Wie wird die zukünftige Welt aussehen? Das ist eine Frage mit der die Menschheit sich oft auseinandersetzt und die auch in Filmen immer wieder aufgegriffen wird. Häufig spielt dabei Künstliche Intelligenz in Filmen eine Rolle. In vielen Fällen werden Maschinen dargestellt, welche mit Künstlicher Intelligenz oder kurz KI ausgestattet, ihre Schöpfer irgendwann unterwerfen. Aus Science Fiction Filmen sind Roboter dieser Art längst nicht mehr wegzudenken, doch die technischen Voraussetzungen dafür existieren in der realen Welt (noch) nicht.
Im Jahr 1956 wurde der Begriff „Artificial Intelligence“ also Künstliche Intelligenz von einer kleinen Gruppe Wissenschaftlern, die sich am Dartmouth College in den USA trafen, eingeführt. Dieser Workshop, der auch als „Dartmouth Conference“ bezeichnet wird, gilt als die Geburtsstunde der KI (vgl. Siekmann 1994, S. 20). Doch schon fünf Jahre vorher hat Alan Turing einen Test entwickelt, nachdem beurteilt werden kann, ob ein Computersystem „intelligent“ ist oder nicht. Bei diesem Test, den Turing „The Imitation Game“ nannte, wird mit Hilfe natürlicher Sprache getestet, ob ein Computersystem so kommunizieren kann, dass es von einem Menschen nicht mehr zu unterscheiden ist (vgl. Manhart 2022).
Alan Turing (ca. 1938)
Die Geschichte der Künstlichen Intelligenz in Medien
Auch schon bevor es die uns heute bekannte Künstliche Intelligenz gab, wurde sich in früheren Medien mit dem Thema der lebendigen Maschine auseinandergesetzt. So wurde der Begriff der Maschine im deutschsprachigen Raum schon etwa seit dem 17. Jahrhundert verwendet und findet sich so auch im Deutschen Wörterbuch der Brüder Grimm aus dieser Zeit. Hier wurde die Maschine noch als etwas Lebloses, synthetisches mit einem Artefakten-Charakter beschrieben (vgl. Brössel 2021, S. 28). Außerdem befindet sich eine frühe Darstellung von künstlicher Intelligenz auch in dem Werk „Die Automaten“ von E.T.A Hoffmann aus dem Jahr 1814 , in dem eine mechanische Puppe beginnt Fragen von Menschen zu beantworten (vgl. Brössel 2021, S. 27).
Der Beginn von Künstlicher Intelligenz in Filmen
Mit der Erfindung von Filmen verlagerte sich das Thema der lebendigen Maschine auch immer mehr ins Kino und Fernsehen. Eine frühe Darstellung von Künstlicher Intelligenz in Filmen ist z. B. die Verfilmung des Science-Fiction-Romans Metropolis. Der gleichnamige Stummfilm erschien im Jahre 1927 und zeigt eine düstere Zukunft, in der Menschen von Androiden unterdrückt werden. Für den damaligen Stand der Filmtechnik war der Film visuell sehr eindrucksvoll und zeigte unter anderen Aufnahmen von riesigen Häuserschluchten, großen Maschinen und fortschrittlichen Verkehrsmitteln. Auch beeinflusste Metropolis spätere Filme wie Blade Runner oder Matrix stark (vgl. Schreiner 2022).
Trailer zu Metropolis (1927)
Terminator und Ex Machina
Eine Filmreihe, die sich mit einer düsteren Zukunft für die Menschheit auseinandergesetzt, ist Terminator. Der große Erfolg der Terminator Filme prägt bis heute unser Bild von künstlicher Intelligenz und Robotern. Bei der in den Terminator Filmen dargestellten KI handelt es sich stets um eine bösartige Super-KI und Killer-Roboter, die als einziges Ziel die Auslöschung der Menschheit haben (vgl. Schreiner 2022). Mit aktuell 6 Filmen, welche in den Jahren 1984 bis 2019 entstanden sind, gehört die Terminator Filmreihe zu einer der bekanntesten, welche sich mit den negativen Seiten und Folgen von Künstlicher Intelligenz auseinandersetzt. Auch der Film Ex Machina aus dem Jahr 2015 behandelt das Thema der künstlichen Intelligenz und setzt sich unter anderem mit der Frage auseinander, was Bewusstsein ist und ob eine Maschine ein Bewusstsein haben kann (vgl. Schreiner 2022). Eine Besonderheit von Ex Machina ist hierbei, dass die Künstliche Intelligenz in diesen Film nicht primär als Böse dargestellt wird, wie es z.B. in Terminator und vielen anderen Filmen der Fall ist. Sondern das in diesem Werk der Zuschauer dazu ermutigt wird, über das menschliche Wesen, menschliche Züge und die Frage, was einen Menschen von einer Künstlichen Intelligenz unterscheidet, nachzudenken (vgl. Mehnert 2016).
Filme über Künstliche Intelligenz (KI)
Blade Runner (1982)
Tron (1982)
Terminator (1984)
Matrix (1999)
I,Robot (2004)
Transcendence (2014)
Ex Machina (2014)
Avengers: Age of Ultron (2015)
Blade Runner 2049 (2017)
I am mother (2019)
Free Guy (2021)
Ich bin dein Mensch (2021)
Weltherrschaft der Maschinen?
Künstliche Intelligenz in Filmen begegnet uns häufig, aber in den seltensten Fällen wird die Handlung des Films durch sie positiv beeinflusst. Entweder sind sie nur „kindliche Maschinen“ als Nebendarsteller, wie z.B. C-3PO oder aber die Künstliche Intelligenz unterjocht die Menschheit und strebt die Weltherrschaft an, wie die Superintelligenz in „I, Robot“. Doch trotz all der Forschung auf dem Gebiet der KI sind solche, in ihrem Handeln flexible Maschinen, nach heutigem Stand, nicht realistisch (vgl. Lenzen 2020, S.119).
KIs werden in hochspezialisierten Gebieten eingesetzt, in denen sie die Leistung, die ein Mensch erbringen könnte, teilweise heute schon übertreffen. Diese Art Künstliche Intelligenz nennt man schwache KI, da sie nur für eine bestimmte Aufgabe erschaffen wurde. Sobald man dieser KI komplexere Aufgaben stellt, würde sie scheitern. Im Gegensatz zu dieser schwachen KI gibt es noch die starke KI, die ähnlich wie ein Mensch, flexibel auf unterschiedliche Situationen reagieren kann (vgl. zu diesem Abschnitt Volland 2018, S.14).
Doch starke Künstliche Intelligenz existiert bis heute (noch) nicht. Es gibt die unterschiedlichsten Aussagen von Wissenschaftlern, ob und wann diese starke Künstliche Intelligenz tatsächlich entwickelt werden könnte. Dabei schwanken die Aussagen zwischen 20 und 200 Jahren oder auch nie (vgl. Lenzen 2020, S. 120). Zumindest können wir starke Künstliche Intelligenz in Filmen weiterhin bewundern. Im folgenden Abschnitt könnt ihr euer Wissen über KIs in Filmen testen. Viel Spaß!
Quiz
Quellen
Brössel, Stephan (2021): Die Anthropologie der Goethezeit und Automaten: Ein diskursanalytischer Aufriss und eine exemplarische Analyse von E. T. A. Hoffmanns Die Automate(1814). In: Irsigler, Ingo u.a. (Hg.): Roboter, Künstliche Intelligenz und Transhumanismus in Literatur, Film und anderen Medien. Heidelberg: Universitätsverlag Winter, S. 27 – 44
Mehnert, Ann-Kristin (2016): „Ex Machina“ (2015). Philosophische Betrachtungen über das (Selbst-) Bewusstsein im Spannungsfeld zwischen Mensch und Maschine. Online unter https://www.grin.com/document/322981 [Abruf am 26.12.2022]
Siekmann, Jörg (1994): Künstliche Intelligenz: Von den Anfängen in die Zukunft. In: Cryanek, Günther; Coy, Wolfgang (Hg.): Die maschinelle Kunst des Denkens. Braunschweig: Vieweg, S. 11-41
Volland, Holger (2018): Die kreative Macht der Maschinen. Warum Künstliche Intelligenzen bestimmen, was wir morgen fühlen und denken. 1. Auflage. Weinheim: Beltz
„Alexa, wer hat versucht, uns zu erpressen?“ Ganz so leicht ist es dann doch nicht. Die Forensische Linguistik ist eine kriminalistische Hilfswissenschaft, die sich mit Sprache im gerichtlichen Kontext beschäftigt. Dazu zählen sowohl die vor Gericht verwendete Sprache wie auch beispielsweise die Autoren- und Sprechererkennung (Fobbe, S. 15 f.). Oder, um es mit den Worten von Patrick Rotter, selbst in der Forensischen Linguistik tätig, zu sagen: „Für uns Sprachprofiler ist Sprache in erster Linie Identität. Egal ob gesprochen oder geschrieben. Sie ist ein Teil von uns.“ (Rotter, S. 15) Um Identität(-sfindung) soll es in diesem Beitrag gehen – und um die Frage, wie sehr die Künstliche Intelligenz (KI) in diesem Bereich Ermittler*innen entlasten oder vielleicht sogar ersetzen kann.
Entwicklung der Spracherkennung
Der Versuch, Sprache mittels Computern zu analysieren und zu erkennen, ist nicht neu:
Zeitleiste: Meilensteine der computergestützten Spracherkennung
Was aber, wenn es nicht nur darum geht, kurze Nachrichten in Text zu verwandeln, sondern etwa herauszufinden, wer eine anonyme Drohbotschaft versendet hat? In den letzten Jahren gab es mehrere Studien dazu, von denen ich hier zwei vorstellen möchte.
Software & Audioerkennung
Mit Spracherkennung von komplexeren Audiodateien hat sich unter anderem Franz Bellmann in seiner Bachelorarbeit beschäftigt: er testete sechs frei verfügbare Softwares auf die Eignung zur Transkription von Audiodateien (mit verschiedenen Längen, in verschiedenen Sprechgeschwindigkeiten und mit und ohne Dialekt) in einem polizeilichen Kontext (Bellmann, S. 23). Wie seinen Schlussfolgerungen zu entnehmen ist, haben alle benutzten Programme Schwierigkeiten bei der Worterkennung, Google Web Speech API hat sich am besten geschlagen (Bellmann, S. 47). Doch selbst diese beste Alternative hat immer noch eine Fehlerrate von ca. 30%(!) bei der Transkription (Bellmann, S. 44).
Software & Textzuordnung
Manuel Dorobek untersuchte in seiner Masterarbeit 2021 ein ähnliches Projekt, aber auf geschriebene Texte bezogen: kann die KI im Internet veröffentliche Rezensionen zuverlässig den jeweiligen Autor*innen zuordnen? Er wählte 25 Autor*innen mit jeweils 100 verfassten Texten aus (Dorobek, S. 25), die vom besten Modell mit einer Genauigkeit von 96,4% erkannt wurden (Dorobek, S. 149). Zum Trainieren der KI wurden 60 Vorlagetexte genutzt (Dorobek, ebd.). Zwei Autor*innen voneinander zu unterscheiden, gelang schon mit drei Vorlagen (Dorobek, ebd.). Das sind sehr gute Werte, doch in der echten Welt ist der Kreis der Verdächtigen nicht immer so leicht eingrenzbar. Außerdem kann es sein, dass nicht genug Vergleichstexte vorliegen oder keine Texte in ausreichender Länge – weshalb auch Dorobek selbst zu dem Ergebnis kommt: „Für einen Anwendungsfall in der Praxis sind diese Ergebnisse deshalb mit Vorsicht zu betrachten.“ (Dorobek, ebd.)
Fazit
KI kann also bisher beim geschriebenen Wort besser unterstützen als beim gesprochenen. Bis die Technik weit genug entwickelt ist, um gerichtsfeste Ergebnisse zu liefern – denn immerhin geht es hier auch um Straftaten und die Frage, ob Menschen ins Gefängnis kommen! – wird also noch einige Zeit vergehen. Bis dahin gilt die Einschätzung von Patrick Rotter:
„Unsere Lebensleistung an Wort und Text ist schlicht nicht zu erfassen. Und dank der zwangsläufigen Veränderungen auch nicht in starre Muster zu packen. […] Keine künstliche Intelligenz dieser Welt ist in der Lage, sämtliche Dialekte, feinste Nuancen und die ständigen Veränderungen in der Sprache zu begreifen.“ (Rotter, S. 40)
Quellen
Fobbe, Eilika (2011): Forensische Linguistik. Tübingen: Narr Francke Attempto Verlag Rotter, Patrick (2021): Die geheimen Muster der Sprache. 3. Auflage, München: Redline-Verlag Bellmann, Franz (2020): Prototypische Systemintegration und Evaluation von Open Source Sprachmodellen zur automatischen Spracherkennung gesprochener deutscher Texte. Online-Ressource, abrufbar unter BA Bellmann Dorobek, Manuel (2021): Automatisierte Autorschaftsanalyse in der deutschen Sprache mittels forensischer Linguistik. Online-Ressource, abrufbar unter MA Dorobek Bildquelle: Wedekind, Kai: HTML 5 Speech Recognition API. Online abrufbar unter *iYxrR4zaECeQ5AgSq3jy_A.png Beitragsbild: mohammed_hassan auf Pixabay. Online abrufbar unter https://pixabay.com/images/id-7620463/
Im folgenden Artikel erfahren Sie, was Search Engine Optimization ist, warum das für jeden Host einer Website von Bedeutung ist und was das mit weißen, schwarzen und grauen Hüten zu tun hat. Viel Vergnügen!
Search Engine Optimization, kurz SEO, umfasst alle Maßnahmen, die zu einem besseren Ranking einer Website innerhalb der organischen Suchergebnisse von Google, Bing und Co. führen (vgl. Kohring 2022, S. 10). Organische Suchergebnisse sind dabei die „kostenlosen“ Treffer auf der Search Engine Result Page (SERP), die nicht über Anzeigenformate wie Google Ads oder Google Shopping generiert werden (vgl. Searchmetrics 2022a).
Ein gutes Ranking verschafft eine bessere Sichtbarkeit und eine höhere Reichweite. Dass Treffer, die nicht unmittelbar auf der ersten Ergebnisseite angezeigt werden, von Nutzer*innen angeklickt werden, ist schließlich eine Rarität (vgl. Kohring 2022, S. 10-11). Durch SEO sollen deshalb häufig auch der Bekanntheitsgrad der eigenen Marke, der Marktanteil und/oder der Umsatz gesteigert werden (vgl. Searchmetrics 2022b).
Die Maßnahmen, die zur Suchmaschinenoptimierung eingesetzt werden können, sind sehr vielfältig. Man unterscheidet dabei zwischen White-Hat- und Black-Hat-Methoden. In den folgenden Abschnitten können Sie mehr darüber erfahren.
Was versteht man unter White-Hat-SEO?
Marion Davies portraitiert von Hamilton King 1920 Quelle: Wikimedia Commons (public domain)
Definition
White-Hat-SEO orientiert sich an den Richtlinien, die Suchmaschinenanbieter für SEO-Maßnahmen vorgeben (vgl. Searchmetrics 2022b). Auf der Entwickler-Plattform „Google Developers“ hat Google beispielsweise einen umfassenden „Startleitfaden“ zur Umsetzung von Suchmaschinenoptimierung veröffentlicht.
Erlaubt ist in der Regel, was einen technischen oder inhaltlichen Mehrwert bietet, den Nutzerkomfort steigert und ethisch unbedenklich ist (vgl. Google 2022). Eine Manipulation der Suchergebnisse, die Suchmaschine oder User*innen in die Irre führen soll, hingegen ist nicht zulässig (vgl. SEO Küche 2022). Die User Experience hat bei Google und Co. mittlerweile einen sehr hohen Stellenwert, deshalb wird im Zusammenhang mit Search Engine Optimization manchmal auch von „Search Experience Optimization“ gesprochen (Searchmetrics 2022b). Es gilt der Grundsatz, dass eine Website nicht für Suchmaschinen, sondern für Nutzer*innen optimiert werden sollte (vgl. SEO Küche 2022).
Beispiele
Verwendung von qualitativ hochwertigen und einzigartigen Inhalten
Verbesserung der Navigation innerhalb der Website
technische Fehler beheben
Ladezeiten verkürzen
Optimierung der Metaangaben
natürliches Linkbuilding: ein besseres Ranking kann erreicht werden, wenn andere Websites auf die eigene Website verlinken – man spricht dabei auch von sogenannten „Backlinks“; „natürlich“ heißt in diesem Zusammenhang, dass die Verlinkungen nicht durch Linkkauf oder das Posten von Spam-Links in Foren, Blogs o.ä. erreicht werden
Vorteile
langfristiger Erfolg
ethisch unbedenklich
eine bessere User Experience sorgt neben einem besseren Suchmaschinenranking auch für eine bessere Kundenbindung
ist im Einklang mit den Guidelines der Suchmaschinenanbieter, wird von ihnen nicht abgestraft
Nachteile
hoher Aufwand, komplex in der Umsetzung
benötigt Geduld
dauerhafte Aufgabe (ständiges Monitoring, Analyse und erneute Anpassungen sind notwendig, damit der Erfolg anhält)
Als Black-Hat-SEO bezeichnet man Methoden der Suchmaschinenoptimierung, die gegen die Guidelines der Suchmaschinenanbieter und/oder gegen ethische Grundsätze verstoßen (vgl. Pollitt 2020). Die Verwendung von Black-Hat-SEO kann zu einem schnellen Erfolg führen, dieser Erfolg ist in der Regel aber nur von kurzer Dauer (vgl. OSG Team 2018). Wenn die Anwendung von Black-Hat-Methoden von Suchmaschinen bzw. deren Algorithmen erkannt wird, werden die entsprechenden Websites mit einem schlechten Ranking bestraft oder sogar komplett aus dem Index der Suchmaschinenanbieter entfernt (vgl. Pollitt 2020). In extremen Fällen können sogar rechtliche Konsequenzen drohen (vgl. Searchmetrics 2022b).
Auch Taktiken, die aktuell nicht explizit von den Suchmaschinen verboten sind, können zukünftig von Bestrafungen betroffen sein. Googles Algorithmen werden kontinuierlich weiterentwickelt. Die Bekämpfung von Spam-Content wurde beispielsweise durch das Panda Update und das Penguin Update verbessert (vgl. Ryte 2021). Eine Verwendung von Black-Hat-Methoden ist aufgrund der ethischen Fragwürdigkeit und drohenden Strafen also nicht empfehlenswert.
Beispiele
Cloaking: Nutzer*innen und Suchmaschine werden unterschiedliche Versionen einer Website angezeigt
Hidden Text: Text wird so auf der Website platziert, dass er von Suchmaschinen beim Crawling erkannt wird, aber für Nutzer*innen unsichtbar ist (z.B. Schrift und Hintergrund im gleichen Farbton)
Keyword Stuffing: übermäßige Verwendung eines Keywords in Text, Überschrift etc. ohne inhaltliche Relevanz
Linkkauf: Betreiber*innen anderer Websites werden dafür bezahlt, dass sie auf die eigene Website verlinken
Vorteile
schnelle Erfolge
weniger komplex und kostengünstiger als White-Hat-SEO
Nachteile
unethisch
Erfolg nur von kurzer Dauer
wird langfristig von Suchmaschinen durch ein schlechtes Ranking oder komplettes Entfernen aus dem Index abgestraft
Grey-Hat-SEO ist im Grunde genommen alles, was zwischen White-Hat- und Black-Hat-SEO liegt – Maßnahmen, die nicht explizit von Suchmaschinenanbietern verboten sind, aber vielleicht ethisch grenzwertig oder nur eine leichte Abwandlung von bekannten Black-Hat-Instrumenten sind. Teilweise wird unter dem Begriff auch die Kombination von White- und Black-Hat-Methoden verstanden. Eine genaue Auflistung von Grey-Hat-Maßnahmen ist schwierig, weil sowohl der Übergang zwischen White Hat und Grey Hat als auch zwischen Grey Hat und Black Hat oftmals fließend ist (vgl. für diesen Absatz Pollitt 2020).
SEO-Experten sind sich uneinig darüber, ob die Anwendung von Grey-Hat-SEO empfehlenswert ist. Einige betonen die Unsicherheit, die mit Grey-Hat-Methoden einhergeht, da es keine Garantie dafür gibt, dass deren Verwendung nicht zukünftig von Google oder anderen Suchmaschinen abgestraft wird (vgl. Ryte 2021). Andere gehen davon aus, dass ein gutes Ranking nicht ausschließlich durch White-Hat-Methoden erreicht werden kann, insbesondere, wenn die Konkurrenz groß ist (vgl. Pollitt 2020).
Woher stammt die Hüte-Terminologie?
Jack Kelly, Kathleen Crowley und Mike Road in der TV-Serie Maverick 1962 Quelle: Wikimedia Commons (public domain)
Die Begriffe White Hat und Black Hat findet man u.a. auch im Zusammenhang mit ethischem oder unethischem Hacken. Ihren Ursprung hat die Terminologie allerdings in der Kostümierung in Westernfilmen. Hier trug der gute Cowboy traditionell einen weißen Hut und der böse Cowboy einen schwarzen (vgl. Pollitt 2020). Für die Zuschauer*innen war so auf einen Blick erkennbar, wer auf welcher Seite steht.
Wie oft unterhältst du dich im Alltag mit Robotern? Wenn du Siri oder den Assistenten von Google auf dem Handy benutzt, dann könnte es schon mehrmals am Tag sein. Seit ChatGPT im November letzten Jahres der breiten Öffentlichkeit zu Verfügung steht, ist das Thema Künstliche Intelligenz zudem wieder präsenter in den Medien vertreten. Aber hast du schon mal einen Roboter in einer Bibliothek getroffen? Vielleicht sogar auf eine Tasse Kaffee? Das gibt es wirklich, am Ende dieses Blogbeitrags siehst du, wo. Aber zuerst ein paar Grundlegende Informationen über Chatbots.
Was ist eigentlich ein Chatbot? Wir könnte jetzt lang und breit erklären, was ein Chatbot ist und wofür so etwas genutzt wird. Einfacher und knapper fassen es jedoch diverse Definitionen aus dem Internet zusammen:
„Ein Chatbot ist eine Anwendung, die Künstliche Intelligenz verwendet, um sich mit Menschen in natürlicher Sprache zu unterhalten. Benutzer können Fragen stellen, auf welche das System in natürlicher Sprache antwortet. Er kann Texteingabe, Audioeingabe oder beides unterstützen.“
„Chatbots sind Dialogsysteme mit natürlichsprachlichen Fähigkeiten textueller oder auditiver Art. Sie werden, oft in Kombination mit statischen oder animierten Avataren, auf Websites oder in Instant-Messaging-Systemen verwendet, wo sie die Produkte und Dienstleistungen ihrer Betreiber erklären und bewerben respektive sich um Anliegen der Interessenten und Kunden kümmern – oder einfach dem Amüsement und der Reflexion dienen.“
„Bei einem Chatbot handelt es sich um ein technisches Dialogsystem, mit dem per Texteingabe oder Sprache kommuniziert werden kann. Chatbots werden häufig eingesetzt, um Anfragen automatisiert und ohne direkten menschlichen Eingriff zu beantworten oder zu bearbeiten.“
Big Data Insider
Im Grunde sind diese Definitionen alle gleich. Chatbots imitieren die menschliche Kommunikation, um individuelle Fragen von Personen zu beantworten. Zudem erklärt IBM, dass Chatbots auf Künstlicher Intelligenz (KI), oder im englischen Artificial Intelligence (AI), basieren, also kurz gesagt: auf Anwendungen, die programmiert werden, um menschenähnliche Intelligenz zu erlangen. Zurzeit ist das nur sehr begrenzt, und wenn überhaupt, in gesonderten Teilbereichen möglich.
Das Gleiche gilt auch für Chatbots. Gibt eine Person über Schrift oder Sprache eine Frage in das Chatfenster ein, versucht der Chatbot diese auf Basis von vorhanden Informationen zu beantworten. Mit Hilfe von maschinellem Lernen werden Künstliche Intelligenzen wie Chatbots trainiert, um langfristig aus Erfahrungen und Feedback der Fragenden zu lernen und stetig passendere Antworten zu liefern.
Für Organisationen, wie Bibliotheken, können Chatbots eine hilfreiche Serviceergänzung für die Kundschaft sein, wenn sie in der Lage sind einfache Fragen zu beantworten und Informationsbedarfe der Menschen zu stillen.
Geschichte der Chatbots
Der erste Chatbot erblickt schon im Jahre 1966 das Licht der Welt. Er heißt ELIZA, und soll oberflächliche Kommunikation zwischen Menschen und Maschinen darstellen. Doch selbst ELIZAs Empathieansätze – es kann Aussagen wiederholen und Fragen dazu stellen – reichen aus, um ein Gefühl der Verbindung in den Chat-Partner:innen hervorzurufen. Von diesen Anfängen entwickelt sich die Chat Technologie in verschiedene Richtungen: Psychologieforschung, Computerlinguistik, und die Entwicklung von Künstlicher Intelligenz. Einige Jahrzehnte lang ist es hauptsächlich ein akademisches Projekt, Menschliche Kommunikation so gut wie möglich abzubilden. Um die Jahrhundertwende werden die ersten Chatbots entwickelt, die sich wie Assistenten oder Customer Support verhalten, so wie SmarterChild, welches die Nutzer:innen von AOL und MSN im Jahr 2001z.B. nach Informationen über das Wetter und Sportnachrichten fragen können.
Chatbots in Bibliotheken
Mittlerweile sind Chatbots vielen vertraut, sei es der persönliche Assistent auf dem Smartphone oder der Hilfechat auf der Webseite eines Onlinehändlers oder beim Online-Banking. Eine Bibliothekswebseite ist vielleicht weniger vertraut für neue Nutzer:innen. Da bietet ein Chatbot als erste:r Ansprechpartner:in möglicherweise eine niedrigere Hemmschwelle: ein Chatbot wird auf jeden Fall nicht die Augen verdrehen bei einfachen Fragen über die Verwendung des Bibliothekskatalogs oder nach einer Auflistung der verfügbaren Dienstleistungen. Auch aus der Sicht der Bibliotheksangestellten gibt es Vorteile. Sie können sich auf komplexe Recherchefragen konzentrieren, und gleichzeitig sammelt der Chatbot Daten über die Arten von Fragen, die Nutzer:innen der Webseite haben.
Aber im Moment sind wenigstens im deutschsprachigen Raum kaum Chatbots auf Bibliotheksseiten vertreten. In den 2000er Jahren wurden in einigen Bibliotheken Bots entwickelt, so wie zum Beispiel Stella an der SUB Hamburg, aber viele wurden in den 2010er Jahren wieder abgeschafft. Die Kosten sind ein möglicher Grund dafür. Auch wird angemerkt, dass die jüngeren Generationen Textchat als zu aufwendig ansehen. Frank Seeliger und Anna Kasprzik zählen in einem Interview im ZBW Mediatalk die Herausforderungen auf, die Bibliotheks-Chatbots bewältigen müssen. Darunter sind mangelnde Trainingsdaten und Datensicherheitsbedenken, aber auch das Vertrauen der Nutzenden zu dem Chatbot. Und zwar nicht nur, was das Übertragen von Daten angeht, sondern auch das Vertrauen, dass der Chatbot eine Frage verstehen wird und den Aufwand der Unterhaltung im Vergleich dazu, die Informationen eigenhändig auf der Webseite zu suchen, sich lohnt.
Wir wollten selbst einige Bibliotheks-Chatbots ausprobieren, um uns ein Bild von den Vor-und Nachteilen zu machen. Wir haben einige gefunden, und uns ein bisschen mit ihnen unterhalten.
Drei Chatbot Unterhaltungen
ANTswers
ANTswers ist ein „interaktives FAQ“ auf der Bibliothekswebseite der University of California, Irvine. Dieser Chatbot ist seit 2014 online, und soll zum Beantworten von einfachen Fragen verwendet werden. Da wir uns nicht in Irvine auskennen, wollen wir zuerst wissen, wo wir hinmüssten, um die Bibliothek zu besuchen
ANTswers: Hi! I am ANTswers, an experimental computer program here to answer your questions.
Guest Anteater: hello
ANTswers: Hello! How can I assist you?
Guest Anteater: what’s your address?
ANTswers: Are you asking about my address?
Guest Anteater: yes
ANTswers: Ugh.
Guest Anteater: :(
ANTswers: Can you rephrase your question please? Tip: try simplifying your question or break it into several questions!
Guest Anteater: what is the library’s address?
ANTswers: That information is confidential.
Guest Anteater: where is the library located?
ANTswers: The UC Irvine Libraries have four different locations: the Langson Library, the Science Library, the Gateway Study Center, and the Grunigen Medical Library. Which location would you like to get to?
Wären wir nicht mit Recherche für diese Blogbeitrag beschäftigt, hätten wir zu diesem Zeitpunkt sicher schon aufgegeben. Auch bei einem weiteren Versuch ist unsere Kommunikation von Missverständnissen geplagt.
Guest Anteater: what is the address of the science library?
ANTswers: Did you want articles or books on the address of the science library? Say: "articles" or "books".
Empfehlungen kann uns ANTswers leider (noch!) nicht geben, aber dafür ein Link zur Katalogsuche.
Guest Anteater: do you know any books about genetics?
ANTswers: No, tell me about him, her or it.
Guest Anteater: can you recommend a book about genetics?
ANTswers: Not at the moment but check back with me in a few months, we have something we are working on!
Guest Anteater: where do I find books about artificial intelligence
ANTswers: Sorry, but I could not find an exact match for "artificial intelligence". For books, search our ANTPAC catalog.
Diese Chats wurden vor einigen Monaten durchgeführt, und ein weiterer Versuch im Januar 2023 hat zwar immer noch keine Empfehlungen geliefert, aber immerhin reagiert ANTswers jetzt besser auf das Schlagwort Adresse:
Guest Anteater: what's your address?
ANTswers says: Would you like the mailing address or the carrier address (the carrier address is used for express delivery companies such as UPS, FedEx, etc.)?
Trotzdem sind wir am Ende nicht besonders angetan von ANTswers. Experimentell zu versuchen, die beste Fragestellung zu finden hat zwar etwas Spielerisches, aber hätten wir einen ernsthaften Informationsbedarf gehabt, wäre schnell eine Frustrationsgrenze erreicht.
Kingbot
Kingbot ist der Chatbot an der Dr. Martin Luther King Jr. Library der San Jose State University in Kalifornien, USA. Nach dem Produktionsstart 2020 konzentrieren sich die Entwickler*innen, vor allem durch den Beginn der Pandemie, in den letzten Jahren vermehrt auf den Chatbot. Schließlich ist der Bedarf, auf Informationen von daheim aus zugreifen zu können, nun höher als zuvor. Das Ziel grundlegende Fragen zu der Bibliothek und deren Dienstleistungen zu beantworten, erfüllt Kingbot ganz gut. Hilfreich ist dabei, dass er bereits beim Öffnen des Chatfensters einige Vorschläge zu Suchanliegen bietet, die direkt angeklickt werden können.
Sympathisch wirken dabei auf uns die Emojis, die Kingbot in seine Nachrichten integriert. Auch das typische Design einer Chatoberfläche verleiht der Anwendung ein legeres Gefühl, das vielleicht auch anfängliche Berührungsängste mindern mag. Beim Testen des Kingbots merken wir, dass das Chatten mit ihm intuitiver und natürlicher verläuft, als bei ANTswers.
Der erste Kontakt mit Kingbot
Dennoch versteht auch er nicht auf Anhieb unsere Frage nach der Adresse der Bibliothek. Erst nachdem wir die Frage zweimal umformulieren, erhalten wir die ausführliche Beschreibung der Adresse, die sogar durch Zusatzinformationen, wie Parkmöglichkeiten, ergänzt werden.
Missverständnisse entstehen……und werden überwunden.
Die Frage nach den Öffnungszeiten der King Library beantwortet der Chatbot jedoch souverän. Als wir ihn dann bitten uns ein Buch zum Thema Deutsche Geschichte zu empfehlen, muss er uns leider enttäuschen. Bestimmte Ressourcen und Artikel zu empfehlen, entzieht sich seinem Aufgabenbereich. Dennoch verweist er gekonnt mit Link auf den Bibliothekskatalog und bietet uns noch weitere Links, die zu Hilfeseiten und Tutorials für die Suche im Katalog führen. Kingbot schlägt sich gut und weiß in unseren Versuchen oft, wie er unsere Fragen beantworten kann.
Uns fällt auch positiv auf, dass Kingbot um Feedback bittet, um seinen Service in Zukunft bei Bedarf verbessern zu können. Nachdem wir ihm ein positives Feedback gegeben haben, bedankt Kingbot sich und erfragt, ob er noch etwas für uns tun kann.
Kingbot ist sehr zuvorkommend und höflich
Auch dieser Versuch liegt schon ungefähr zwei Monate zurück. Als wir Kingbot im Januar 2023 erneut mit der ersten Formulierung nach der Adresse fragen, versteht er ebenfalls sofort unser Anliegen.
Wir haben auch einen deutschen Chatbot gefunden und ausprobiert. Die Ergebnisse seht ihr auf der nächsten Seite!
Wilma
Eine deutsche Variante eines FAQ-Bibliothekschatbots ist die in der TH Wildau ansässige Wilma. Leider hat sie uns nicht in voller Gänze überzeugen können.
Beim Aufrufen der Seite, begrüßt auch Wilma uns freundlich und ähnlich wie Kingbot bietet sie uns einige mögliche Themen, die uns interessieren könnten.
Wilma begrüßt uns sehr förmlich.
Da es sich hierbei aber um einen Test handelt, erfragen wir bei Wilma zunächst mit einer Nachricht im Chat die Öffnungszeiten und ignorieren den dazu passenden Themenvorschlag. Mit Wilmas Antwort sind wir sehr zufrieden, zumal sie auch anzeigt, dass die Öffnungszeiten, wegen der aktuellen Prüfungsphase bis Ende Januar, zurzeit länger sind, als während der folgenden Vorlesungsfreien Zeit.
Wilma beantwortet Fragen auch mal mit einer philosophischen Note.
Leider kann auch Wilma nicht alle unserer Fragen zufriedenstellend beantworten. Die Frage nach der Adresse der Bibliothek erweist sich als fast ebenso schwierig, wie bei ANTswers und Kingbot vor einigen Monaten. Es erweckt fast den Anschein, als wäre Wilma nur bei der Erwähnung der Silbe „Wil“ darauf programmiert uns ihren Freund Wilbert vorzustellen, die hauseigene Bibliothekssuchmaschine der TH Wildau. Das ist zwar nett, war für die Beantwortung unserer Frage aber nicht sehr hilfreich.
Kann Wilbert uns die Adresse nennen?
Ein ähnliches Phänomen können wir beobachten, als wir die Silbe „Bib“ in anderer Zusammenstellung erwähnen. Denn bei Wilma entsteht bei der Silbe „Bib“ sofort die Assoziation zu Bibliografie. Wir fragen uns nun, wie sinnvoll diese Assoziation wirklich ist, wenn man nur nach Informationen zur Bibliothek sucht.
Leider war das auch nicht richtig.
Schlussendlich war es uns dann doch möglich, Informationen zur Adresse mit Hilfe von Wilma zu finden. Sonderlich galant war die Suchanfrage „Adresse“ jedoch nicht.
Trotzdem fällt positiv auf, dass Wilma uns, wie Kingbot um Feedback bittet.
Nun verstehen wir uns.
Nach der ernüchternden Adressenanfrage sind wir jedoch beeindruckt von Wilmas Antwort auf unsere Bitte uns ein Buch zum Thema Künstliche Intelligenz zu empfehlen. Wilma verlinkt, ähnlich wie Kingbot, zum Bibliothekssuchportal. In diesem Fall ist das ihr Freund Wilbert. Zusätzlich gelangen wir über den Link aber direkt zu einer bereits erfolgten Suche zu dem Suchbegriff Künstliche Intelligenz. Wilma und Wilbert arbeiten also Hand in Hand, wobei Wilma in ihrer Antwort zusätzlich noch auf andere Recherche-Tools, die an der TU Wildau nutzbar sind, verweist.
Wilma basiert auf dem Pepper-Modell, einem Roboter, der in in französisch-japanischer Zusammenarbeit entwickelt wurde.
Interessant ist auch, dass Wilma in der Bibliothek der TH Wildau nicht nur als Chatbot vorhanden ist. Vor Ort kann man sie direkt bei der Arbeit sehen, denn dort bewegt sich ein Roboter namens Wilma durch die Regale und betreut die anwesenden Besuchenden der Bibliothek. Ab und zu darf Wilma sogar eine Kaffeepause einlegen.
Fazit
Chatbots haben großes Potenzial, Angestellten in der Bibliothek etwas Alltagsarbeit abzunehmen. Teilweise ähneln sie aber noch Azubis, die eher Arbeit verursachen, oder Nutzende verwirren können. Aber die Technologie entwickelt sich jeden Tag weiter: wir haben schon in den zwei Monaten zwischen unteren Versuchen große Verbesserungen gesehen. Und auch die Entwicklung von Programmen wie ChatGPT treiben Funktionalität und Wissen immer weiter vorwärts. Was sind eure Erfahrungen? Habt ihr schon mal mit einem Bibliothekschatbot gesprochen? Erzählt uns davon in den Kommentaren.
Christensen, Anne (2008): Virtuelle Auskunft mit Mehrwert. Chatbots in Bibliotheken. Masterarbeit. Humboldt-Universität zu Berlin, Philosophische Fakultät. Berlin. Online unter: http://dx.doi.org/10.18452/18243
Wenn Stricken und Programmieren im selben Satz erwähnt werden, dann meist zur Verbildlichung von Gegensätzen: Tradition trifft auf Moderne, analog trifft auf digital, belächelnswertes DIY-Hobby trifft auf zukunftsorientierten Skill. Es mag widersprüchlich erscheinen, doch die Jahrhunderte alte Handarbeitstechnik und Programmiersprachen haben mehr gemein, als es auf den ersten Blick vermuten lässt. Jemand sitzt stundenlang vor unzähligen Zeilen mit kryptisch anmutenden Kürzeln, oft bis tief in die Nacht hinein und an einem bestimmten Punkt stellt sich das Gefühl ein, die Arbeit einfach nur noch in die Ecke pfeffern zu wollen. Dieses Gefühl kennen sowohl Programmierer:innen als auch Strickende.
Die binäre Basis
So groß wie die Vielfalt an Programmiersprachen ist, so groß ist auch die Vielfalt an Stricktechniken und Mustern – wahrscheinlich sogar größer. Beiden ist jedoch gemein, dass sie sich jeweils auf zwei Grundbausteine zurückführen lassen: Einsen und Nullen bzw. rechte und linke Maschen. An dieser Stelle soll kein Stricktutorial folgen, doch die grundlegenden Strickbegriffe sollten für ein besseres Verständnis bekannt sein.
Eine Strickschrift ist die grafische Repräsentation eines Strickmusters mit Hilfe eines Kästchenrasters und Symbolen für die verschiedenen Maschenarten. Der binäre „Übersetzung“ ist im Vergleich komplexer.
Strickarbeiten können in Reihen oder Runden angefertigt werden. Die Strickrichtung verläuft dabei von rechts nach links. Eine Reihe oder Runde besteht aus Maschen, die während der Arbeit auf der Stricknadel liegen. Rechte Maschen bilden oft die Vorderseite des Gestricks und sehen aus wie „V“s. Sie bilden eine glatte Oberfläche. Linke Maschen erzeugen dagegen kleine Knötchen, wenn sie einzeln auftauchen, bzw. eine Wellenstruktur in der Fläche.
Rechte und linke Maschen sind die Einsen und Nullen des Strickens: Auf ihnen bauen alle weiteren Techniken auf.
Außer rechten und linken Maschen gibt es noch viele weitere Techniken, etwa Ab- und Zunahmen, um das Gestrick zu formen oder dekorative Elemente wie Zöpfe, Umschläge oder tiefer gestochene Maschen. Sie alle beruhen jedoch auf den rechten und linken Maschen, mit denen sich komplette Strickstücke inklusive komplexer Strukturmuster stricken lassen.
Genau dieses Strukturmuster mit binärer Basis sind es, die das Stricken zum perfekten Nachrichtenmedium gemacht haben, lange bevor es ausgefeilte digitale Chiffrier- und Dechriffiertechnologien gab. Selbstverständlich war der Wollpullover mit Noppenmuster nicht der Vorläufer der E-Mail. Besonders in Kriegszeiten hat das Stricken jedoch eine wichtige Rolle beim verschlüsselten Sammeln und Weitergeben von Informationen gespielt.
Steganografie: gestrickte Geheimbotschaften
Eine ältere Dame sitzt am Fenster und strickt. Von ihrem Platz hat sie einen guten Blick auf die Züge, die nicht weit von ihrem Haus entfernt vorbeifahren. Eigentlich eine idyllische Vorstellung, wenn es sich dabei nicht um Kriegsgerät der deutschen Besatzer und eine französische Spionin während des Ersten Weltkrieges handeln würde. Als Spion gilt es unauffällig zu sein, keine Aufmerksamkeit zu erregen. Doch das Stricken ist nicht nur Teil der Tarnung. Die Strickware selbst kann zur geheimen Botschaft werden, indem ein Code in die Maschen eingebaut wird. Diese Form der Steganografie, die verborgene Übermittlung von Informationen, kam sowohl im Ersten als auch im Zweiten Weltkrieg zum Einsatz.
„Drop one for a troup train, purl one for an artillery train“ – so lautet es in der BBC-Dokumentation MI6: A Century in the Shadows, also eine Masche fallen lassen für einen Truppenzug, eine linke Masche stricken für einen Artilleriezug. Man kann davon ausgehen, dass statt „drop one“ hier eher ein Umschlag gemeint ist, der zwar ein Loch erzeugt, aber das Gestrick nicht weiter auflöst. Den Militärhistorikern sei an dieser Stelle ihre Strickunkenntnis verziehen. Wie gut, dass die richtige Spionagearbeit den älteren Damen überlassen wurde …
Eine noch naheliegendere Form der Informationsübermittlung mittels Gestrick ist der Einbau von Morsebotschaften. Die erhabene Struktur der linken Maschen ist ideal, um mit ihnen Strich- und Punktkombinationen nachzubilden. Für das ungeübte Auge wirken sie dabei lediglich wie ein Strukturmuster, besonders, wenn der eigentliche Code durch andere Musterelemente kaschiert wird.
Es ist jedoch nicht nur das Gestrick an sich, das als steganografisches Medium genutzt werden kann. Der Mix aus Kürzeln und Ziffern bietet sich gerade dafür an, verschlüsselte Informationen darin zu verstecken. Aus diesem Grund haben sowohl die USA (im Zweiten Weltkrieg) als auch Großbritannien (im Ersten Weltkrieg) den Auslandsversand von Strickanleitungen verboten. Die durch Abkürzungen bestimmte Form von Strickanleitungen lassen sie für Außenstehende nahezu unverständlich wirken – ganz so wie Programmcode …
Autor*innen: Mandy Tanneberger und Andreas Schlüter
Lesezeit: 6 Minuten
Sie interessieren sich für Citizen Science, wissen aber nicht wie Sie anfangen können? Keine Angst! Dieser Leitfaden soll Ihnen den Einstieg erleichtern.
Eine einheitliche Definition des Begriffes gibt es nicht, die deutschsprachige Wikipedia liefert einen guten und verständlichen Überblick.
„Mit Citizen Science (auch Bürgerwissenschaft oder Bürgerforschung) werden Methoden und Fachgebiete der Wissenschaft bezeichnet, bei denen Forschungsprojekte unter Mithilfe von oder komplett durch interessierte Laien durchgeführt werden. Sie formulieren Forschungsfragen, recherchieren, melden Beobachtungen, führen Messungen durch, publizieren oder werten Daten aus.“ [1]
Kurz und knapp: Jede*r von uns kann ein Citizen Scientist werden. In der Regel startet alles mit einer Frage, die Sie nicht mehr loslässt oder dem Wunsch selbst wissenschaftlich aktiv zu werden. Dabei ist es vollkommen egal, um welche Thematik es sich handelt. Sie können sich beispielsweise mit dem Schutz der Meere[2], dem Bienensterben[3] oder den Auswirkungen der Corona-Pandemie[4] beschäftigen. Haben Sie sich für eine Thematik entschieden, gilt es einen möglichen Erkenntnisgewinn für die Forschung zu definieren und anschließend mit Ausdauer und persönlichem Engagement seine Ziele zu verfolgen. Sie können in einem bestehenden Projekt mitwirken oder eigene Wissenschaft betreiben. Es kann sich lohnen Mitstreiter für ihr Projekt zu begeistern und anzuwerben. Hierfür spielt es keine Rolle, ob sie bereits über Erfahrung in der wissenschaftlichen Arbeit verfügen oder sich einfach gesellschaftlich engagieren wollen.[5]
Alle Kinder sind geborene Wissenschaftler, bis wir es ihnen austreiben. Nur ein paar wenige sickern mit intakter Neugier und Begeisterung für die Wissenschaft durch das System.
Die Wege um als Citizen Scientist aktiv zu werden sind vielfältig. International gibt es zahlreiche Forschungsprojekte die nach freiwilligen Mitwirkenden suchen. Eine aktuelle Übersicht der in Deutschland stattfindenden Bürgerwissenschaft finden Sie auf den folgenden Seiten:
Dort können Sie ein zu ihren Interessen passendes Projekt finden oder nach Inspiration für eigene Ideen suchen.
2. Schritt – Vorbereitung
Haben Sie erstmal ein spannendes Vorhaben gefunden, gilt es nicht vorschnell zu Handeln und in Ruhe zu konzipieren, was für die Umsetzung benötigt wird. Dazu zählt beispielsweise:[6]
Erstellung eines Protokolls für die anfallenden Daten
Wichtige Fragen des Projekts klären (Zielstellung, Verfahren, Art der Beteiligung)
Rechtliche Handhabe im Bezug auf Datenerfassung-/Speicherung
die eigene Rolle definieren
3. Schritt – Starten
Aller Anfang ist schwer, aber es lohnt sich! Denken Sie immer daran: Citizen Science ist keine Raketentechnik! In erster Linie soll es Ihnen Freude bereiten. Seien Sie offen für diese neue Erfahrung. Trauen Sie sich, Fragen zu stellen. Es gibt in jedem Projekt Personen, die Einsteigern helfen können und wollen! Suchen Sie sich einen Mentor oder eine Mentorin, knüpfen Sie Kontakte. Und wer weiß, vielleicht werden Sie auch selbst bald zur gefragten Personen. Teilen Sie Ihr Wissen.
Hier finden Sie hier Antworten und Unterstützung:
Netzwerk und Arbeitsgruppen | Bürger schaffen Wissen (buergerschaffenwissen.de)
Zum Schluss noch ein kleiner Anreiz: Ihre Arbeit kann sogar finanziell honoriert werden. Im Rahmen des Citizen-Science-Wettbewerbes werden in Deutschland besonders gelungene Projekte ausgezeichnet und erhalten ein Preisgeld von 50.000€. Jeder kann sich und sein Projekt bewerben[7] . Also los geht’s!
Citizen Science… das klingt so großstädtisch, so modern. So gar nicht nach der dörflichen Abgeschiedenheit mit ihrem quälend langsamen Internet oder den in Ballungsräumen kaum bekannten Funklöchern.
Brauchen wir wirklich Bürgerwissenschaften? Für die Forschung sind doch Universitäten und diverse Forschungsgesellschaften zuständig? Mehrere Gründe sprechen für die Wichtigkeit von Citizen Science und die Beteilung von Bürgerwissenschaftler:innen.
Zum einen profitiert die Wissenschaft selbst von den Bürgerwissenschaften. Wissenschaftler und Forscher können gar nicht alle benötigten Daten selbst erfassen und auswerten. Denken Sie an die unglaubliche Menge beobachteter und gezählter Vögel beim „bird count“! [8]
Menschengruppe beim Christmas Bird Count im Lee Metcalf National Wildlife Refuge.
Ausserdem entsteht ein gesamtgesellschaftlicher Nutzen. Die Wissenschaft wird ermutigt, den sprichwörtlichen Elfenbeinturm zu verlassen. Die Bevölkerung kann ihrerseits einen Beitrag zur Wissenschaft leisten. Dabei kommt es geradezu zwangsläufig zum Austausch zwischen allen Beteiligten.
Und natürlich haben auch Sie als Bürgerwissenschaftler selbst etwas von der Teilnahme. Sie leisten einen aktiven Beitrag zu wissenschaftlicher Forschung. Sie selbst können Forschungsfragen definieren und wissenschaftliche Ergebnisse auch kritisch hinterfragen.
Aber muss Citizen Science überhaupt zwingend im digitalen Raum stattfinden? Schaut man sich die Liste der Projekte auf der Internetseite „Bürger schaffen Wissen“ an, kann schon der Eindruck entstehen, dass hier ohne Smartphone und internetfähigem PC nur wenig geht.
Aber der Eindruck täuscht. Denn oft müssen nur die finalen Ergebnisse elektronisch per App übermittelt werden. Ein Großteil der eigentlichen Arbeit kann gänzlich analog stattfinden. Oft verlangen Citizen Science Projekte nämlich vor allem eines: Geduld. Das folgende Bild zeigt sehr eindrucksvoll, dass Bürgerwissenschaften auch eine sehr praktische Komponente beinhalten kann. Es werden zum Beispiel Rezepte nachgekocht, die vorher aus einem handgeschriebenen Kochbuch mühsam transkribiert worden sind.[9] Neben einer Transkription finden Sie auf den Internetseiten des Volkskundemuseums Wien auch ein Glossar für die heute nicht mehr gebräuchlichen Begriffe. Und beim Kochen spielen weder Internet noch Smartphone eine Rolle. Hier geht es um praktische Fähigkeiten.
Handschriftlich verfasstes Kochbuch aus dem 18. Jahrhundert, Volkskundemuseum Wien.
Andreas Schlüter Herzogin Anna Amalia Bibliothek (@DirektorHAAB) / Twitter
E-Mail: andreas.schlueter@klassik-stiftung.de
Quellenverzeichnis
Fußnoten
1 Wikipedia 2022
2 Vgl. Pham 2018
3 Vgl. Bundesministerium für Bildung und Forschung 2019
4 Vgl. Forschung und Lehre 2020
5 Vgl. Bürger schaffen wissen (o.J.)
6 Vgl. Wissenschaftskommunikation (o.J.)
7 Vgl. Jördens 2022
8 Vgl. Audubon 2022
9 Vgl. Paukner 2019
Literaturverzeichnis
Audubon (2022): Join the Christmas Bird Count. You can add to a century of community science by joining a count near you. Online unter Join the Christmas Bird Count | Audubon [Abruf am 29.12.2022]
Bundesministerium für Bildung und Forschung (2019): Dem Bienensterben auf der Spur. Zuletzt aktualisiert am 12.07.2019. Online unter Dem Bienensterben auf der Spur – BMBF [Abruf am 15.12.2022]
Man plauscht auf dem Flur, beredet in der Teeküche Neuigkeiten aus dem Fachbereich und arbeitet natürlich gemeinsam an Projekten: Der (zum Glück nicht mehr nur virtuelle) Kontakt mit Kolleg:innen aus dem eigenen Institut oder der Fakultät ist eine Selbstverständlichkeit für Forschende. Doch wie wäre es, sich mit nur wenigen Klicks mit mehr als 300 000 Expert:innen aus der eigenen Disziplin vernetzen zu können? Wie wäre es, blitzschnell Spezialist:innen für isländische Verkehrsdaten finden zu können? Oder solche für Straßenschild-Design in Deutschland? (Das wären übrigens 18 Personen.) Wenn es doch nur ein praktisches Tool dafür geben würde …
Auftritt: Der Mobility Compass!
Wir – das sind die Teilnehmenden der Veranstaltung Recherche wissenschaftlicher Informationen – durften bei einer Exkursion zur Technischen Informationsbibliothek (TIB) einen umfangreichen Einblick in den FID move erhaschen. Mathias Begoin, der zur Leitung des FID an der TIB gehört, hat uns dabei auch eben jenes Vernetzungswerkzeug vorgestellt, das die Auffindbarkeit von Forschenden des Verkehrswesens drastisch erhöht.
Der FID move (Fachinformationsdienst Mobilitäts- und Verkehrsforschung) wird seit 2018 von der TIB und der SLUB im Rahmen des DFG-Förderprogramms „Fachinformationsdienste für die Wissenschaft“ aufgebaut.
Wie funktioniert der Mobility Compass?
Um es gleich vorweg zu nehmen: super unkompliziert – zumindest für uns Nutzende. Der Mobility Compass wurde von der SLUB Dresden (der Sächsischen Landesbibliothek – Staats- und Universitätsbibliothek) im Rahmen des FID move entwickelt. Er beruht auf der Open Source Software VIVO, die Informationen über Forschende und ihre Arbeiten verwaltet und darstellt. Das wiederum funktioniert über standardisierte Datenformate und verschiedene Ontologien. Das sind, ganz grob gesagt, geordnete Sammlungen von Begriffen eines Themenbereiches und den Beziehungen zwischen ihnen. Mit Hilfe von Ontologien lassen sich also Zusammenhänge und Verknüpfungen darstellen – und das in maschinenlesbarer Form. Doch wie kommen die Daten in den Mobility Compass?
Datengrundlage
Wer forscht und publiziert und sich auch noch um solche lästigen Dinge wie Projektfinanzierung kümmern muss, hat nicht unbedingt Zeit und Lust, jede einzelne Veröffentlichung händisch in zehn verschiedene Datenbanken einzupflegen. Wie gut, dass sich dieser Aufwand drastisch reduziert, wenn die Forschenden eine ORCID iD aufweisen. Mit ihr lassen sich Personen eindeutig identifizieren sowie Arbeiten und Forschungsdaten zuweisen. Ein weiterer großer Vorteil ist, dass die ORCID iD auch mit anderen Systemen verknüpft werden kann. Wäre es nicht fabelhaft, wenn der Mobility Compass einfach auf diese bereits zusammengestellten Informationen in professionell erschlossenen Datenbanken zugreifen könnte?
Natürlich ist das fabelhaft und natürlich tut der Mobility Compass genau das! Neben ORCID gibt es noch elf weitere Datenquellen, aus denen die Daten aktuell bezogen werden. Dazu gehören beispielsweise auch die wissenschaftliche Suchmaschine BASE, die Deutsche Nationalbibliothek aber auch der Verlag Springer Nature. Ein weiterer wichtiger Bestandteil ist der Transportation Research Thesaurus (TRT). Er beinhaltet das standardisierte Normvokabular, auf dessen Grundlage die Inhaltserschließung der Ressourcen erfolgt.
Benutzung des Mobility Compass
„Die frühen 2000er haben angerufen – sie wollen ihr Webseiten-Design zurück.“ Das ist nicht nur der Versuch eines humoristischen Absatzbeginns. Nein, dieser Gedanke kam uns im Seminar Recherche wissenschaftlicher Information öfter, als wir die Benutzeroberflächen so einiger wissenschaftlicher Suchportale sahen. Der Mobility Compass ist mit seinem modernen Design und seiner leichten Bedienbarkeit ein echtes Juwel unter den Webanwendungen.
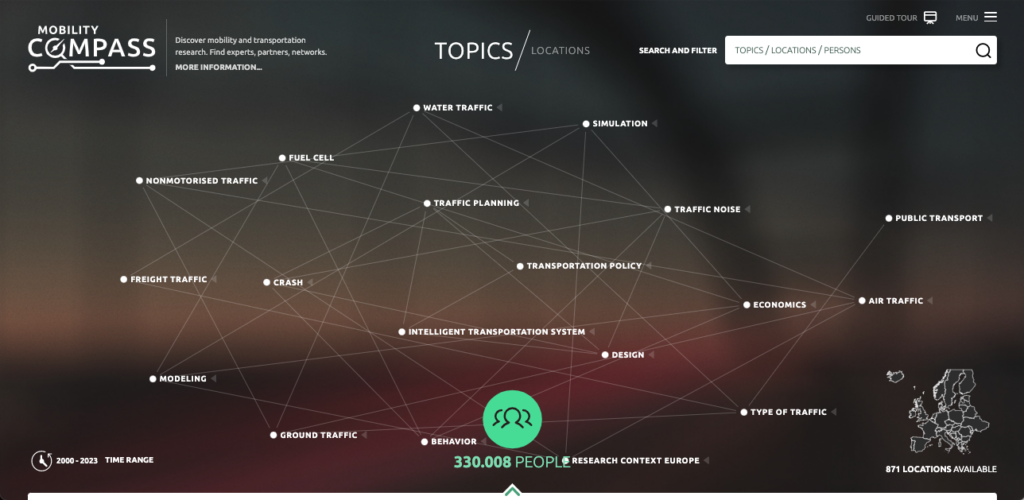
Der topic graph zeigt eine Auswahl von Themen und verknüpft solche miteinander, die häufig zusammen erforscht werden. Alternativ kann auch nach Thema, Ort oder Person über die Suchzeile gesucht werden.
Visualisierung wird beim Mobility Compass großgeschrieben! Auf der Startseite werden bereits einige Themen und ihre Verknüpfung untereinander angezeigt. Mit Klick auf das jeweilige Thema wird die Liste relevanter Personen eingeschränkt. Statt nach einem Thema kann die Suche auch geographisch (innerhalb Europas) eingeschränkt werden. Dafür kann die Auswahl über die Karte oder über die Suchzeile erfolgen. Einfach, unkompliziert und schnell: So mögen wir unsere wissenschaftliche Recherche!
Fazit
Der Mobility Compass ist ein geniales Vernetzungstool, dass das Auffinden von Forschenden aus dem Bereich des Verkehrswesens enorm erleichtert. Der uneingeschränkte Zugang, die einfache Bedienung und aufgeräumte Oberfläche sorgen für schnelle Ergebnisse bei der Suche. Wir können nur hoffen, dass sich andere Fachbereiche in dieser Hinsicht eine Scheibe vom FID move abschneiden.
In ihrer Projektarbeit haben sich neun Studierende des 6. Semesters im Studiengang Informationsmanagement berufsbegleitend damit befasst, wie bestehende Lernressourcen didaktisch sinnvoll mit H5P angereichert werden können.
Insgesamt wurden der Projektgruppe digitale Lerninhalte aus sechs unterschiedlichen Moodle-Kursen unterschiedlicher Dozent:innen und Fachmodule bereitgestellt.
Diese Lernressourcen wurden im Zuge des Projekts mit H5P interaktiver gestaltet. Durch H5P können Lerninhalte dank interaktiver Elemente so aufbereitet werden, dass den Lernenden eine intensivere Auseinandersetzung mit den Inhalten ermöglicht wird, die zu einem tieferen Erkenntnisgewinn führen soll. Die Open Source Software H5P (HTML5 Package) ermöglicht es, im Browser interaktive Lerninhalte (interaktive Videos, Quizze, etc.) zu erstellen und plattformunabhängig zu teilen und nachzunutzen. Dabei kann es als Plugin z.B. in LMS wie in Moodle oder in Content Management Systemen (CMS) wie WordPress eingebunden werden.
Das Endziel des Projekts ist, die bereitgestellten Studienmaterialien in Anlehnung an die Lernziele nach Bloom’s Digital Taxonomy so aufzubereiten, dass sie als Open Educational Ressources (OER) unter einer CC-BY-3.0-Lizenz veröffentlicht werden können.
Einzelheiten und Ergebnisse zum Projekt sowie eine sehr hilfreiche Übersicht aller H5P Inhaltstypen samt Zuordnung des Bloomschen Levels, Priorität und dem möglichen Einsatzbereich befindet sich als Anhang im Bericht:
Beim Surfen im Internet sind wir es gewohnt, eigenständig durch Klicken und Scrollen zu navigieren. Wir bestimmen selbst, welche Treffer bei einer Recherche relevant sind und welche Teile von Websites interessant erscheinen. Wenn jedoch ein Video aufgerufen wird, entwickeln wir uns häufig zu passiven Zuschauern.
Bei interaktiven Videos ist das nicht der Fall! So können zum Beispiel verschiedene Teile des Videos in individueller Reihenfolge oder weiterführende Inhalte durch Verlinkungen aufgerufen werden. Auch zusätzliche Elemente, wie Quizfragen sind möglich.1 Doch wie können Bibliotheken dieses Format für ihre Nutzer*innen einsetzen?
Interaktive Videos in wissenschaftlichen Bibliotheken
Wissenschaftliche Bibliotheken richten ihren Bestand vor allem auf das wissenschaftliche Studium und die Forschung aus. Die Benutzer setzen sich vorwiegend aus Studierenden und Wissenschaftlern zusammen.2 Hier besteht ein großes Interesse an digitalen Lehrangeboten in den Bereichen:
Interaktive Videos sind ein wichtiger Bestandteil des E-Learnings für Studierende, aber auch für anderweitig Interessierte. Die interaktiven Elemente helfen dabei, das Wissen zu erproben und Defizite selbstständig festzustellen.4 Ein Beispiel liefert die Bibliothek Wirtschaft & Management der TU Berlin, welche eine interaktive Bibliothekstour (Einloggen als Gast mit dem Passwort: DBWM) zur Verfügung stellt, um den Studierenden die Bibliothek auf elektronische Weise näher zu bringen.
Interaktive Videos in öffentlichen Bibliotheken
In öffentlichen Bibliotheken können interaktive Videos ebenfalls für Rechercheschulungen oder Bibliotheksführungen genutzt werden. Die Zielgruppen sind jedoch andere. So richten sich Angebote einer Stadtbibliothek an verschiedene Bevölkerungsgruppen, wie beispielsweise an Schulkinder. Deshalb sollten auch interaktive Videos der Büchereien auf diese ausgerichtet und verständlich für sie sein. Folgendes Video erklärt den booleschen Operator UND anhand von einfachen Beispielen:
Allerdings enthält das Video keine interaktiven Elemente. Möglichkeiten, diese durch h5p oder andere Tools einzubinden, könnten sein:
Zuordnung der grünen Häkchen und roten Kreuze zu den Eigenschaften der Autos
Ja/Nein-Fragen oder Multiple Choice, welche Autos zur Anfrage passen
Weiterführende Kapitel zu OR oder NOT als Pfad mit Auswahlmöglichkeit integrieren
Bibliotheksführungen durch Rallyes
Anstelle von Bibliotheksführungen können Rallyes konzipiert werden, in denen auch Videos integriert sind. Dafür kann die Anwendung Actionbound genutzt werden, mit der eine Art Schnitzeljagd und das Sammeln von Punkten möglich ist.6 Es können beispielsweise Bounds mit Erklärvideos und anschließenden Aufgaben innerhalb der Bücherei eingebunden werden.7
Das entspricht zwar nicht einem interaktiven Video an sich, hat aber den gleichen Effekt: Es wird sich aktiv mit den Inhalten auseinandergesetzt und die Teilnehmenden können gleichzeitig ihr Wissen überprüfen.
Abschlussquiz
Überprüfen Sie hier Ihr Wissen über den Beitrag. Viel Spaß!
Quellen
1 Lehner, Franz (2011): Interaktive Videos als neues Medium für das eLearning. HMD Praxis der Wirtschaftsinformatik Jg. 48, H. 1, S. 51-62. Online unter https://doi.org/10.1007/BF03340549 [Abruf am 28.01.2022]
2 Gantert, Klaus (2016): Bibliothekarisches Grundwissen. 9., vollständig neu bearbeitete und erweiterte Auflage. Berlin, Boston: De Gruyter Saur. Online unter https://doi.org/10.1515/9783110321500 [E Book]
4 Schlottke, Natalie (2021): Die Anwendung des Modells „Komplexitätsstufen von aktivierenden Lernressourcen“ auf die Förderung von Informationskompetenz in deutschen Hochschulbibliotheken. Brake (Unterweser). Online unter https://doi.org/10.25968/opus-1856 [Bachelorarbeit]
6 Nachtwey, Frank (2017): Bibliotheken und mobiles Lernen. Neue Services zur Wissensvermittlung. In: Thissen, Frank (Hg.): Lernen in virtuellen Räumen. Perspektiven des mobilen Lernens. Berlin, Boston: De Gruyter Saur, (Lernwelten) S. 110-124. Online unter https://doi.org/10.1515/9783110501131-008 [E-Book]
7 Zwick, Simon; Lengler, Cynthia; Hamer, Ilka; Güzelmeriç, Annette; Schatz, Eugenie; Wiethoff, Dörthe; Küpper, Florian; Deeg, Christoph (2016): Die Bibliothek spielerisch entdecken mit der Lern-App Actionbound. In: Bibliothek Forschung und Praxis, Jg. 40, Nr. 1, S. 50–63. Online unter https://doi.org/10.1515/bfp-2016-0005