visualisierung und andere Repräsenationstechniken)
Data Mining als Teilprozess der Knowledge Discovery / Jiawei Han, Data Mining: Concepts and Techniques (2006)
Die Data Mining Verfahren dienen dazu, den Datenbestand zu beschreiben und zukünftige Entwicklungen vorherzusagen. Hierbei kommen Klassifikations- und Regressionsmethoden aus dem statistischen Bereich zum Einsatz. Zuvor ist es jedoch notwendig, die Zielvariable festzulegen, die Daten aufzubereiten und Modelle zu erstellen. Die gebräuchlichen Methoden ermöglichen die Analyse spezifischer Kriterien wie Ausreißer- und Clusteranalyse, die Verallgemeinerung von Datensätzen, die Klassifizierung von Daten und die Untersuchung von Datenabhängigkeiten.
Zusätzlich zu den herkömmlichen statistischen Methoden können auch Deep Learning-Algorithmen verwendet werden. Hierbei werden Modelle aus dem Bereich des Machine Learning unter Anwendung von überwachtem (bei gelabelten Daten) oder unüberwachtem (bei nicht gelabelten Daten) Lernen eingesetzt, um die Zielvariablen möglichst präzise vorherzusagen. Eine wesentliche Voraussetzung für das Vorhersagemodell ist ein Trainingsdatensatz mit bereits definierten Zielvariablen, auf den das Modell anschließend trainiert wird.
ML-Based Text Mining 🤖
Ein Teilbereich des Data Mining, der auch maßgeblich maschinelles Lernen einbezieht, ist das Text Mining. Hierbei zielt das Text Mining darauf ab, unstrukturierte Daten aus Texten, wie beispielsweise in sozialen Netzwerken veröffentlichte Inhalte, Kundenbewertungen auf Online-Marktplätzen oder lokal gespeicherte Textdateien, in strukturierte Daten umzuwandeln. Für das Text Mining dienen oft Datenquellen, die nicht direkt zugänglich sind, weshalb Daten über APIs oder Web-Scraping beschafft werden. Im darauf folgenden Schritt werden Merkmale (Features) gebildet und die Daten vorverarbeitet. Hierbei erfolgt die Analyse der Texte mithilfe von natürlicher Sprachverarbeitung (Natural Language Processing – NLP) unter Berücksichtigung von Eigenschaften wie Wortfrequenz, Satzlänge und Sprache.
Maschinelles Lernen für Datenvorverarbeitung
Die Vorverarbeitung der Daten wird durch Techniken des maschinellen Lernens ermöglicht, zu denen Folgendes gehört:
Tokenisierung: Hierbei werden die Texte in kleinere Einheiten wie Wörter oder Satzteile, sogenannte Tokens, aufgespalten. Das erleichtert die spätere Analyse und Verarbeitung.
Stoppwortentfernung: Häufige Wörter wie „und“, „oder“ oder „aber“, die wenig spezifische Informationen liefern, werden entfernt, um die Datenmenge zu reduzieren und die Analyse effizienter zu gestalten.
Wortstamm- oder Lemmatisierung: Die Formen von Wörtern werden auf ihre Grundformen zurückgeführt, um verschiedene Variationen eines Wortes zu einer einzigen Form zu konsolidieren. Zum Beispiel werden „läuft“, „lief“ und „gelaufen“ auf „laufen“ reduziert.
Entfernen von Sonderzeichen und Zahlen: Nicht-textuelle Zeichen wie Satzzeichen, Symbole und Zahlen können entfernt werden, um die Texte auf die reinen sprachlichen Elemente zu fokussieren.
Niedrige Frequenzfilterung: Seltene Wörter, die in vielen Texten nur selten vorkommen, können entfernt werden, um Rauschen zu reduzieren und die Analyse zu verbessern.
Wortvektorenbildung: Durch Techniken wie Word Embeddings können Wörter in numerische Vektoren umgewandelt werden, wodurch maschinelles Lernen und Analyseverfahren angewendet werden können.
Named Entity Recognition (NER): Diese Technik identifiziert in Texten genannte Entitäten wie Personen, Orte und Organisationen, was zur Identifizierung wichtiger Informationen beiträgt.
Sentimentanalyse: Diese Methode bewertet den emotionalen Ton eines Textes, indem sie versucht, positive, negative oder neutrale Stimmungen zu erkennen.
Textklassifikation: Mithilfe von Trainingsdaten werden Algorithmen trainiert, um Texte automatisch in vordefinierte Kategorien oder Klassen einzuteilen.
Topic Modeling: Diese Methode extrahiert automatisch Themen aus Texten, indem sie gemeinsame Wörter und Konzepte gruppiert.
Insgesamt kann der Text Mining-Prozess als Teil einer breiteren Datenanalyse oder Wissensentdeckung verstanden werden, bei dem die vorverarbeiteten Textdaten als Ausgangspunkt für weitere Schritte dienen.
The effort of using machines to mimic the human mind has always struck me as rather silly. I would rather use them to mimic something better.
In unserem nächsten Abschnitt werden wir auf die Sentimentanalyse eingehen und schrittweise demonstrieren, wie sie mit Hilfe von Modellen auf Hugging Face für Beiträge auf der Plattform X (ehemalig Twitter) durchgeführt werden kann.
In my feelings mit Hugging Face 🤗
Das 2016 gegründete Unternehmen Hugging Face mit Sitz in New York City ist eine Data Science und Machine Learning Plattform. Ähnlich wie GitHub ist Hugging Face gleichzeitig ein Open Source Hub für AI-Experten und -Enthusiasten. Der Einsatz von Huggin Face ist es, KI-Modelle durch Open Source Infrastruktur und Repositories für die breite Maße zugänglicher zu machen. Populär ist die Plattform unter anderem für seine hauseigene Open Source Bibliothek Transformers, die auf ML-Frameworks wie PyTorch, TensorFlow und JAX aufbauend verschiedene vortrainierte Modelle aus den Bereichen NLP, Computer Vision, Audio und Multimodale anhand von APIs zur Verfügung stellt.
Drake Meme by me
Für die Sentimentanalyse stehen uns über 200 Modelle auf der Plattform zur Verfügung. Wir werden im folgenden eine einfache Sentimentanalyse unter Verwendung von Transformers und Python durchführen. Unsere KI soll am Ende Ton, Gefühl und Stimmung eines Social Media Posts erkennen können.
Viel Spaß beim Bauen! 🦾
Let’s build! Sentimentanalyse mit Python 🐍
Zunächst brauchen wir Daten aus X/Twitter. Da im Anschluss auf die neuen Richtlinien die Twitter API jedoch extrem eingeschränkt wurde (rate limits, kostenspielige read Berechtigung) und es nun auch viele Scraping-Methoden getroffen hat, werden wir bereits vorhandene Daten aus Kaggle verwenden.
Elon Musk übernimmt Twitter und ändert den Namen um zu „X“
1. Datenbereitstellung: Kaggle
Wir entscheiden uns für einen Datensatz, der sich für eine Sentimentanalyse eignet. Da wir mit einem Text-Mining Modell in Transformers arbeiten werden, welches NLP verwendet um das Sentiment eines Textes zuordnen zu können, sollten wir uns für einen Datensatz entscheiden, in dem sich Texte für unsere Zielvariable (das Sentiment) befinden.
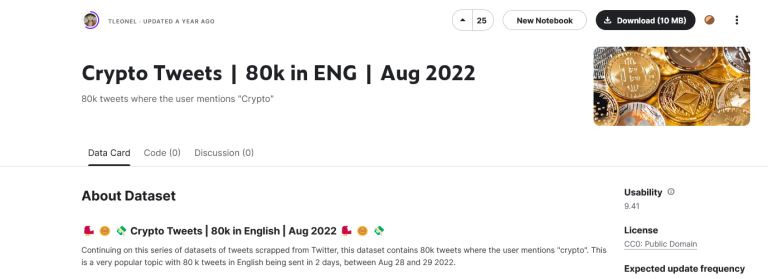
Hier kann ein Datensatz aus Kaggle verwendet werden, in dem über 80 Tausend englische Tweets über das Thema „Crypto“ in dem Zeitraum vom 28.08.2022 – 29.08.2022 gesammelt wurde: 🐦 🪙 💸 Crypto Tweets | 80k in English | Aug 2022 🐦 🪙 💸
Wir laden das Archiv herunter und entpacken die crypto-query-tweets.csv in unseren Projektordner.
2. Zielsetzung und Datenvorverarbeitung: Python + Pandas
Wir wollen in einer überschaubaren Anzahl an Tweets das jeweilige Sentiment zuordnen. Dazu schauen wir uns den Datensatz aus der CSV Datei genauer an. Uns interessieren dabei besonders Tweets von verifizierten Usern. Mit der Pandas Bibliothekt läss sich der Datensatz in Dataframes laden und nach bestimmten kriterien filtern.
wir installieren zunächst per pip-install die gewünschte Bibliothek und importieren diese in unsere Codebase.
pip install pandas
Anschließends lesen wir die CSV-Datei ein und filtern entsprechend unseren Wünschen den Datensatz und geben diesen als Dataframe aus.
import pandas as pd
# CSV Datei lesen
csv_file_path = "crypto-query-tweets.csv"
df = pd.read_csv(csv_file_path, usecols=['date_time', 'username', 'verified', 'tweet_text'])
# Filter anwenden um nur verifizierte User zu erhalten
filtered_df = df[df['verified'] == True]
# Printe Dataframe
print(filtered_df)
Wir erhalten folgende Ausgabe von 695 Zeilen und 4 Spalten:
date_time username verified tweet_text
19 2022-08-29 11:44:47+00:00 RR2Capital True #Ethereum (ETH)\n\nEthereum is currently the s...24 2022-08-29 11:44:45+00:00 RR2Capital True #Bitcoin (BTC)\n\nThe world’s first and larges...
25 2022-08-29 11:44:43+00:00 RR2Capital True TOP 10 TRENDING CRYPTO COINS FOR 2023\n \nWe h...
146 2022-08-29 11:42:39+00:00 ELLEmagazine True A Weekend in the Woods With Crypto’s Cool Kids...
155 2022-08-29 11:42:32+00:00 sofizamolo True Shill me your favorite #crypto project👇🏻🤩
... ... ... ... ...
79383 2022-08-28 12:36:34+00:00 hernanlafalce True @VerseOort My proposal is as good as your proj...
79813 2022-08-28 12:30:15+00:00 NEARProtocol True 💫NEARCON Speaker Announcement💫\n\nWe're bringi...
79846 2022-08-28 12:30:00+00:00 lcx True 🚀@LCX enables project teams to focus on produc...
79919 2022-08-28 12:28:56+00:00 iSocialFanz True Friday.. Heading to Columbus Ohio for a Web 3....
79995 2022-08-28 12:27:46+00:00 BloombergAsia True Bitcoin appeared stuck around $20,000 on Sunda...
[695 rows x 4 columns]
3. Twitter-roBERTa-base for Sentiment Analysis+TweetEval
Nun können wir mit Hugging Face Transformers eine vortrainiertes Modell verwenden, um allen Tweets entsprechende Sentiment Scores zuzuweisen. Wir nehmen hierfür das Modell Twitter-roBERTa-base for Sentiment Analysis, welches mit über 50 Millionen Tweets trainiert wurde und auf das TweetEval Benchmark für Tweet-Klassifizierung aufbaut. Weitere Infos unter dieser BibTex entry:
@inproceedings{barbieri-etal-2020-tweeteval,
title = "{T}weet{E}val: Unified Benchmark and Comparative Evaluation for Tweet Classification",
author = "Barbieri, Francesco and
Camacho-Collados, Jose and
Espinosa Anke, Luis and
Neves, Leonardo",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.findings-emnlp.148",
doi = "10.18653/v1/2020.findings-emnlp.148",
pages = "1644--1650"
}
Wir installieren alle für den weiteren Verlauf benötigten Bibliotheken.
pip install transformers numpy scipy
Die Transformers Bibliothekt erlaubt uns den Zugriff auf das benötigte Modell für die Sentimentanalyse. Mit scipy softmax und numpy werden wir die Sentiment Scores ausgeben mit Werten zwischen 0.0 und 1.0, die folgendermaßen für alle 3 Labels ausgegeben werden:
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
import numpy as np
from scipy.special import softmax
import csv
import urllib.request
Wir schreiben eine Methode zum vorverarbeiten des Texts. Hier sollen später Usernamen und Links aussortiert werden. Außerdem vergeben wir das gewünschte Modell mit dem gewünschten Task (’sentiment‘) in eine vorgesehene Variable und laden einen AutoTokenizer ein, um später eine einfach Eingabe-Enkodierung zu generieren.
# Vorverarbeitung des texts
def preprocess(text):
new_text = []
for t in text.split(" "):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
task='sentiment'
MODEL = f"cardiffnlp/twitter-roberta-base-{task}"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
Als nächstes laden wir das Label Mapping aus TweetEval für das zugeordnete Task ’sentiment‘ herunter. Das Modell für die Sequenzklassifizierung kann nun gespeichert und in der ‚model‘ Variable hinterlegt werden.
# download label mapping
labels=[]
mapping_link = f"https://raw.githubusercontent.com/cardiffnlp/tweeteval/main/datasets/{task}/mapping.txt"
with urllib.request.urlopen(mapping_link) as f:
html = f.read().decode('utf-8').split("\n")
csvreader = csv.reader(html, delimiter='\t')
labels = [row[1] for row in csvreader if len(row) > 1]
# Modell laden
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
model.save_pretrained(MODEL)
Im nächsten Schritt schreiben wir zwei Methoden, die dabei helfen sollen zeilenweise Tweet-Texte zu enkodieren und ein Sentiment Score zu vergeben. In einem Array sentiment_results legen wir alle Labels und entsprechende Scores ab.
# Sentiment Scores für alle Tweets erhalten
def get_sentiment(text):
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
scores = output.logits[0].detach().numpy()
scores = softmax(scores)
return scores
# Sentimentanalyse für jede Zeile im Datensatz anwenden
def analyze_sentiment(row):
scores = get_sentiment(row['tweet_text'])
ranking = np.argsort(scores)
ranking = ranking[::-1]
sentiment_results = []
for i in range(scores.shape[0]):
l = labels[ranking[i]]
s = scores[ranking[i]]
sentiment_results.append((l, np.round(float(s), 4)))
return sentiment_results
Zum Schluss wir das Dataframe um unser Ergebnis erweitert. Hierzu erstellen wir eine neue Spalte ’sentiment‘ und fügen mit der apply-Funktion die Ergebnisse aus unserer vorherigen Methode analyze_sentiement hinzu. Am Ende geben wir unser neues Dataframe in der Konsole aus.
# Ergebnisse in neue Spalte "sentiment" speichern
filtered_df['sentiment'] = filtered_df.apply(analyze_sentiment, axis=1)
# Ausgabe des neuen DataFrames
print(filtered_df)
Wir erhalten ein neues Dataframe mit einer weiteren Spalte in der das Label und die Sentiment-Scores festgehalten werden! 🤗🚀
Den gesamten Code könnt ihr euch auch auf meinem GitHub Profil ansehen oder klonen.
Referenzen
Han, Jiawei (2006). Data Mining: Concepts and Techniques, Simon Fraser University.
Barbieri, F., Camacho-Collados, J., Espinosa Anke, L., & Neves, L. (2020). Tweet Eval: Unified Benchmark and Comparative Evaluation for Tweet Classification. In Findings of the Association for Computational Linguistics: EMNLP 2020, S. 1644-1650. https://aclanthology.org/2020.findings-emnlp.148.
Wartena, Christian & Koraljka Golub (2021). Evaluierung von Verschlagwortung im Kontext des Information Retrievals. In Qualität in der Inhaltserschließung, 70:325–48. Bibliotheks- und Informationspraxis. De Gruyter, 2021. https://doi.org/10.1515/9783110691597.
Künstliche Intelligenz (KI) wird normalerweise damit in Verbindung gebracht, Menschen bei Aufgaben zu unterstützen, die durch Automatisierung besser erledigt werden können. Mit dem fortschreitenden technischen Wandel ist es der KI heutzutage aber nicht nur möglich, fortschriftliche visuelle Effekte in Filmen zu liefern oder den Videoschnitt zu erleichtern, sondern auch Prognosen hinsichtlich des möglichen Erfolgs eines Filmes zu liefern und ganze Storyboards zu verfassen. Die KI entwickelt sich immer mehr zu einer unausweichlichen Kraft, die Filme zukünftig weiter aufarbeiten und stetig verbessern wird. 1
Die KI „Benjamin“ und ihr Kurzfilm „Sunspring“
Hinsichtlich der Verwendung von KI in der Filmproduktion sticht besonders der Science-Fiction-Kurzfilm „Sunspring“ ins Auge, welcher 2016 debütierte. Das Interessante an diesem Film ist, dass er auf den ersten Blick wie viele andere Science-Fiction-Filme wirken mag – bis zur Erkenntnis, dass dessen Drehbuch ausschließlich von einer KI geschrieben wurde, welche sich selbst den Namen „Benjamin“ zuteilte. Es handelt sich hierbei um ein rekurrentes neuronales Netzwerknamens LSTM (long short-term memory), welches vorher mit Drehbüchern verschiedenster Science-Fiction-Filme sowie -Serien gespeist wurde. Trotz oder gerade wegen dieses daraus resultierenden, sehr kuriosen Drehbuchs wurde der Kurzfilm mit drei Schauspielenden gedreht und erhielt dadurch große Aufmerksamkeit. 2
Benjamin kreierte im selben Kurzfilm auch die Musik. Das neuronale Netzwerk wurde hier, ähnlich wie bei der vorangegangenen Vorgehensweise, mit vielen verschiedenen Einflüssen trainiert. In diesem Fall mit über 30.000 verschiedensten Popsongs. 3
Visuelle Effekte und Unterstützung in der Postproduktion
Als weitere Art der Unterstützung wird KI inzwischen im Zuge von weiteren bestehenden Produktionsabläufen sogar in Schnittprogramme implementiert. Dort kann sie unter anderem durch nur einen Klick Audio- oder auch Farbanpassungen vornehmen. 4 Doch nicht nur dort kommt künstliche Intelligenz in der Filmwelt der Postproduktion zum Einsatz. Im Bereich der visuellen Effekte kommt sie gerade beim Rotoskopieren zum Tragen, wo bestimmte Teile des Filmmaterials vom Hintergrund separiert werden. Rotoskopieren ist eine Technik, um animierte Filme und komplexe Bewegungsabläufe in Animationsfilmen realistischer wirken zu lassen. Als Beispiel dient hier das Unternehmen Array. Deren neuronales Netzwerk wurde mit Material gefüttert, welches von Visual Effect Artists arrangiert wurde. Nach ausreichendem Training kann das neuronale Netzwerk sogar ohne Unterstützung durch einen Greenscreen arbeiten. 5
Auch die Computersoftware „Massive“ sticht im Zuge der visuellen Effekte ins Auge. Ursprünglich für die „Herr der Ringe“-Trilogie entwickelt war diese mit Hilfe von künstlicher Intelligenz in der Lage, computergenerierte Armeen zu erstellen sowie realistische Schlachten in enormen Ausmaßen zu simulieren. „Massiv“ erschuf auch andere ikonische Kampfszenen der letzten Jahre, darunter Szenen aus „Game of Thrones“ sowie „Marvel’s Avengers: Endgame“. 6
Podcast „The Daily Charge“: How Lord of the Rings changed filmmaking
Den Erfolg eines Filmes vorhersagen
Ein ganz anderer Bereich, welcher durch KI revolutioniert wird, ist die prognostische Ebene. Denn sie ist inzwischen auch dazu in der Lage, Prognosen über den möglichen Erfolg eines Filmes zu treffen. Zum Beispiel soll die vom Datenwissenschaftler Yves Bergquist entwickelte KI „Corto“ dank künstlicher neuronaler Netze in der Lage sein, den Erfolg eines Films vorherzusagen. Das funktioniert nicht nur durch Analyse verschiedenster Elemente aus dem Film direkt, sondern auch über Daten aus sozialen Medien, wo die KI durch verschiedene Äußerungen die Stimmung sowie den kognitiven Zustand der Nutzenden ermittelt, die verschiedene Medieninhalte zugeführt bekommen haben. 7
Umwandlung alter Filmaufnahmen
Aber Künstliche Intelligenz kann auch für ganz andere Zwecke genutzt werden. So konvertierte ein YouTuber namens Denis Shiryaev eine über 100 Jahre alte Filmaufnahme der französischen Lumière-Brüder aus dem Jahr 1895 durch die Unterstützung einer KI auf das Videoformat 4k sowie die Bildrate auf 60 Bilder pro Sekunde. Somit verfrachtete er den Film durch Unterstützung einer KI technisch ins aktuelle Zeitalter. Hier bestand zwar durchaus noch Verbesserungspotential, allerdings geschah der Vorgang mit wenig Aufwand und wies erneut eindrucksvoll auf, zu was künstliche Intelligenz inzwischen in der Lage ist. 8
Quelle: Vimeo
Ersetzt die KI den Menschen?
Es ist wirklich erstaunlich zu sehen, was für einen großen Einfluss KI in der Welt der Filmproduktion hat und wie viele Bereiche dieser durch sie bereits vereinfacht werden können. Der damit verbundene technische Fortschritt eröffnete die letzten Jahre viele neue innovative Anwendungen in der gesamten Branche und ermöglicht Unternehmen nicht nur, die Effizienz ihrer Arbeitsabläufe zu steigern, sondern auch, ihre Arbeitskosten zu senken und mehr Umsatz zu generieren. 9
Trotz all dieser Vorteile sollte gerade ein Aspekt im Kopf verbleiben:
„KI ist weder nur ein Werkzeug noch ein vollständiger Ersatz für einen Schriftsteller. Man braucht eine Symbiose, um gemeinsam mit der Maschine Kunst zu kreieren.“ 10
Während die künstliche Intelligenz „AlphaZero“ Schach und „MuZero“ als Nachfolger verschiedene Spiele der Spielkonsole Atari meisterte, veröffentlichte die Firma Deepmind die nächste Entwicklungsstufe. Diese KI trägt den Namen DeepNash. AlphaZero meisterte Brettspiele mit klaren Regeln über ein modell-basiertes Training und MuZero, die schwer in Regeln auszudrückenden Atari-Spiele durch ein modell-freies Training. DeepNash hingegen legt sowohl die Spielregeln wie auch das Modell eines Spiels für die Planung fest. Die Besonderheit ist hierbei, dass von der gängigen Methode der Monte-Carlo-Baumsuche abgewichen wird. In der nachfolgenden Tabelle wird die unterschiedliche Komplexität von Brettspielen nochmals deutlich. [1][6]
Schach
Poker
Go 19*19
Stratego
durchschnittliche Züge je Spiel
60
15
300
1000
mögliche Startaufstellungen
1
106
1
1066
Komplexität des Spielbaums
10123
1017
10360
10535
Übersicht der Komplexität unterschiedlicher Brettspiele [3]
Die Nash-Spieltheorie
Das Besondere an DeepNash ist, dass es in den Spielen versucht ein Nash-Gleichgewicht zu erreichen. Hierdurch verläuft das Spiel stabil. Das Nash-Gleichgewicht ist nach dem Spieltheorie-Mathematiker Jon Forbes Nash benannt. Die Theorie folgt der Annahme, dass ein Abweichen der Strategie zu einem schlechteren Ergebnis führt. DeepNash und das Nash-Gleichgewicht folgen also konstant einer Strategie. Infolgedessen hat DeepNash mindestens eine 50%ige Chance zu gewinnen. [1][3]
Die KI DeepNash spielt Stratego
Youtube-Kanal Deepmind: Die erste Stratego Partie von DeepNash gegen einen menschlichen Gegner[2]
Die KI DeepNash nahm als Trainingsgrundlage das Brettspiel Stratego. Das Brettspiel hat im Schnitt 381 Spielzüge und die besondere Schwierigkeit, dass nicht alle Informationen von Beginn an gegeben sind, da mit verdeckten Figuren gespielt wird und der Gegner mit Hilfe von Bluffs i.d.R. seine Taktik verschleiert. Optimale Spielabläufe gibt es nicht, da die Züge inkonsequent sind, das heißt jederzeit ist das Spielergebnis offen. Es wird daher anders als beim Schach nicht in Zügen, sondern in Spielen gedacht. [1][3]
Die optimale Strategie in Stratego erreicht die KI nach 5,5 Milliarden simulierten Partien. [1] DeepNash besiegte damit 97% der derzeitigen Computersysteme und erreichte eine Siegesquote von 84% gegen menschliche Spieler auf der Online-Stratego-Plattform Gravon. DeepNash gelangte damit in die Top 3 der dortigen Bestenliste. Eine weitere Besonderheit der KI stellte die Anwendung menschlicher Spielstrategien dar. So zeigte DeepNash das Bluffen oder auch das Opfern von Figuren als Taktik. Der Algorithmus „Regularised Nash Dynamics“ (R-NaD) wird außerdem für Forschende als OpenSource Download auf Github zur Verfügung gestellt. [1][4][5]
Ausschnitt aus der OpenSource Publikation zu DeepNash[7]
Zukünftige KI Anwendungsfelder
DeepNash ist die nächste Weiterentwicklung, um Menschen in Brettspielen zu übertrumpfen und wird künftig als Grundlage für alltägliche Herausforderungen genutzt werden können. Insbesondere mit unvollständigen Informationen zu arbeiten stellt einen weiteren Meilenstein dar, der in der Lage ist bei komplexen Problemen wie der Optimierung des Verkehrssystems oder auch im Bereich des autonomen Fahrens – wie auch MuZero zuvor – einen Beitrag leisten zu können. [3][4][6]
Quiz
Teste nun dein Wissen über DeepNash in einem kleinen Quiz.
Über die Autoren
Die Autorin Jessica Arnold arbeitet derzeit in der Hochschulbibliothek Emden und studiert berufsbegleitend Informationsmanagement an der Hochschule Hannover.
Der Autor Jan Heinemeyer arbeitet derzeit in der Stadtbücherei Penzberg und studiert berufsbegleitend Informationsmanagement an der Hochschule Hannover.
Beide Autoren eint das private Interesse an Informatik, Gaming, KI und Brettspielen.
DeepMind (2023): DeepNash Stratego game 1. Online verfügbar unter https://www.youtube.com/watch?v=HaUdWoSMjSY, zuletzt aktualisiert am 05.01.2023, zuletzt geprüft am 05.01.2023.
Perolat, Julien u.a. (2022): Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning. Online unter https://arxiv.org/pdf/2206.15378.pdf [Abruf am 07.01.2023]
Komponieren mithilfe von Künstlicher Intelligenz? Zukunftsmusik oder bereits Alltag in der Musikbranche? Wie funktioniert so etwas? Und wer profitiert davon? Mögliche Antworten liefert der folgende Artikel zum Thema „Künstliche Intelligenz in der Musikkomposition“.
Künstliche Intelligenz nimmt in unserer Gesellschaft eine immer zentralere Rolle ein. Sie ist aus Wirtschaft, Medien und Technik nicht mehr wegzudenken und wird in Deutschland u.a. von der Bundesregierung gefördert.1 Auch die Musikbranche wird nachhaltig von KI geprägt und Künstliche Intelligenz befindet sich besonders in der Musikkomposition auf dem Vormarsch.2 Besonders die Komposition von Hintergrundmusik für Social Media, Werbung und Gaming wird in Zukunft von ihr dominiert.3 Aber wie funktioniert das Komponieren von Musik mithilfe von KI eigentlich? Wer arbeitet mit ihr? Steht sie in einem ethischen Konflikt mit menschlichen Musikern und Komponisten und kann sie überhaupt wirkliche Kunst erschaffen? Diesen Fragen widmet sich der folgende Artikel.
Wie funktioniert Komponieren per KI?
Damit eine KI Musik komponieren kann, muss sie zunächst für diesen Einsatzzweck trainiert werden. Sogenannte „Neuronale Netzwerke“ lernen anhand großer Datenmengen (Big Data) die Struktur und Elemente vorhandener Musik. Durch ständige Analyse wird sie immer besser darin, Muster im Songaufbau zu erkennen und ist zu beachtlichen analytischen Leistungen in der Lage.4 Allerdings ist die derart entstandene Musik ohne menschliche Bearbeitung eher Mittelmaß. Das Verfassen von Songtexten und Einspielen der Instrumente sollte daher durch menschliche Hand erfolgen. 5 Künstliche Intelligenz ist deshalb eher als Werkzeug, welches die kompositorische Arbeit erleichtert, zu betrachten.6
Klicken Sie auf die folgende Abbildung, um selbst mit dem Komponieren loszulegen und kreieren Sie mithilfe der KI von Soundraw eigene Songs.
Die Umsetzung computergenerierter Kompositionen ist bereits Realität. Beispielsweise erschuf der Wissenschaftler David Cope mithilfe von KI Werke klassischer Musik, welche Vivaldi, Bach oder Chopin ähneln. Die Aufführung mit einem echten Orchester konnte sogar Fachpublikum täuschen.7 Weiterhin konnten Forscher ein neuronales Netzwerk mithilfe von 45 Songs der Beatles so lange trainieren, bis es ein eigenes Stück entwarf, welches auffällig stark dem Ursprungsmaterial ähnelte. Lediglich der Text zu dem Song „Daddy’s Car“ musste von Menschen geschrieben werden.8
Auch private Nutzer können KI zur Musikkomposition nutzen. So bietet das Berliner Unternehmen „Loudly“ auf ihrer Homepage eine eigens mit ca. zehn Millionen Songs trainierte KI an. Nutzer können somit schnell eigene Lieder generieren lassen. Sie wählen lediglich Genre, Songlänge und Instrumente aus, den Rest übernimmt die KI.9 Auch professionelle Künstler haben sich bereits auf die Zusammenarbeit mit Künstlicher Intelligenz beim Kreieren von Songs spezialisiert. Die Berlinerin Holly Herndon hat auf diese Weise bereits mehrere Alben veröffentlicht.10
Mit der zunehmenden Verbreitung von Künstlicher Intelligenz in der Musikbranche treten auch vermehrt ethische Fragen auf. Verdrängt die Maschine den Menschen? Ist computergenerierte Musik überhaupt Kunst?
Dr. Ralf Weigand, Vizepräsident des Deutschen Komponistenverbandes und Vorsitzender des Aufsichtsrats der GEMA, sieht KI in der Musik mit potenziellen Nachteilen verbunden. Besonders im Bereich der Gebrauchsmusik (Hintergrundmusik für Film, Fernsehen, Social Media etc.) könne KI eine Gefahr für die Jobs der Musikschaffenden bedeuten. Zudem sorge eine Überflutung des Musikmarkts mit computergenerierter Musik eventuell dafür, dass Menschen diese Musik nicht mehr von menschengemachter unterscheiden könnten.11
Rory Kenny, Gründer des eingangs erwähnten Unternehmens „Loudly“, hält dagegen. KI schaffe bereits neue Jobs wie Softwareentwickler oder Informationsspezialisten in der Musikbranche. Weiterhin ermögliche sie auch Menschen ohne Know-how die einfache und zugängliche Produktion von Musik.12
„Das wird eine sehr interessante weitere Demokratisierung des Musikschaffens.“
Rory Kenny13
Auch professionelle Kunstschaffende könnten Vorteile aus der Kooperation mit KI ziehen und Gefallen daran finden.14 Ein Beispiel hierfür ist die bereits erwähnte Holly Herndon.
Kann KI Kunst?
Auch ob Künstliche Intelligenz wahrhaftige Kunst erschaffen kann, ist umstritten. Der Neurowissenschaftler Matthias Bethge sieht KI zwar eher als Werkzeug, spricht ihr allerdings alle Merkmale menschlicher Kreativität zu. Genau wie der Mensch würde sie zunächst Erfahrungen sammeln und Strukturen analysieren, um dann auf dieser Basis etwas Neues zu schaffen. Hans-Christian Ziupa, Gewinner des KI-Musik-Wettbewerbs „Beats & Bits“, sieht jedoch einen zentralen Unterschied zwischen Mensch und KI. Zuhörer würden von Musikern erwarten, dass sie bei der Schöpfung von etwas Neuem mit sich gerungen und dabei eine gewisse emotionale Radikalität entwickelt hätten. Dies sei einer KI nicht möglich.15
Rory Kenny glaubt ebenfalls nicht an den Ersatz menschlicher Musiker durch Maschinen. Musik sei im Kern Storytelling, KI sei jedoch nicht in der Lage Geschichten zu erzählen.16 Goetz Richter, Musiker und Professor der Universität Sydney, sieht KI zudem als abhängig von Menschen und ihren Anweisungen. Es sei komplett verschieden, ob aus bereits bestehenden Werken Eigenschaften abstrahiert, oder schöpferische Werke erschaffen würden. Zu Letzterem sei KI nicht in der Lage. Musik sei kein Ergebnis reiner Analytik, sondern erfordere Neugier, Sinnfindung, Bewusstsein, gelebte Erfahrung, Aufmerksamkeit und Empathie. Dies seien alles Eigenschaften, welche Computern fehlen würden.17 Renate Buschmann, Professorin für digitale Künste der Universität Witten/Herdecke, sieht dies ähnlich. KI habe ihre Stärke im Analysieren von Mustern und dem Kopieren. Kunst sei aber eben das Brechen von Regeln und dem Erschaffen von Unberechenbarkeit.18
Eine weitere komplexe Frage in diesem Kontext ist die, nach der rechtlichen Urheberschaft künstlich komponierter digitaler Produktionen. Sowohl Nutzer der KI (Wahl der Schlagworte bei der Generierung), Künstler (Rahmen und Konzept auf welches KI zugreift), Programmierer (Entwicklung der Software) als auch die Maschine selbst (Komposition des Werkes) kommen als mögliche Urheber infrage.19 Nicht nur diese, sondern auch die oben angesprochenen Themen, werden die Musikbranche in Zukunft mit Sicherheit prägen und beschäftigen.
1 vgl. Die Bundesregierung 2020
2 vgl. Bora 2021
3 vgl. Die Bundesregierung 2020
4 vgl. Bora 2021, Die Bundesregierung 2020 und Richter
5 vgl. Die Bundesregierung 2020
6 vgl. Bora 2021
7 vgl. Richter
8 vgl. Die Bundesregierung 2020
9 vgl. Bora 2021
10 vgl. Die Bundesregierung 2020
11 vgl. Bora 2021
12 vgl. Bora 2021
13 Bora 2021
14 vgl. Buschmann 2022, S.165
15 vgl. Die Bundesregierung 2020
16 vgl. Bora 2021
17 vgl. Richter
18 vgl. Buschmann 2022, S.164-165
19 vgl. Buschmann 2022, S.169
Quellen
Bora, Tereza (2021): Kreative KI. Künstliche Intelligenz verändert die Musikbranche. Online unter [Abruf am 23.11.2022]
Buschmann, Renate (2022): Kann aus KI Kunst werden?. Dialogische Beziehungen mit Künstlicher Intelligenz. In: Schnell, Martin W.; Nehlsen, Lukas (Hg.): Begegnungen mit Künstlicher Intelligenz. Intersubjektivität, Technik, Lebenswelt. Weilerswist: Velbrück Wissenschaft, S. 164-173. Online unter: doi.org/10.5771/9783748934493
Der Autor Hendrik Kuck arbeitet an der Universitätsbibliothek Osnabrück und studiert zurzeit berufsbegleitend Informationsmanagement an der Hochschule Hannover
Die weltweite Musikindustrie ist im Wandel. 2017 wurde erstmals mehr Geld durch Musikstreaming eingenommen als durch den Verkauf von CDs, Schallplatten & Co. Somit liegt auch der Fokus großer Plattenlabel auf dem digitalen Musikmarkt. Führt diese Änderung der Marktsituation auch zu einer Veränderung der Musik als solches?
Früher ging man in einen Plattenladen, um ein Album zu kaufen. Im Anschluss konnte man diese Schallplatte so häufig hören, wie man wollte, der Interpret und das Label sahen kein zusätzliches Geld. Beim Musikstreaming wird heute jeder gehörte Song, jeder Play einzeln bezahlt. Je nach Streamingdienst werden pro 1000 Streams zwischen 70 ct und 27 € ausgezahlt.
Zur Vereinfachung konzentrieren wir uns auf Spotify, welche ca. 4 € für 1000 Streams auszahlen.1 Dabei gilt jedoch: nicht jeder Stream zählt gleich viel. So sind bspw. Streams aus den USA mehr wert als Streams aus Portugal. Außerdem kommt es darauf an, ob der Nutzer ein Spotify-Abo hat oder die werbefinanzierte Gratisversion nutzt.2 Streams werden zudem erst gezählt, wenn der Song mindestens 30 Sekunden langlief.3Diese 4 € gehen zudem nicht vollständig an die Interpreten, da auch die Musiklabels mitverdienen wollen.
Doch welchen Einfluss auf die Musik hat es, wenn Musikschaffende nicht mehr für Verkäufe, sondern für Plays bezahlt werden?
3 Minuten Spiellänge und über 77 Millionen Aufrufe. Mit 22 Nummer-Eins-Hits ist der Rapper Capital Bra erfolgreicher als die Beatles.
Der Algorithmus
Hinter Spotify steckt ein großer Algorithmus, welcher allen Nutzenden auf Basis ihres Hörverhaltens ständig neue Songs empfiehlt. Songs, die in den ersten 30 Sekunden abgebrochen werden, zählen nicht als Play – werden also weder bezahlt noch vom Algorithmus für Empfehlungen berücksichtigt. Ziel der Musikschaffenden sollte es demnach sein, die Hörer:innen direkt zu Beginn des Songs zu fesseln. Dies führt dazu, dass das durchschnittliche Intro eines Songs in den 80er-Jahren noch 20 Sekunden lang war – heutzutage nur noch 5 Sekunden.4
Wie funktioniert eigentlich der Spotify-Algorithmus?
Auch die Länge eines Songs hat sich seit dem Siegeszug der Streamingdienste geändert. In den letzten 20 Jahren sank die durchschnittliche Songlänge um 73 Sekunden. Logisch, denn es macht sowohl finanziell als auch für den Algorithmus einen großen Unterschied, ob ein Song 20 oder 30 Plays in einer Stunde erzielen kann. Hinzu kommt, dass bei längeren Songs die Wahrscheinlichkeit eines Abbruchs größer ist als bei kürzeren Songs. Dies würde dazu führen, dass der Song seltener empfohlen wird.5 Die Anzahl der Songs in den amerikanischen Billboard Top 100-Charts, die kürzer sind als 2:30 Minuten, steigt dadurch seit Jahren stark an.6
Songs werden immer kürzer – auch durch Spotify?
Einfluss von Musikstreaming auf Musikcharts
Seit einigen Jahren werden die Charts von den Streamingzahlen beeinflusst.7 Da dadurch nicht nur eigens ausgekoppelte Singles bewertet werden, kommt es häufiger dazu, dass viele Songs eines Albums die vorderen Plätze belegen, so geschehen u.a. bei Taylor Swift in den USA. Durch die generelle Schnelllebigkeit und die Fixierung auf Plays statt Albumkäufen veröffentlichen viele Musikschaffende zudem (fast) nur noch Singles. Der Deutsch-Ukrainer Capital Bra schaffte es so in nur zweieinhalb Jahren 22 Nummer-Eins-Hits zu veröffentlichen – doppelt so viele wie die Beatles in ihrer gesamten Karriere.8
Belegte gleichzeitig alle Top-10-Plätze in den USA: Taylor Swift
Um bekannt und erfolgreich zu werden ist es für Musikschaffende am wichtigsten, auf den von Spotify erstellten Playlists zu landen. Neben den von Mitarbeiter:innen kuratierten Playlists gibt es auch komplett automatisch vom Algorithmus erstellte (und ständig aktualisierte) Playlists, die ganz auf den Geschmack jedes einzelnen Nutzers zugeschnitten sind. So werden Nutzer mit ähnlichem Musikgeschmack ähnliche Songs empfohlen. Ganz wichtig ist auch hierbei wieder die bekannte 30-Sekunden-Grenze.9
Der perfekte Musikstreaming-Song?
Aber gibt es den perfekten, erfolgsversprechenden Spotify-Song? Nicht wirklich. Zwar hilft es, einen kurzen Song ohne Intro zu haben, eine Garantie ist das jedoch noch lange nicht. Unabhängig davon gilt noch immer: ein Hit ist ein Hit ist ein Hit.
Wie auch in vielen anderen Bereichen der Technik macht auch das Internet of Things (IoT) große Entwicklungsschritte. Dazu gehören auch sogenannte Smart-Home-Systeme, die eine immer weitere Verbreitung in deutschen Haushalten finden. Aus den vielseitigen Anwendungsbereichen ergeben sich neben komfortablen Alltagshilfen auch einige Fragen zur Sicherheit, gerade hinsichtlich Datenschutzes und Künstliche Intelligenz (KI) . In diesem Artikel sollen einige der Sicherheitslücken aufgedeckt und Lösungsansätze erläutert werden.
KI, was ist das eigentlich?
Immer häufiger hört man heutzutage diesen Begriff, aber was zeichnet die KI eigentlich aus? Normalerweise verarbeitet eine Maschine stumpf Daten. Eine KI ist allerdings in der Lage bestimmte Muster zu erlernen, um Entscheidungen auf der Basis von Informationen zu treffen. Dieses Vorgehen nennt man „Machine Learning“. Damit ist eine menschenähnliche kognitive Leistung möglich. Übertragen wir das auf unsere Smart-Home-Systeme bedeutet, dass, die Geräte erlernen unsere Verhaltensmuster und reagieren entsprechend darauf. Der aktuelle technische Stand ermöglicht das noch nicht umfangreich, zielt aber darauf ab. Bislang entscheiden sind das Erkennen und Befolgen von Wenn-Dann-Regeln.
KI im eigenen Zuhause:
@Smartest Home 2020
Smart-Home-Anwendungen bieten einige Vorteile
Smart-Home-Anwendungen haben einige Vorteile zu bieten, andernfalls würden sie sich nicht immer wachsender Beliebtheit erfreuen. Dazu gehören unter anderem:
Erhöhter Komfort: viele Aufgaben müssen nicht mehr selbst erledigt werden, sondern werden bequem von den Smart-Home Anwendungen übernommen. Beispiele hierfür sind z.B. das Saugen von Böden, Rasen mähen oder das automatische Angehen der Kaffeemaschine am Morgen
Vereinfachte Bedienung: durch die Steuerung per App kann man alle Anwendungen aus einer Stelle heraus bedienen, noch einfacher wird das Ganze mit Spracherkennung/Sprachbefehlen
mehr Sicherheit: durch das vernetzte System kann der Besitzer durch Push-Nachrichten auf sein Handy informiert werden, wenn z.B. ein Alarm ausgelöst wird. Gleichzeitig kann ein ausgelöster Alarm dazu führen, dass sich Türen und Fenster verriegeln
Senkung des Energieverbrauch: Geräte sind so programmiert, dass sie möglichst wenig Strom verbrauchen. So kann man z.B. mit Hilfe von einem Timer einstellen, wann das Licht ausgehen soll
Sicherheitslücken in den Systemen
Die komplexe technische Vernetzungbringt auch einige Risiken mit sich, wie sich in den Bereichen des Datenschutzes und der IT-Sicherheit zeigt. Die Smart-Home-Anwendungen sind durchgehend mit dem Internet verbunden. Das macht sie sehr anfällig für den unautorisierten Zugriff durch Hackerangriffe, die sich so den Zugriff zu sämtlichen Geräten in einem Haushalt verschaffen können. Um das zu vermeiden ist das regelmäßige Durchführen von Updates essenziell. Viele Risiken entstehen durch den Anwender selbst. So können fehlende technische Vorkenntnisse und die daraus resultierenden Bedienungsfehler zu schwerwiegenden Sicherheitslücken führen. Daher ist es wichtig, sich mit der Technik der Geräte auseinander zu setzen und ggfs. nochmal die richtige Funktionsweise zu überprüfen. Es stellt sich zudem die Frage, inwiefern die Daten gespeichert und verarbeitet werden. Das ist oft nicht transparent für den Benutzer, und da es sich um sensible personenbezogene Daten wie Kameraaufzeichnungen handelt, ist dieser Punkt nicht zu missachten.
Personenbedingte Fehler
Neben den technischen Fehlerquellen können natürlich auch von Menschenhand erzeugte Fehler Sicherheislücken hervorrufen. Zum einen ist es wichtig, dass sich Anwender vor der Anschaffung intensiv mit der Technik befassen. Oftmals scheitert es an fehlender Planung und das dem Informationsmangel über die Anwendung. Das kann wiederrum zu Anwendungsfehlern führen, die schwerwiegende Sicherheitsmängel bilden können. Wir tendieren oft dazu, zu günstigeren Alternativen zu greifen, was in diesem Fall aber eine fehlende Sicherheitszertifizierung bedeutet und ebenfalls vermehrt Sicherheitslücken aufweißt. Eine noch ausführlichere Hilfe bietet der folgende Artikel: Diese 5 Fehler machen fast alle Smart Home Einsteiger (homeandsmart.de)
Einfacher Schutz im Alltag
Wie kann ich mich also vor den vielfältigen Angriffsmöglichkeiten schützen? Es sind eigentlich ein paar ganz simple Tipps, wie man den Sicherheitsstandard der Smart-Home-Anwendung hochhält:
keinen direkten Internetzugriff: ist ein System direkt mit dem Internet verbunden, ist es leichter für z.B. Hacker dieses zu finden und zu hacken. Am sichersten ist es, denn Zugriff über ein VPN zu nutzen
System regelmäßig aktualisieren: für jedes System gibt es reglemäßig Updates, diese sollte man zeitnah durchführen um Bugs und Fehler in der Software zu beheben.
sichere Passwörter: ein simpler, aber oft missachteter Tipp ist es, ein sicheres Passwort zu vergeben, dass eine Kompination aus Groß- und Kleinschrift, Sonderzeichen und Zahlen beinhaltet. Dieses sollte in regelmäßigen Abständen geändert werden.
unnötige Dienste ausschalten: schalten Sie nicht benötigte Anwendungen aus, denn was nicht läuft, kann nicht angegriffen werden
Fazit: trotz Sicherheitslücken wachsender Trend mit Luft nach oben
Was lässt sich nun abschließend festhalten? Wenn man einige grundlegende Sicherheitsvorkehrungen beachtet und sich selbst mit den technischen Anwendungen befasst bieten Smart-Home-Anwendungen eine gute Möglichkeit sich den Alltag einfacher zu gestalten. Smart-Home-Anwendungen stehen noch relativ am Anfang ihrer technischen Möglichkeiten und sind auch noch lange kein fester Bestandteil in einem durchschnittlichen Haushalt. Auch die Zukunftserwartungen sind noch nicht erfüllt worden.
«Wir glaubten damals, dass es eine allmächtige, zentrale Intelligenz geben werde, die je nach Stimmung eine automatische Lichtauswahl trifft, ohne unser Zutun Essen für den Kühlschrank nachbestellt und so weiter. Diese Vision ist nicht eingetreten, zumal die Installation und Konfiguration einer einzigen, zentralen Lösung viel zu komplex wäre. Stattdessen gibt es heute viele partielle Lösungen, beispielsweise für die Beleuchtung, die Soundanlagen oder die Sicherheit.»
Baumann, Melanie (2020): Diese 5 Fehler machen fast alle Smart Home Einsteiger. Smart Home Anfängerfehler und wie sie Einsteiger vermeiden. Zuletzt aktualisiert am 02.02.2020. Online unter https://www.homeandsmart.de/fehler-smart-home-einsteiger [Abruf am 24.01.2023]
Hüwe, Peter ; Hüwe, Stephan (2019): IoT at Home. Smart Gadgets mit Arduino, Rasperry Pi, ESP8266 und Calliope entwickeln. München : Carl Hanser Verlag
Die zunehmend komplexe Gestaltung digitaler Angebote und Dienste in den letzten Jahren hat starke Konzentrationstendenzen in der Datenökonomie verursacht. Einige Großunternehmen sammeln beträchtliche Datenmengen, kombinieren diese und werten die neuen Daten aus.[1] Dadurch können anonymisierte Daten häufig re-identifiziert werden.[2] Was hat das nun mit digitaler Datenanalyse zu tun?
In diesem Fachbeitrag wird auf die Nutzung digitaler Daten eingegangen. Es wird erklärt was unter digitaler Datenanalyse und Datentransparenz verstanden wird und wie diese Einfluss auf die Arbeitswelt haben. Weiterhin wird betrachtet, wie der Staat Einfluss auf die Transparenz von Daten nimmt.
Digitale Daten werden über alle elektronischen Endgeräte verknüpft
Die Nutzung digitaler Daten
Privatpersonen, Unternehmen und der Staat. Jeder Akteur der Marktwirtschaft verwendet täglich digitale Daten. Aber was sind digitale Daten? Bei digitalen Daten handelt es sich um digitale Dokumente und Medieneinheiten, die diskret oder indiskret Informationen darstellen. Diese Informationen können sowohl personenbezogene als auch nicht personenbezogene Daten sein. Wie kann nun mit diesen Daten umgegangen werden? Die Datennutzung ist immer eng verbunden mit Fragen zum verantwortungsvollen Umgang mit Daten und den sich dauerhaft weiterentwickelnden Technologien. Besonders wichtig sind dabei die Einhaltung von Gesetzen, wie die DSGVO, und die Orientierung an ethischen Werten. „[N]icht alles, was technisch möglich ist, [ist] auch ethisch vertretbar“[3], denn es gibt unter anderem Möglichkeiten über die Verfahren Profiling und Scoring Aussagen über das Verhalten sowie die Präferenzen einzelner Personen machen zu können und diese zu beeinflussen.[4]
Digitale Datenanalyse und Datentransparenz
Digitale Datenanalysen helfen, komplexe Sachverhalte schnell und transparent darzustellen. Dies geschieht durch das Erkennen von Zusammenhängen, Abhängigkeiten und Ungereimtheiten in Daten. Zur Datenanalyse wird vermehrt auf maschinelles Lernen anstatt auf Menschen zurückgegriffen, da bei der Analyse großer Datenmengen in kürzerer Zeit bessere Ergebnisse erzielt werden können.[5]
Transparenz setzt voraus, dass Daten fehlerfrei, vollständig sowie zeitgerecht veröffentlicht und zugänglich sind. Zugleich dient sie als Voraussetzung für die Überwachung der Datennutzung. Dies wird möglich durch die Kontrolle der Datenverwendung durch alle Personen, die Zugang zu den jeweiligen Daten haben und die Fähigkeiten zur differenzierten Datenanalyse besitzen.[6]
Einfluss der digitalen Datenanalyse auf die Arbeitswelt
Digitale Datenanalyse und Datentransparenz haben einen bedeutenden Einfluss auf die Arbeitswelt. Durch die Verfügbarkeit von genauen und umfassenderen Daten können Unternehmen datengetriebene Entscheidungen treffen. Das bedeutet, dass sie Entscheidungen auf der Grundlage von Daten und nicht nur auf Intuition oder Vermutungen treffen. Dies führt zu besseren Entscheidungen, die auf den tatsächlichen Bedürfnissen und Trends des Marktes basieren.[7]
Darüber hinaus können Unternehmen durch die Verwendung von Datentransparenztools ihre Geschäftsprozesse besser überwachen und regulieren. Dies bedeutet, dass sie in Echtzeit Einblicke in ihre Prozesse erhalten und mögliche Probleme schnell erkennen und beheben können. Somit können die Effizienz gesteigert und Kosten eingespart werden. Außerdem sorgt dies für eine bessere Kontrolle und Überwachung von Geschäftsprozessen. Zusätzlich ermöglicht digitale Datenanalyse und die Nutzung von Datentransparenztools Unternehmen dazu, große Mengen an Daten schneller und effizienter zu analysieren. Dies führt zu einer besseren Entscheidungsfindung und höheren Effizienz.
Insgesamt hat die Verwendung von digitaler Datenanalyse und Datentransparenz einen signifikanten Einfluss auf die Arbeitswelt, indem sie Effizienz, datengetriebene Entscheidungen und Überwachung von Geschäftsprozessen verbessern.[8]
Die Rolle des Staates in der digitalen Datenanalyse
Der Staat spielt eine wichtige Rolle bei der Steuerung der Verwendung von Datenanalyse und Datentransparenz. Durch Gesetze und Regulierungen, wie die Datenschutzgrundverordnung (DSGVO) in Europa, wird sichergestellt, dass persönliche Daten sicher und geschützt sind und das Unternehmen verantwortungsvoll mit diesen Daten umgehen.[9]
Zudem legt der Staat Richtlinien fest, die Unternehmen verpflichten, bestimmte Standards bei der Datensammlung, -verarbeitung und -nutzung einzuhalten. Dies garantiert, dass Daten genau und verlässlich sind und die Datentransparenz ein hohes Niveau hat. Der Staat ist auch verantwortlich für die Überwachung der Einhaltung dieser Gesetze und Regelungen durch Unternehmen. Dies kann durch Regulierungsbehörden oder durch Strafen und Bußgelder bei Verstößen geschehen.[10]
Darüber hinaus sind staatliche Stellen selbst oft Nutzer von Datenanalyse, beispielsweise für staatliche Überwachungs- und Überprüfungszwecke oder für die Erstellung von Statistiken.[11] Hierbei muss jedoch sichergestellt werden, dass dies im Rahmen der Gesetze und Regulierungen geschieht und die Datenrechte der Bürger geschützt bleiben. Zudem kann der Staat Regulierungen erlassen, die den Zugang zu bestimmten Daten einschränken, um die Privatsphäre und den Schutz sensibler Daten zu garantieren. Dies garantiert, dass Daten nicht missbraucht werden und das die Transparenz der Daten aufrechterhalten wird. Weiterhin können Unternehmen vom Staat verpflichtet werden, Regeln für den Umgang mit Daten und den Schutz persönlicher Informationen einzuhalten.[12]
Beispielsweise kann der Staat Gesetze erlassen, die Unternehmen verpflichten, über die Daten, die sie sammeln, transparent zu informieren. Dies kann die Verwendung von Daten, die Art und Weise, wie sie gesammelt werden und wer Zugang dazu hat, umfassen.[13] Außerdem muss der Staat auf die Entwicklungen im Bereich der digitalen Datenanalyse reagieren und gegebenenfalls Gesetze und Regulierungen anpassen, um sicherzustellen, dass sie weiterhin gültig und wirksam bleiben.[14]
Fazit
Zusammenfassend ist zu erkennen, dass sowohl digitale Datenanalyse als auch Datentransparenz für sich genommen bedeutend für jeden Akteur der Marktwirtschaft sind. Besonders deutlich wird allerdings auch, dass die Datenanalyse einen sichtbaren Einfluss auf die Transparenz von Daten nimmt. Nur wenn Daten durch Analyseverfahren verstanden werden, können sie auch verwendet werden. Sie sind dann transparent. Dabei darf die Notwendigkeit von Gesetzen und Regulierungen nicht vernachlässigt werden, um die Rechte des Einzelnen zu schützen.
Begriffsdefinitionen
Nicht personenbezogene Daten
Als nicht personenbezogene Daten werden alle Daten bezeichnet, die keine personenbezogenen Daten aufweisen oder stark genug anonymisiert worden sind, dass die Anonymisierung nicht rückgängig gemacht werden kann.[15]
Personenbezogene Daten
Personenbezogenen Daten bezeichnen alle Daten und Informationen, die auf eine lebende identifizierte oder identifizierbare Person verweisen. Darüber hinaus werden auch pseudonymisierte Daten, anonymisierte Daten, die re-identifiziert werden können, als personenbezogene Daten bezeichnet.[16]
Profiling
Bei dem Verfahren Profiling findet das Sammeln und Verknüpfen von personenbezogenen Daten zu persönlichen Profilen von einzelnen Menschen statt. Diese Profile werden dann zur Auswertung, Bewertung, Analyse und Vorhersage spezifischer Merkmale von Personen verwendet.[17]
Scoring
Das statistisch-mathematische Verfahren Scoring ordnet dem Profil eines Menschen oder Unternehmens einen Wert zu. Dieser Wert zeigt die Intensität der Ausprägung verschiedener Merkmale und wird zur Kategorisierung und Klassifizierung verwendet.[18]
[1] Vgl. Die Bundesregierung (2021), S. 6 [2] Vgl. Günter (2020), S. 62 [3] Die Bundesregierung (2021), S. 7 [4] Vgl. Ebd., S. 7 [5] Vgl. Lucke; Gollasch (2022), S. 96 [6] Vgl. Günter (2020), S. 201 [7] Vgl. Kämpf, Vogl, Boes (2022) [8] Vgl. Küng, Keller, Hofer (2022) [9] Vgl. Wewer (2022) [10] Vgl. Kubicek (2020) [11] Vgl. Fulko (2021) [12] Vgl. Fischer, Kraus (2020) [13] Vgl. Kubicek (2020) [14] Vgl. Fischer, Kraus (2020) [15] Vgl. Europäische Kommission (2014) [16] Vgl. Ebd. [17] Vgl. Die Bundesregierung (2021), S. 116 [18] Vgl. Ebd., S. 116
Über die Autorinnen
Luisa Rabbe ist im dritten Semester des Studienganges Informationsmanagement immatrikuliert. Das Studium absolviert diese an der Fakultät III in der Abteilung Information und Kommunikation an der Hochschule Hannover. Die Autorin ist 24 Jahre alt und wohnhaft in Hannover.
Emelie Rademacher ist im dritten Semester des Studienganges Informationsmanagement immatrkuliert. Das Studium absolviert diese an der Fakultät III in der Abteilung Information und Kommunikation an der Hochschule Hannover. Gleichzeitig arbeitet sie als Minijobberin bei der Edeka Cramer GmbH im Bereich Backwaren Bedienung. Die Autorin ist 20 Jahre alt und wohnhaft in Hannover.
Fischer, Caroline; Kraus, Sascha (2020): Digitale Transparenz. In: Klenk, Tanja; Nullmeier, Frank; Wewer, Göttrik (Hg.): Handbuch Digitalisierung in Staat und Verwaltung. Wiesbaden: Springer VS, S.159-170
Fulko, Lenz (2021): Der digitale Staat – Transparenz als Digitalisierungsmotor. Argumente zu Marktwirtschaft und Politik, No. 155. Berlin: Stiftung Marktwirtschaft
Kämpf, Tobias; Vogl, Elisabeth; Boes, Andreas(2022): Inverse Transparenz. Ein soziologischer Perspektivenwechsel für einen nachhaltigen Umgang mit Transparenz in der digitalen Arbeitswelt. In: Boes, Andreas; Hess, Thomas; Pretschner, Alexander; Kämpf, Tobias; Vogl, Elisabeth (Hg.): Daten-Innovation-Privatheit. Mit Inverser Transparenz das Gestaltungsdilemma der digitalen Arbeitswelt lösen. München: ISF München, S.24-33
Kubicek, Herbert (2020): Informationsfreiheits- und Transparenzgesetze. In: Klenk, Tanja; Nullmeier, Frank; Wewer, Göttrik (Hg.): Handbuch Digitalisierung in Staat und Verwaltung. Wiesbaden: Springer VS, S.171-186
Küng, Marco; Keller, Daniel F.; Hofer, Nicolas(2022): Transport – Im Wandel der Corona-Kriese. In: Luban, Katharina; Hänggi, Roman (Hg.): Erfolgreiche Unternehmensführung durch Resilienzmanagement. Branchenübergreifende Praxisstudie am Beispiel der Corona-Kriese. Berlin: Springer Vieweg, S. 181-196
Lucke, Jörn von; Gollasch, Katja (2022): Offene Daten und offene Verwaltungsdaten – Öffnung von Datenbeständen. In: Hünemohr, Holger; Lucke, Jorn von; Stember, Jürgen; Wimmer, Maria A. (Hg.): Open Government. Offenes Regierungs- und Verwaltungshandeln – Leitbilder, Ziele und Methoden. Wiesbaden: Springer Gabler, S. 49-73
Müller, Günter (2020): Protektion 4.0: Das Digitalisierungsdilemma. Die blaue Stunde der Informatik. Berlin: Springer Vieweg
Wewer, Göttik (2020): Datenschutz. In: Klenk, Tanja; Nullmeier, Frank; Wewer, Göttrik (Hg.): Handbuch Digitalisierung in Staat und Verwaltung. Wiesbaden: Springer VS, S.187-198
Im Zuge der Corona-Pandemie hat das Thema E-Learning an Hochschulen weiter an Bedeutung gewonnen. Das erfordert von den Lehrenden die Weiterentwicklung alter und Umsetzung neuer digitaler Lehrmethoden. Eine Methode ist die Vermittlung von Lehrinhalten mithilfe interaktiver Videos. Doch wie setze ich diese ein und was sind überhaupt interaktive Videos? Mehr dazu erfahren Sie in diesem Beitrag.
Interaktive Videos bestehen aus zwei grundlegenden Komponenten: dynamische und audiovisuelle Medien (z.B. Videos oder Animationen) als Basis sowie darin eingebundene aktivierbare und zeitgestempelte Multimedia-Elemente (z.B. digitale Texte, Bilder, Graphiken, Links, Referenzen, Audio- oder Videodateien). Durch die Einbettung dieser Elemente wird die lineare Struktur eines Videos aufgebrochen, was dem Betrachtenden eine aktive Auseinandersetzung mit dem Inhalt – je nach Bedürfnis bzw. Wissensstand – ermöglicht. Im Kontext eines interaktiven Videos wird der passive Betrachtende also zum aktiven Nutzenden.
Geht man vom Einsatz interaktiver Videos im Bereich des E-Learning aus, kann man zwischen drei grundlegenden, kombinierbaren Formen differenzieren:
Interaktive Videos als Videos mit verzweigenden Handlungssträngen
Interaktive Videos als Videos mit bereitgestellten Zusatzinformationen
Interaktive Videos mit integrierten Zusatzfunktionen (Vgl. zu diesem Abschnitt: Lehner, Siegel 2009, S. 44-45)
Interaktive Videos mit verzweigenden Handlungssträngen
Interaktive Videos mit verzweigenden Handlungssträngen ermöglichen den Nutzenden, den weiteren Verlauf des Videos aktiv und je nach Bedürfnis zu beeinflussen. Im Kontext von E-Learning gewinnt diese Form des interaktiven Videos beispielswiese an Bedeutung, wenn es um die Vermittlung wichtiger Grundlagen zu einem bestimmten Thema geht: Der Lernende kann im Verlauf des Videos dann selbst entscheiden, ob er bereits zum nächsten Themenschwerpunkt übergehen möchte oder weitere, vertiefendere Informationen zum gerade dargestellten Themenschwerpunkt benötigt. (Vgl. zu diesem Abschnitt: Lehner, Siegel 2009, S. 45)
Interaktive Videos mit bereitgestellten Zusatzinformationen
Mit den bereitgestellten Zusatzinformationen sind die Möglichkeiten gemeint, bewegtes Bildmaterial mit wichtigen Informationen in Form von Annotationen und Kommentaren anzureichern. Sowohl die Erstellenden interaktiver Videos, als auch die Nutzenden können den dargestellten Inhalt durch Videoannotationen erweitern oder Kommentare beifügen, die zur Diskussion anregen. Studierende haben hierdurch außerdem die Möglichkeit, sich mit inhaltlichen Fragen an die Lehrenden zu wenden. Interaktive Videos dienen in diesem Sinne als „aktive und soziale Austauschplattform“ (Georg-August-Universität Göttingen o.J.) für Lehrende und Lernende – gerade beim E-Learning ist dieser Punkt nicht zu unterschätzen. (Vgl. zu diesem Abschnitt Lehner, Siegel 2009, S. 46)
Interaktive Videos mit integrierten Zusatzfunktionen
Unter den integrierten Zusatzfunktionen kann man im E-Learning Bereich beispielsweise die Möglichkeit fassen, Fragen verschiedenster Fragetypen oder Aufgabenstellungen im Video zu implementieren. Die Lehrenden können mithilfe dieser Zusatzfunktionen eine aktive Auseinandersetzung mit den dargestellten Inhalten fördern. Den Studierenden dienen Sie außerdem zur Einschätzung ihres Wissensstandes.
Ein interaktives Video
Die Umsetzung eines interaktiven Videos kann beispielsweise so aussehen:
2. Was können interaktive Videos in der Hochschullehre leisten?
Interaktive Videos können folgende Aspekte im Lehrprozess der Lehrenden und im Lernprozess der Studierenden erleichtern oder begünstigen:
Asynchrones Lernen (zeit- und ortsunabhängig)
Individuelle Gestaltung und Kontrolle des Lernprozesses
Förderung des Verstehens und Erinnerns der Lerninhalte durch visuelle Darstellung
Förderung des analytischen Denkens (Anwenden, Analysieren, Beurteilen und Gestalten) durch aktive Vermittlung von Lerninhalten
Förderung der intensiveren, inhaltlichen Auseinandersetzung und Entwicklung eigener Ideen durch aktives Erarbeiten der Lerninhalte und Filterung wichtiger Informationen (z.B. durch Annotationen, Kommentare, Fragen)
Anstoß zur Diskussion, sozialer Interaktion und Austausch: aktiver Reflektions- und Diskussionsprozess trotz räumlicher Distanz
Möglichkeit zum Feedback und zur Überprüfung des Lernerfolges
Umsetzung aufwendiger Formen der Wissensüberprüfung (z.B. Einbettung von Fragen verschiedener Fragetypen)
Spaß am Lernen durch kreative Lehrmethode
3. Welche Herausforderungen bieten interaktive Videos in der Hochschullehre?
Interaktive Videos können Lehrende und Lernende vor verschiedene Herausforderungen stellen, die es von der Hochschule zu berücksichtigen gilt. Eine Überwindung der Herausforderungen und die Lösung von Problemen kann nur in Zusammenarbeit und im gemeinsamen Austausch erfolgen.
Technische Herausforderungen und Infrastruktur
Um das E-Learning im Allgemeinen sowie das Lehren und Lernen mit interaktiven Videos überhaupt anbieten zu können, ist es notwendig, dass Hochschulen die entsprechende technische Infrastruktur bereitstellen. Diese kann die Lehrenden maßgeblich bei der Gestaltung ihrer Lehre unterstützen und sie darin bestärken auch auf digitale Lehrmethoden zu setzen. Optimal ist die Bereitstellung von Lernplattformen, mit deren Hilfe internetbasierte Lernmaterialen für E-Learning erstellt werden können. Im Umgang mit solchen Lernplattformen müssen Lehrende dann entsprechend geschult werden.
Didaktische Herausforderungen
Die Umsetzung didaktisch guter, interaktiver Videos stellt hohe Ansprüche an die Lehrenden. Die Videos müssen so gestaltet werden, dass sie die Studierenden in ihrem Lernprozess unterstützen und motivieren. In diesem Zusammenhang müssen Zusatzinformationen präzise formuliert und Zusatzfunktionen sinnvoll genutzt werden. Das interaktive Video soll die Studierenden zur intensiven Auseinandersetzung mit den Inhalten animieren und zur Diskussion anregen. In diesem Zuge sollte eine didaktische Beratung oder Fortbildung für die Lehrenden in Betracht gezogen werden. (Vgl. zu diesem Abschnitt: Krüger, Steffen, Vohle 2012, S. 206-209)
Probleme des Lernens mit Video
Dazu gehören u.a. technische Probleme, aber auch Studierende, die aufgrund mangelnder technischer Ausstattung oder Begebenheiten zu Hause keine Möglichkeit haben adäquat am E-Learning teilzunehmen. Des Weiteren muss berücksichtigt werden, dass nicht alle Studierenden von digitalen Lehrmethoden profitieren können, sondern den traditionellen Unterricht vorziehen. Außerdem kann die „Gefahr der Individualisierung“ (Dubs 2019, S. 35) bestehen, wenn Studierende sich ausschließlich auf das Video konzentrieren, die Interaktion in der Lerngruppe aber ansonsten ablehnen.
4. Für welche Art von Lehrinhalten eignen sich interaktive Videos?
Interaktive Videos eignen sich für…
Selbstlerneinheiten
die Einführung neuer Themen
die visuelle Darstellung von Lerninhalten
die Überprüfung des bisherigen Wissensstandes
die Darstellung/Behandlung praxisnaher Themen
die aktive Gestaltung einer Vorlesungsaufzeichnung
die aktive Gestaltung einer asynchronen Lehreinheit
die Anregung eines Diskussionsprozesses zwischen Studierenden
die Analyse von Aufzeichnungen (z.B. Vorträge, Präsentationen, Filmsequenzen) (Vgl. Georg-August-Universität Göttingen o.J.)
5. Wie erstelle ich ein interaktives Video? (Am Beispiel von ILIAS)
ILIAS (Integriertes Lern-, Informations- und Arbeitskooperations-System) ist ein Open Source Learning Management System, das bereits an vielen Hochschulen zum Einsatz kommt. Mithilfe der Lernplattform ILIAS können Lern- und Übungsmaterialen leicht erstellt und den Lernenden zur Verfügung gestellt werden. (Vgl. zu diesem Abschnitt: ILIAS 2022)
Im Kontext der Erstellung interaktiver Videos bietet ILIAS das Interaktive Video Plug-In an, welches die Gestaltung und Bereitstellung interaktiver Videos ermöglicht. Ein Tutorial über die Möglichkeiten zur Gestaltung von interaktiven Videos mit ILIAS finden Sie hier:
Bundeszentrale für politische Bildung / bpb (2015): Was ist eigentlich E-Learning?. Video publiziert am 11.09.2015 auf Youtube. Online unter https://www.youtube.com/watch?v=XHwDtmSFrOA [Abruf am 28.12.2022]
Dubs, Rolf (2019): Die Vorlesung der Zukunft. Theorie und Praxis der interaktiven Vorlesung. Opladen, Toronto: Verlag Barbara Budrich
Krüger, Marc; Steffen, Ralf; Vohle, Frank (2012): Videos in der Lehre durch Annotationen reflektieren und aktiv diskutieren. In: Csanyi, Gottfried; Reichl, Franz; Steiner, Andreas (Hg.): Digitale Medien – Werkzeuge für exzellente Forschung und Lehre. Münster: Waxmann, S. 198-210
Lehner, Franz; Siegel, Beate (2009): E-Learning mit interaktiven Videos – Prototypisches Autorensystem und Bewertung von Anwendungsszenarien. In: Schwill, Andreas & Apostolopoulos, Nicolas (Hg.): DeLFI 2009 – 7. Tagung der Fachgruppe E-Learning der Gesellschaft für Informatik e.V.. Bonn: Gesellschaft für Informatik e.V., S. 43-54
Universität Stuttgart (2022): Interaktives Video in ILIAS. Video publiziert am 07.02.2022 auf Youtube. Online unter https://www.youtube.com/watch?v=jDrn2O7KcVo [Abruf am 11.12.2022]
SEO ist undenkbar ohne User Experience! Warum? Das werden wir Ihnen in diesem Blogbeitrag aufklären. Viele glauben, dass SEO und User Experience zwei getrennte Dinge sind, jedoch haben sie viel mehr miteinander zu tun als man denkt. Vorerst wollen wir auf die Begrifflichkeiten SEO (Search Engine Optimization) und User Experience (Benutzererfahrung) eingehen, um ein klares Verständnis darüber zu haben.
SEO rückt die User und nicht die Suchmaschinen, ins Zentrum. Bedeutet also, die Optimierung der User-Erfahrung wird in den Fokus gestellt und nicht die Suchmaschinenoptimierung.
Um das Nutzungserlebnis so schön wie möglich zu gestalten, muss die Journey ganz betrachtet werden. Dies beginnt schon mit der Google-Suche, indem der Nutzer seine Anfrage beginnt. Das Suchergebnis entscheidet, ob der Nutzer auf der Website landet und ob er sie weiter nutzen möchte. Die Qualität und Darstellung, welche den Nutzer weiter anregt oder abschreckt, sind sehr wichtige Aspekte in der Erstellung.
1. User Experience & SEO
UX – User Experience
Die User Experience beschreibt, wie sich Menschen beim Navigieren auf einer Website, bei der Nutzung einer mobilen App oder bei der Interaktion mit digitalen Produkten oder Diensten eines Unternehmens fühlen. Dazu gehören die Benutzeroberfläche, Benutzerfreundlichkeit und Benutzerforschung.
Was umfasst User Experience alles?
Designs für außergewöhnliche User Experience zielen darauf ab, den Endanwender glücklich zu machen. Daher muss ein Unternehmen ein klares Verständnis über die Bedürfnisse und Prioritäten der Nutzer haben, bevor ein UX realisiert werden kann. Anhand einer detaillierten Benutzerforschung sind UX-Designer in der Lage, die Funktionalität und den Wert jedes Aspekts der UX zu bewerten.
2. SEO – Suchmaschinenoptimierung
Englisch: „Search Engine Optimization“
SEO steht als Abkürzung für Search Engine Optimization und bezeichnet alle Maßnahmen technischer und inhaltlicher Natur, um die Rankings einer Website und deren Sichtbarkeit in den Ergebnislisten von Suchmaschinen zu verbessern.
Die Suchmaschinenoptimierung kann aufgeteilt werden in Onpage SEO und Offpage SEO und ist Teil des Online Marketings. Es dient der Verbesserung der User Experience. Hier könnt ihr euch die Basics von SEO auch einfach angucken:
SEO Basics
Onpage und Offpage
Diese zwei großen Bereiche definiert die SEO. Maßnahmen, die auf der Website selbst durchgeführt werden, betrifft die Onpage-Optimierung. Bereiche außerhalb der Website werden durch die Offpage-Optimierung gedeckt.
Onpage
Technische Optimierung
Verbesserung von Texten mit relevanten Begriffen und Mehrwertbeschaffung für die User
Seite wird durch einfügen von Bildern oder Meta-Angaben besonders relevant für ein Thema
Technische Optimierung
Optimierungen am Server, Quellcode oder CMS
Mobile Optmierung
Optimierung einer Website für mobiles Endgerät
Offpage
Linkaufbau
Maßnahmen zur Steigerung der Domain-Popularität, zum Erhalt von mehr Backlinks
Trust der Website soll erhöht werden
Steigerung der Sichtbarkeit
Content Marketing und Social Media kann Sichtbarkeit im Netz verbessern
3. Ziele von SEO
Das Erreichen von Top-Positionen in den Suchergebnissen ist das Ziel der Search Engine Optimization. Je nach Art der Website können jedoch noch weitere Ziele definiert werden, wie zum Beispiel:
höhere Umsätze und mehr Gewinn bei Online Shops und anderen E-Commerce-Websites
Steigerung der Markenbekanntheit
Erhöhung der Reichweite
Verstärkung der Marktdurchdringung
Schaffung eines zusätzlichen Absatzkanals
Umgesetzt bedeutet das für einen Online-Shop den Umsatz überwiegend steigern zu wollen, im Gegensatz zu einem Blogbeitrag, indem die Reichweite erhöht werden soll.
4. Google definiert diese 5 Search Intentionen
1. Visit in Person Adresse oder Ort wird gesucht
2. Website Bereits bekannte Website soll gefunden werden
3. Do Aktion wird angestrebt (Kauf, Download, Installation etc.)
4. Know Simple Suche nach Information, die in ein bis zwei Sätzen beantwortbar ist
5. Know Suche nach Informationen zu komplexeren Themen
5. Die drei Phasen der Google Suche
Crawling: Google lädt Text, Bilder und Videos von im Internet gefundenen Seiten mit automatischen Programmen herunter – diese werden Crawler genannt.
Indexierung: Google analysiert die Text-, Bild- und Videodateien auf der Seite und speichert die Informationen in einer großen Datenbank, dem Google-Index.
Bereitstellung von Suchergebnissen: Wenn ein Nutzer eine Suchanfrage eingibt, gibt Google Informationen zurück, die für die Suchanfrage des Nutzers relevant sind. Quelle: https://developers.google.com/search/docs/fundamentals/how-search-works?hl=de#crawling
„Information is only useful when it can be understood.“ – Muriel Cooper
User Experience und SEO haben dieselben Ziele, die da wären:
Dem Nutzer das geben, was er braucht
Dem Nutzer die beste Such- oder Benutzererfahrung geben
UX-Designer setzen auf Interaktionen und Storytelling, um ein auf den Nutzer zugeschnittenes Erlebnis zu vermitteln. Auf der anderen Seite verlassen sich SEO-Experten auf Suchdaten direkt von den Nutzern, um das gleiche Erlebnis zu vermitteln. SEO hat die Daten, die UX braucht. UX hat das Webdesign-Gerüst, welches SEO braucht. Das zeigt, dass die Begriffe miteinander korrelieren.
Die Optimierung von Websites für die Suchmaschinen und die Gestaltung des Nutzererlebnisses führen also zu den selben Zielen.
Photo the white label (05. April 2018): SEO Teil 1 – die wichtigsten OnPage Rankingfaktoren für deinen Ticketshop. Online unter https://the-white-label.com/seo-onpage-rankingfaktoren-fuer-deinen-ticketshop/. Abruf am 23.12.2022
Liferay (2022): Was ist User Experience?. Online unter https://www.liferay.com/de/resources/l/user-experience. Abruf am 18.12.2022
Pereira, Joash (23. Juni 2020): Importance of UX in SEO. In: Medium. Online unter https://medium.com/edtech-in-depth-ischoolconnect/importance-of-ux-in-seo-7b0317404655. Abruf am 16.12.2022