Die digitale Transformationist ein stetiger Wandlungsprozess, die in allen Lebensbereichen stattfindet. Im öffentlichen Leben, im Beruf und im privaten Umfeld schreitet die Digitalisierung voran und macht damit auch vor Bibliotheken nicht Halt.
Vom digitalen Lesesaal zum virtuellen Begegnungsort
Bereits seit längerer Zeit haben Bibliotheken sogenannte digitale Lesesäle in ihrem Angebot. Hinter dem Begriff versteckt sich noch häufig ein Konzept, das den Online-Zugang zu digitalen Medien einer Einrichtung ermöglicht. Ein Beispiel dafür ist der digitale Lesesaal der Österreichischen Nationalbibliothek.
Bei internetaffinen Bibliotheksnutzer*innen und Digital Natives weckt der Begriff des digitalen Lesesaals allerdings andere Erwartungen.
Durch die Lockdowns im Zuge der Covid-19-Pandemie erkannten viele Bibliotheken die Chance das Konzept des „Dritten Orts“ auf eine digitale Ebene zu verpflanzen. Diese Räume sind mehr als ein Zugang zu digitalen Medien. Sie bieten die Möglichkeit zur Begegnung und zum interaktiven Austausch abseits der analogen Welt.
Ein digitaler Raum mit Wonder
Die Universitäts- und Landesbibliothek Bonn gestaltete mit dem browserbasierten Konferenztool Wonder einen digitalen Raum, um mit ihren Nutzer*innen in Kontakt zu treten. Interessierte konnten sich zwischen thematisch gekennzeichneten „Areas“, wie z.B. einer bibliothekarischen Auskunft oder Gruppenräumen, hin und her bewegen und sich flexibel Gesprächsgruppen anschließen, als wären sie vor Ort.
Was kann Wonder?
Wonder ist nach eigener Aussage eine Plattform zum Hosten von Online-Events. Das kostenlose, browserbasierte Tool ermöglicht Usern neben Videokonferenzen das freie Bewegen im Raum. Wer sein Icon auf das Icon einer anderen Person zubewegt, kann so spontan und flexibel in eine Unterhaltung in Form von Voice- oder Videochats einsteigen. Diese Gruppierungen werden bei Wonder „Circles“ genannt.
Als Host des digitalen Raums kann man über eine überschaubare Anzahl von Funktionen und Einstellungsmöglichkeiten verfügen. Im Spaceeditor können beliebig viele „Areas“ erstellt und benannt, das Hintergrundbild des Raums geändert, oder die maximale Teilnehmer*innenzahl eines „Circles“ festgelegt werden. Zusätzlich lässt sich eine Ice-Breaker-Frage einrichten, die alle Personen, die den Raum betreten, beantworten müssen. Die Broadcastfunktion ermöglicht es, eine Übertragung von Bild und Ton an alle anwesenden Personen zu senden und es können Co-Hosts ernannt werden.
Durch die browserbasierte Umsetzung und den schnellen Anmeldeprozess ist Wonder für viele Bibliotheksbesucher*innen einfach und niedrigschwellig nutzbar. Die Broadcast-Funktion ermöglicht es außerdem, größere Veranstaltungen wie Lesungen oder Schulungen durchzuführen. Kolleg*innen können ohne Probleme zu Co-Hosts ernannt werden. Darüber hinaus ist ein hervorstechendes Merkmal, dass das Tool kostenlos ist. Eine kleine Einschränkung ist, dass die Anwendung nicht tablet- oder smartphonefähig ist. Auch sind die gestalterischen Möglichkeiten, was die Individualisierbarkeit des Raums angeht, stark begrenzt.
Mit WorkAdventure einen Schritt weiter gehen
Mit Tools wie WorkAdventure kann noch ein Schritt weiter gegangen werden. Hier bietet sich die Möglichkeit, digitale Räume zu erschaffen, die ihr analoges Gegenstück nachahmen und repräsentieren können. Diese Welt lässt sich von Besucher*innen mit Hilfe eines persönlichen Avatars erkunden.
WorkAdventure kann ein virtuelles Büro, ein virtueller Campus, oder eine virtuelle Messehalle sein. Zur Gestaltung des digitalen Raums kann aus einer Vielzahl vorgefertigter Maps mit unterschiedlichen Eigenschaften gewählt werden. Je nach Map ist der Raum für eine Teilnehmer*innenzahl zwischen 10 und 500 Personen ausgelegt. Wer etwas mehr Zeit investieren will und sich mit dem 2D Level-Editor Tiled auseinandersetzt, kann seinen Raum komplett selbst designen. Dabei ist es auch möglich, Schnittstellen zu externen Features im Raum zu verankern. Ein Beispiel: Im virtuellen Raum liegt ein Brettspiel auf einem Tisch. Zwei Avatare treten an den Tisch heran und werden zu einem externen Browsergame weitergeleitet, in dem sie gegeneinander spielen können.
Wer eine vorgefertigte Map nutzt, findet dort unterschiedliche, bereits eingerichtete Zonen vor. Wer mit seinem Avatar, dem sogenannten „WOKA“, einen Gruppenraum betritt, bekommt z.B. das Angebot, durch Drücken der Leertaste einer Videokonferenz beizutreten. Videocalls können jedoch genauso gut eröffnet werden, indem man sich dicht zum „WOKA“ einer anderen Person stellt.
Was kostet WorkAdventure?
WorkAdventure unterscheidet zwischen einer kostenlosen und einer Premiumversion. Mit der kostenlosen Version von WorkAdventure ist die zeitgleiche Nutzung einer Map auf 25 Personen begrenzt. Videokonferenzen innerhalb der Map haben eine Obergrenze von 15 Personen. Es können vorgefertigte oder eigene Maps genutzt werden. „WOKAs“ können auch in der freien Version zu einem gewissen Grad individualisiert werden.
Die Premiumversion ermöglicht zusätzlich ein Zugriffsmanagement, das Ernennen von Moderator*innen, das Versenden globaler Nachrichten, das Aufzeichnen von Meetings und eine Google-Kalender-Integration. Leider verfügt WorkAdventure über keine Funktion, mit der Videobroadcasts an alle Teilnehmer*innen einer Map ausgestrahlt werden können.
WorkAdventure in der Bibliothek
Für Bibliotheken könnte es von Nachteil sein, dass die für sie besonders relevanten Features, wie z.B. eine kurzfristig sehr hohe Teilnehmer*innenzahl, mit der Preiskalkulation von WorkAdventure nicht vereinbar ist. Für manche Bibliotheksbenutzer*innen könnte auch die Hemmschwelle, einen digitalen Raum mit einem Avatar zu betreten, zu hoch sein. Für manche Nutzer*innen sind es aber vielleicht besonders die speziellen Eigenschaften von WorkAdventure, durch die ihre Erwartungen erfüllt werden.
Fazit
Das Projekt Wonder in der ULB Bonn ist inzwischen aufgrund geringer Nutzungszahlen eingestellt worden. Warum das Interesse trotz guter Features gering war, ist unklar. Möglicherweise kann auch der ideale digitale Raum den ersehnten analogen Raum nicht ersetzen. Vielleicht konnte Wonder auch die Erwartungen einer internetaffinen Generation an eine digitale Umgebung nicht erfüllen.
Idealer wäre wohl eine digitale Lösung, die besonders in Zeiten der pandemischen Isolation ein Abtauchen in eine alternative Wirklichkeit ermöglicht, die neues aber gleichzeitig reales Zusammenkommen gestattet. Bibliotheken könnten Initiatoren eines solchen neu gedachten „Dritten Raums“ sein. WorkAdventure macht einen kleinen Schritt in diese Richtung.
Quellen und Verweise
Österreichische Nationalbibliothek: Ihr Zugang zu den digitalen Beständen der Österreichischen Nationalbibliothek. Online verfügbar unter https://www.onb.ac.at/digitaler-lesesaal, zuletzt geprüft am 29.01.2022.
Thorbjørn Lindeijer: Map Editor Tiled. Online verfügbar unter https://www.mapeditor.org/, zuletzt geprüft am 29.01.2022.
ULB Bonn: Gemeinsam lernen und arbeiten im virtuellen Lesesaal der ULB Bonn. Online verfügbar unter , zuletzt geprüft am 28.02.2022.
Wonder Technologies GmbH: Wonder. Online verfügbar unter https://wonder.me/, zuletzt geprüft am 29.01.2022.
WorkAdventure: WorkAdventure. Pricing. Online verfügbar unter https://workadventu.re/pricing, zuletzt geprüft am 29.01.2022.
WorkAdventure: WorkAdventure. Online verfügbar unter https://workadventu.re/, zuletzt geprüft am 29.01.2022.
WorkAdventure: WorkAdventure. FAQ. Online verfügbar unter https://workadventu.re/faq, zuletzt geprüft am 29.01.2022.
Der Anteil an Smarten Sexspielzeugen nimmt immer weiter zu, allerdings stellen Sicherheitslücken und mangelnde Datensparsamkeit bei den Geräten ein Problem dar.
Sehen harmlos aus, schnorcheln aber deine Daten ab: Smarte Sextoys (stock.adobe.com)
Im Jahr 2018 stellte Werner Schober in seinem Vortrag auf dem Chaos Communication Congress mit dem Titel Internet of Dongs – A long way to a vibrant Futureden Inhalt seiner Recherche zu den Security-Problemen bei dem Device „Vibratissimo Panty Buster“ vor. Die Recherche bildete die Grundlage seiner Diplomarbeit. Bei einem Penetration Test war es ihm möglich, auf die Hersteller-Datenbank, auf dessen Server und dadurch auch auf Nutzer:innendaten, wie explizite Fotos, Chatverläufe, sexuelle Orientierung, E-Mail Adressen, gespeicherte Passwörter in Klartext, etc., zuzugreifen. Außerdem konnte er sowohl über die App, als auch über eine Bluetooth-Verbindung auf fremde Geräte zugreifen und diese steuern.
Seitdem hat die Zahl von sogenannten Smarten Sextoys immer weiter zugenommen. Laut einer Recherche von Juniper Research waren im Jahr 2019 etwa 19 Millionen dieser Geräte im Einsatz. 2020 stieg die Zahl um 87% auf 36 Millionen an. Die Zahl der bekannt gewordenen Sicherheitslücken stieg mit. Es sind sozusagen sexuell übertragbare Sicherheitslücken.
Diese Entwicklung bringt zahlreiche Risiken für die eigene (IT-)Sicherheit mit sich. Beispielsweise gelang es Hackern, Kontrolle über einen Smarten Keuschheitsgürtel zu übernehmen. Die Angreifer verlangten von ihren Opfern ein Lösegeld von 0.02 Bitcoin (entspricht derzeit etwa 674 €). „Your Cock is mine now“, lautete die Erpresser-Botschaft der Hacker. Die Schwachstelle, eine ungeschützte API (Programmierschnittstelle), wurde bereits im Oktober des Vorjahres bekannt.
The Cellmate chastity lock works by allowing a trusted partner to remotely lock and unlock the chamber over Bluetooth using a mobile app. That app communicates with the lock using an API. But that API was left open and without a password, allowing anyone to take complete control of any user’s device.
Diesen Vorfall griff auch der Comedian John Oliver in seiner Show „Last Week Tonight“ auf.
Doch nicht nur ungeschützte APIs und ungesicherte Bluetooth-Verbindungen sind ein Problem: Viele Devices wollen zusätzlich auf viele Daten zugreifen, die sie in der Nutzung überhaupt nicht brauchen. So will beispielsweise ein Beckenbodentrainer des Herstellers “Perifit”, mit dem man Spiele wie “Flappybird” steuern kann, Zugriff u.a. auf Kontakte, Gesundheits- und Fitnessdaten sowie Standort der Nutzer:innen. Man kann von einem regelrechten Datenfetisch der Hersteller sprechen.
Viele dieser Smarten Sextoys werden teuer verkauft. Die Shops, in denen sie vertrieben werden, werben mit diskreter Verpackung und dem Schutz der Privatsphäre beim Versand.
Mit dem Useraccount verlinkte Daten bei der App „Perifit“ des Entwicklers X6 Innovations. (Screenshot)
Qualitätsversprechen eines Online-Erotikshops (Screenshot)
Die Produkte sind oft sehr kostspielig und Verkäufer und Hersteller betonen die hohe Qualität der Produkte. Die Sicherheit, die den Käufer:innen hier vermittelt wird, lässt sich im Digitalen leider vermissen.
Es wäre schön, wenn Hersteller dies in Zukunft stärker in Betracht ziehen würden.
Letztenendes ist es am Besten beim Kauf darauf zu achten, auf welche Nutzer:innendaten (z.B. Kontakte, Suchverlauf im Browser, Standort) die zugehörigen Apps zugreifen möchten und diese Zugriffe gegebenenfalls in den Telefoneinstellungen zu unterbinden. Gerade beim Kauf von Sexspielzeug, dessen Missbrauch körperliche Schäden verursachen kann (z.B. ButtPlugs, die sich nicht mehr entfernen lassen), ist es empfehlenswert, auf manuelle Möglichkeiten der Deaktivierung zu achten.
Wer auf dem neuesten Stand bleiben möchte oder sogar helfen will, Smarte Sextoys sicherer zu machen, sollte sich unbedingt die folgenden Blogs anschauen:
Welche Bibliothek kennt es nicht? Die Website wurde vor 20 Jahren erstellt und seither nicht mehr überarbeitet – und das sieht man ihr auch an. So ganz stimmt das natürlich nicht, es kommen schließlich regelmäßig neue Unterseiten für jede neue Dienstleistung, jedes neue Projekt und jede neue Datenbank hinzu. Vom Entfernen, wenn es die Datenbank 5 Jahre später gar nicht mehr gibt, war ja nie die Rede…
Es muss also eine neue Website her. Und diesmal richtig! Diesmal achten wir auf eine ordentliche UX! Aber was ist das eigentlich…?
UX steht für „User Experience“. Dabei geht es nicht nur um die Nutzerfreundlichkeit (Usability) während der Nutzung, sondern auch um die Effekte vor und nach dem Besuch der Website. Die Nutzung soll Spaß machen („Joy of Use“), es geht um Ästhetik und Emotionen. [1] Weg vom einfachen Website-Besuch, hin zum Online-Erlebnis! Noch ausführlicher erklärt wird der Begriff UX, und alles, was er beinhaltet, in folgendem Video (Achtung: Appetit auf Pizza vorprogrammiert!):
Wir kennen jetzt also den Unterschied zwischen UX und Usability – oder?
Nun wollen wir unsere neue Website mit unserem dazugewonnenen Wissen neu ausrichten. Bevor wir aber mit dem UX-Design anfangen können, müssen einige Vorbereitungen getroffen werden.
Schritt 1: Probleme der alten Website analysieren
Seitenbesuche der Enoch Pratt Library. Grafik nach Zhu (2021).
Um Probleme bei der neuen Website zu vermeiden, müssen erstmal die Probleme der alten Website gefunden werden. Ein gute Methode dafür ist die Nutzung eines Analysetools um ausführliche Statistiken über Page Views, Bounce Rates etc. zu erhalten. Die Enoch Pratt Free Library hat bei dieser Analyse beispielsweise herausgefunden, dass über die Hälfte der Seiten ihrer Internetpräsenz weniger als 5 Besuche pro Jahr erhalten und die am häufigsten besuchten Seiten mit über 10.000 Aufrufen pro Jahr nur 2% der Seiten ausmachen. [2] Keep that in mind – mehr dazu später!
Weitere häufige Probleme sind:
mangelnde Aktualität von Inhalten
unübersichtliches Design – besonders auf Mobilgeräten
schlechte Performance der Website
schlechte Benennung von Datenbanken und Angeboten: Weiß jede*r Besucher*in, dass sich hinter dem OPAC der Bibliothekskatalog versteckt?
Schritt 2: Ziele und Zielgruppe
Unsere Zielgruppe ist – besonders im Bereich von öffentlichen Bibliotheken – sehr heterogen. Beispielsweise stellen Jugendliche andere Erwartung an eine Website als Senior*innen und auch die Erfahrungen mit dem Internet sind sehr unterschiedlich. Daher sollte sich die Seite am schwächsten Glied orientieren und die Bedienung so simpel und eindeutig wie möglich sein. Auch die Digital Natives werden sich hierüber nicht beschweren!
Neben der Zielgruppe ist auch die Zielsetzung der Website wichtig. Was soll überhaupt mit der Bereitstellung erreicht werden? Soll die Seite nur bestehende oder auch potenzielle neue Nutzer*innen ansprechen? Soll die Seite Interaktion ermöglichen? Sollen die Nutzer*innen nur erledigen, wofür sie gekommen sind, oder darüber hinaus positiv überrascht werden und Neues entdecken?
Soll heißen: Wer nur die Öffnungszeiten der Bibliothek herausfinden möchte, nimmt die schnelle blaue Route durch das Labyrinth. Der rote „Umweg“ wäre frustrierend. Wer aber gerne Zeit im Labyrinth verbringt, wird auf der roten Route das ein oder andere neue Bibliotheksangebot entdecken. Welcher Weg bietet also die bessere User Experience? Das kann sehr subjektiv sein. Es gilt: Eine gute Usability wird selten explizit wahrgenommen, schlechte Usability hingegen schon. [3]
Schritt 3: Struktur und Design
Jetzt können wir uns endlich der neuen Website widmen. Eine gute Idee ist es, die grundlegende Struktur der Seite durch ein Wireframe darzustellen, bevor im Anschluss das Design – also Logos, Farben, Schriftarten, etc. – implementiert wird.
Unerlässlich für jede Website ist heutzutage ein sogenanntes responsive design, d.h. ein Design, das sich flexibel auf jedes Endgerät einstellt.
„Mobile First“ lautet die Devise! Immerhin ist das Smartphone das meistgenutzte Endgerät zum Surfen, wie Studien zeigen. Daher werden Websites heutzutage für mobile Endgeräte optimiert, Desktop-PCs sind nachrangig. Eine übersichtliche Navigation entsteht hierdurch zwangsläufig.
Ebenso selbstverständlich wie ein responsives Design ist die Barrierefreiheit, um beispielsweise Menschen mit Sehbeeinträchtigungen den Besuch der Website zu erleichtern. Inklusion ist eben nicht nur im Bibliotheksgebäude eine Notwendigkeit.
Schritt 4: Inhalt
Mutig sein!
Durch die Analyse zu Beginn haben wir erfahren, welche Inhalte die Nutzer*innen interessieren und vor allem: welche nicht. Und wenn die Seite noch so schön den monatlichen Töpferkreis aus den 90ern beschreibt und damals furchtbar viel Arbeit bei der Erstellung bereitet hat: Wenn es niemanden interessiert, kommt es raus. Die Enoch Pratt Free Library hat z.B. bei ihrem Re-Design mehr als 1000(!) Seiten entfernt (Ihr erinnert euch: Die Seiten, die weniger als 5 Klicks im Jahr hatten). [2]
Die Themen, die die Besucher*innen am meisten interessieren (vermutlich Öffnungszeiten u.ä.) sollten so leicht wie möglich erreichbar sein, gerade auch auf der mobilen Seite. [2]
Ein Weg, um die vielfältigen Informationen für die verschiedenen Zielgruppen gezielt an den Mann (die Frau, das Kind, die Jugendlichen…) zu bringen, können verschiedene Bereiche für die jeweiligen Gruppen sein.
In einer Bibliothek geht es nicht nur darum, das zu finden, was man sucht, sondern auch das zu finden, von dem man noch gar nicht wusste, dass man es sucht.
Der Online-Katalog sollte daher auf der Bibliothekswebsite nicht nur in Form eines Links auftauchen, sondern bestenfalls vollständige in die Website integriert sein. In die Bereiche für die einzelnen Zielgruppen können zielgruppengerechte Medienvorschläge direkt eingespeist werden – so wie man in der physischen Bibliothek auch Medien durch Frontalpräsentation besonders bewerben würde.
Apropos bewerben: Jede Bibliothek kennt wahrscheinlich das Problem, dass sie tolle digitale Angebote wie bestimmte Datenbanken vorhält, diese aber kaum genutzt werden. Eventuell kann dies an den nichtssagenden Namen liegen – wer weiß schon, dass sich hinter Overdrive ein ähnlicher Anbieter wie die Onleihe verbirgt? Man kann auch nicht davon ausgehen, dass jeder Nutzer Rosetta Stone gleich mit Sprachen verbindet. Solchen Angeboten klare Namen und Beschreibungen zu geben, kann hier also helfen.
Schritt 5: Auswertung und Ausblick
Nachdem die Website programmiert, getestet und hoffentlich erfolgreich eingeführt wurde, können die gleichen Statistiken wie vor der Umstellung erhoben werden. Diesmal natürlich mit hoffentlich besseren Zahlen (falls nicht: diesen Beitrag nochmals lesen & umsetzen).
Die Enoch Pratt Free Library konnte z.B. allein seit Einführung der neuen Website im August 2020 bis Ende 2020 die Bounce Rate um 11,25% verringern. Die Besuche auf bestimmten Seiten erhöhten sich um 57% bis 245%. [2]
Und so kann eine erfolgreiche Umarbeitung dann aussehen:
Für die Zukunft ist es wichtig zu beachten: Die Website ist wie der Medienbestand. Auch ihre Inhalte müssen gepflegt, aktuell gehalten und bei Bedarf ausgesondert werden.
Schlusswort:
Die Website der Bibliothek sollte nicht einfach als Website von Bibliothekar*innen für Bibliothekar*innen betrachtet werden, sondern als virtuelle Zweigstelle für die Nutzer*innen der Bibliothek. Wie eingangs bereits getitelt: Die Website soll nicht über die Bibliothek sein, die Website soll die Bibliothek sein.
@mreidsma The site is most overtly „about the library“ when it should be that the site *is* the library.
— Emily Morton-Owens (@bradamant) April 22, 2014
Mehr zum Thema:
Blenkle, Martin (2014): Amazon & Google als Herausforderung? Nutzerorientierte Gestaltung von Bibliothekswebseiten (PDF)
Im Gegensatz zum statischen Content wird bei interaktiven Inhalten der dynamische Content herangezogen. Das heißt, dass es nicht nur gewöhnliche Texte zum Lesen gibt oder Bilder nur betrachtet werden. Bei interaktiven Inhalten wird der Benutzer auch aktiv in das Geschehen eingebunden. Dadurch wird die Aufmerksamkeit erregt und gewonnen. Daher steigt auch die Motivation sich mit den Inhalten des jeweiligen Themas auseinanderzusetzen. Doch wie kommen diese interaktiven Inhalte zustande? Dafür ist es wichtig zu verstehen, was H5P ist, was es anbietet und wie es funktioniert.
In den letzten Jahren hat H5P zunehmend an Bedeutung gewonnen. Dabei handelt es sich um eine Open-Source-Software, die von der Firma Joubel im Jahr 2013 im Auftrag der NDLA („Norwegian Digital Learning Arena“) entwickelt wurde. Für den Einsatz in (Hoch-)Schulen bietet H5P seit einigen Jahren einen kostenpflichtigen Hosting-Dienst mit zusätzlichen hochwertigen Funktionen an. Diese sind auch für den Einsatz in der Firmenumgebung interessant.
H5P basiert auf modernen Standards wie HTML5, CSS3 und Javascript. Der H5P-Kern ist dabei teils in Javascript, teils in einer Server-spezifischen Programmiersprache wie z. B. PHP geschrieben. Da aber die meisten Funktionalitäten aus Javascript stammen, ist der Teil des H5P-Cores, der portiert werden muss, so klein wie möglich gehalten. H5P kann somit auf unterschiedliche Web-Publishing-Systeme portiert und mit vorhandenen LMS („Lern-Management-Systemen“), wie Moodle, Totara, WordPress oder Drupal, integriert werden. Mittlerweile bieten auch proprietäre LMS, wie etwa Neon LMS, eine H5P-Integration.[1]
Optimierung Ihrer Website mit H5P
H5P macht es einfach, HTML5-Inhalte und -Anwendungen zu erstellen, teilen und wiederverwenden. H5P ermöglicht es jedem, reichhaltige und interaktive Weberlebnisse effizienter zu gestalten– alles, was Sie dazu benötigen, ist ein Webbrowser und eine Website mit einem H5P-Plug-in.[2]
Mobilfreundlicher Inhalt
H5P-Inhalte sind reaktionsschnell und mobilfreundlich. Das bedeutet, dass Benutzer auf Computern, Smartphones und Tablets dieselben reichhaltigen interaktiven Inhalte erleben.[2]
Reichhaltige Inhalte teilen
H5P ermöglicht es bestehenden CMS und LMS, reichhaltigere Inhalte zu erstellen. Mit H5P können Autoren interaktive Videos, Präsentationen, Spiele, Werbung und mehr erstellen und bearbeiten. Inhalte können importiert und exportiert werden. Zum Anzeigen oder Bearbeiten von H5P-Inhalten wird lediglich ein Webbrowser benötigt. H5P-Inhaltstypen und -Anwendungen werden auf H5P.org geteilt. Sie können auf jeder H5P-fähigen Website wie H5P.com oder Ihrer eigenen Drupal- oder WordPress-Website, mit installiertem H5P-Plug-in, erstellt werden.[2]
Kostenlos zu verwenden
H5P ist eine völlig kostenlose und offene Technologie, lizenziert mit der MIT-Lizenz. Demos/Downloads, Anleitungen und Dokumentationen sind für Benutzer verfügbar, die der Community beitreten möchten.[2]
VorteilevonH5P
H5P ist kostenlos verfügbar
H5P ist eine Open-Source-Software und ein Community-Projekt, – jeder kann mitmachen
Keine Programmierkenntnisse notwendig – dank des intuitiven H5P-Editors und der zahlreichen Anleitungen auf H5P.org ist das Erstellen von interaktiven Inhalten kinderleicht
Mehr als 40 Inhaltstypen – und es werden ständig mehr
H5P Inhalte können mit anderen geteilt und wiederverwendet werden
Responsives Design – Interaktionen passen sich allen Endgeräten an
Anwendungsmöglichkeiten
Arten der H5P-Einbettung
Die erste Möglichkeit, H5P einzubetten ist, indem man den Inhalt auf H5P.com erstellt und ihn direkt in die gewünschte Seite einbettet oder über einen direkten Link darauf zugreift. Dafür wird kein LMS benötigt.[3]
H5P.com ist eine SaaS-Lösung („Software-as-a-Service“), das sind cloudbasierte Anwendungen, die über den Webbrowser aufgerufen werden können.[4] Über LTI („Learning-Tools-Interoperability“) können externe Tools, Inhalte und Aktivitäten, die online verfügbar sind, in LMS eingebunden werden. [5] Beispiele dafür sind Moodle LTI Integration, Canvas LTI Integration, Brightspace LTI Integration und Blackboard LTI Integration. H5P.com kann mit fast allen LMS und Systemen, die LTI unterstützen, verwendet werden.[3]
Wenn man H5P selbst hosten möchte, ist dies durch die Verwendung kostenfreier Plug-ins möglich. Offizielle Plug-ins liegen für Drupal, WordPress, und Moodle vor. Es liegen aber von der Community erstellte Plug-ins für weitere Plattformen vor. [3]
Achtung, dies ist nur möglich, wenn Sie als Administrator oder als Benutzer angemeldet sind, denn zum Erstellen einer H5P-Aktivität müssen Sie die Berechtigung in dem entsprechenden Kurs haben.
Gehen Sie zu dem Kurs, in den Sie einen H5P-Inhalt hinzufügen möchten. Es sollte sich ein Fenster öffnen, in das Sie Aktivitäten oder Ressourcen hinzufügen können. Dort klicken Sie auf den Plus-Button. Es öffnet sich ein weiteres Fenster, in dem Sie Aktivitäten oder Ressourcen hinzufügen können. Dort klicken Sie auf „H5P“ in der Kategorie „interaktiver Inhalt“ und fügen diese hinzu. Daraufhin müssen Sie einen Inhaltstypen auswählen, um den H5P-Hub zu öffnen. Sobald sich dieser öffnet, können Sie aus mehreren Inhaltstypen entscheiden, welchen Sie einbauen möchten. Nachdem Sie sich einen ausgesucht haben, rufen Sie ihn auf, wodurch Sie auf die Detailseite des Inhaltstypen gelangen. Dort können Sie die Einzelheiten zu beliebigen Inhaltstypen nachlesen.
Um einen Inhaltstypen zu installieren, müssen Sie rechts daneben auf „Installieren“ klicken. Sobald der Inhaltstyp installiert ist, ist er bereit, eingesetzt zu werden. Sobald Sie nun auf „Verwenden“ klicken, öffnet sich direkt der Editor. Wenn Updates zur Verfügung stehen, werden Sie darüber informiert.
Im H5P-Hub können Sie vorhandene H5P-Inhalte hochladen. Klicken Sie dazu oben auf die Registerkarte „Hochladen“. Sie müssen dann nur noch den Vorgang beenden und Ihre Aktivitäten abspeichern.[7]
Zusammenfassend kann man sagen, dass H5P eine cloudbasierte Anwendung ist, die durch entsprechende Plug-ins in verschiedensten Webseiten integriert werden kann. Dazu zählen auch LMS („Lern-Management-Systeme“).
Lehrende können interaktive Videos, Präsentationen, Spiele und mehr verwenden, um Inhalte zu vermitteln oder übersichtlich darzustellen.
[e] https://www.pexels.com/de-de/foto/architektur-bau-bekannt-beruhmt-149419/ und https://www.pexels.com/de-de/foto/eiffelturm-wahrend-der-nacht-3879071/ [Abruf am 20.02.2022]
Mit 2,9 Mrd. aktiven Nutzer*innen im Monat1 bestimmt Facebook die Informations- und Kommunikationswege. Kritiker werfen der Plattform seit längerem vor, die Privatsphäre von Benutzer*innen zu verletzen und nicht gegen Falschinformationen vorzugehen.
Auf der Suche nach einer möglichen Alternative stolpert man über WT.Social, eine noch unbekannte Plattform von einem nicht unbekannten Gründer. Was steckt hinter dem Dienst und kann dieser als ernsthafte Konkurrenz zu den gängigen sozialen Netzwerken wahrgenommen werden?
The non-toxic social network Welcome to a place where advertisers don’t call the shots. Where your data isn’t packaged up and sold. Where you – not algorithms – decide what you see. Where you can directly edit misleading content. Where bad actors are kicked out and kept out. Where you actually like spending time. Welcome to social media the way it should be. Welcome to WT.Social.
Im Oktober 2019 veröffentlichte der Wikipedia-Gründer Jimmy Wales das soziale Netzwerk WT.Social. Anders als Facebook, Instagram oder Twitter, konzentriert sich WT.Social als „News Focused Social Media“ auf aktuelle Nachrichten und berücksichtigt weniger den persönlichen Aspekt. Wales begründet die Entscheidung damit, dass der Anteil an Fake News in den sozialen Medien zugenommen habe. So möchte er ein nachrichtenfokussiertes Netzwerk aufbauen, worin die Menschen sich frei jeglicher Einflussnahme über das aktuelle Geschehen informieren können.
Der Aufbau erinnert grob an eine Mischung aus Facebook und Reddit: es ist möglich, eigene Beiträge zu verfassen, sich mit anderen Personen zu vernetzen und einen persönlichen Feed zu erstellen.
Keine Werbung, Kein Tracking
Versprochen wird nicht nur der absolute Schutz von Privatsphäre und nutzerbezogenen Daten, sondern auch ein werbefreies und ausschließlich über Spendengelder gefördertes soziales Netzwerk, ähnlich wie Wikipedia. Damit gebietet Wales den Werbefinanzierungen Einhalt, deren Sponsoren häufig vorgeben, was die Nutzer*innen auf ihren Profilen sehen.
Schon vor WT.Social gab es mit Ello oder Diaspora den Versuch einer werbefreien sozialen Plattform. Sie konnten sich jedoch gegen die bekannten Social-Media-Dienste nicht durchsetzen und blieben als Nischenwerkzeuge im Verborgenen.2
Funktionsweise
Alle Mitteilungen sind veränderbar
Es gibt eine Eigenschaft, die WT.Social von anderen sozialen Plattformen unterscheidet: die Nutzer*innen sind in der Lage die Beiträge ihrer Mitmenschen zu bearbeiten! Mit dieser Funktion wird die Handschrift der Muttergesellschaft deutlich. Auch auf Wikipedia kann jeder Artikel von verschiedenen Autor*innen editiert, ergänzt und korrigiert werden.
Um es an einem Beispiel zu verdeutlichen: im Oktober 2020 wurde auf WT.Social ein Link zu einem YouTube-Video geteilt, dessen Inhalt sich eindeutig im Spektrum der Verschwörungstheorien verorten ließ. Weil der Beitrag von jedem angemeldeten Nutzer bearbeitet werden kann, wurde die Meldung einem „Faktencheck“ unterzogen. Nachvollziehbar wird diese Überprüfungsmaßnahme erst mit einem Klick auf den Hinweis Full History rechts vom Beitrag. Hiermit werden frühere Versionen der Mitteilung dokumentiert und aufgezeigt, an welcher Stelle die Nutzer*innen etwas verändert haben.3
Subwikis für Interessen
Wer sich für ein bestimmtes Gebiet interessiert, kann sogenannte Subwikis abonnieren. Subwikis sind gemeinschaftliche Foren, die zum Diskutieren einzelner Themen einladen. Sie reichen von „Fighting misinformation“ (= Falschinformationen bekämpfen) über „Science“ (= Naturwissenschaften) bis hin zu„News about the internet“.4
Auf Twitter und Facebook sind Algorithmen dafür verantwortlich, dass Beiträge im Feed gepusht werden. WT.Social zeigt dagegen – unabhängig von Likes oder Kommentaren – stets die neuesten Mitteilungen als Erste an. Die Einordnung in eine algorithmische Blase soll nicht erfolgen. Gestützt werde dies u.a. durch eine Spenden- statt Werbefinanzierung. Sponsoren üben keinen Einfluss aus und mögliche Falschnachrichten können von der Seite ferngehalten werden.5
Keine Äußerung ist jemals fertig
Für dieses ehrgeizige Ziel trägt hauptsächlich die Community Verantwortung. Hierzu wählte Wales einen radikalen Ansatz. Er transportierte die auf Wikipedia erfolgreiche Methode des Bearbeitens auf die Plattform: jeder Beitrag kann von jedem/jeder Nutzer*in editiert werden. Eigene und fremde Wörter verwachsen miteinander.
Mit der Herangehensweise widerspricht WT.Social dem ursprünglichen Gebot sozialer Medien, dass niemand jemandem reinreden dürfe. Stattdessen sollen in dem Experiment alle Mitglieder*innen dazu angeregt werden, sich vorbildlich zu verhalten und hetzerische Inhalte zu bearbeiten oder gar zu entfernen.
Mögliche Probleme
Zensur?
Die Bearbeitungsfreiheit kann sich als zweischneidiges Schwert erweisen. Während auf anderen sozialen Plattformen jede*r Nutzer*in seine/ihre Gedanken und Vorstellungen ungefiltert präsentieren kann, herrscht auf WT.Social eine „Zensur“ von unten nach oben. Meinungsfreiheit wird hier anders verstanden. Es könnte die Möglichkeit bestehen, dass eine Mitteilung verändert wird, bloß weil es nicht der persönlichen Auffassung eines Nutzers entspricht.
Sortieren?
Nachteilig sind auch die kaum vorhandenen Sortierungsmöglichkeiten. Mittlerweile zählt die Wikipedia-Tochter eine knappe halbe Million Mitglieder*innen. Täglich werden neue Beiträge veröffentlicht, welche sich kaum filtern lassen. Der Überblick geht somit schnell verloren.
Vernetzen?
Ebenfalls ausbaufähig ist die Vernetzungsfunktion. Zwar bietet WT.Social die Option sich mit Familie und Freunden in Verbindung zu setzen, konzentriert sich aber im Allgemeinen auf die News-Features. Für gewöhnlich benutzen wir jedoch soziale Medien gerade wegen der Communities oder um uns zu informieren, was unser Umfeld interessiert und bewegt.
Layout?
Problematisch könnte weiterhin der erste Eindruck sein, den die Plattform vor allem neuen Nutzer*innen verschafft. Mit einer überzeugenden User Experience kann WT.Social nicht punkten. Anders als ihr Vorgänger WikiTribune benutzt das soziale Netzwerk kein WordPress-System, sondern basiert auf einem selbstentwickelten Fundament. Die Optik ist eher gewöhnungsbedürftig und die Benutzeroberfläche schlicht gehalten. Verstärkt wird die Kargheit durch eine hohe Textlastigkeit sowie einen geringen Bildanteil.6
Es kann nur besser werden!
Trotz aller Kritikpunkte wurde das Projekt bewusst als Rohbau herausgebracht. Ganz nach dem Motto von Entwicklern freier Software beabsichtigte Wales eine frühzeitige Veröffentlichung. Von Beginn an würde WT.Social in der Realität getestet werden, um etwaige Anpassungen schnell vornehmen zu können. Da sich das soziale Netzwerk gemeinsam mit seinen Mitglieder*innen entwickeln soll, wären einige Baustellen demnach unvermeidlich.
Ausblick
Mit WT.Social möchte Jimmy Wales in der Social-Media-Landschaft Fuß fassen und diese nachhaltig verändern. Anders als die herkömmlichen sozialen Dienste liegt der Fokus auf dem nachrichtlichen Content. Die Nutzer*innen sollen angeregt werden qualitativen Journalismus zu betreiben und Falschmeldungen zu bearbeiten. Damit die Plattform sich jedoch als Konkurrenz zu Facebook & Co. behaupten kann, müssen zunächst ein paar Voraussetzungen geschaffen werden.
Um sich vom Schatten der Muttergesellschaft zu lösen, müsste WT.Social an ihrem Service und ihrer Benutzeroberfläche arbeiten. Derzeit erinnert das Netzwerk weniger an eine klassische soziale als vielmehr an eine kollaborative Plattform, präsentiert in „a social media way“ – nur dass es sich eben nicht so anfühlt. Eine wichtige Rolle sollten daher auch der Inhalt und die Diskussionen in den Foren spielen.7
Nach knapp anderthalb Jahren kann jedoch noch eine Menge passieren und wohin der Weg letztlich führt, lässt der Gründer offen: „This is a crazy and radical experiment of mine, to which I am happy to say that I do not know all the answers.“
[1] Statista (2021): Number of monthly active Facebook users worldwide as of 3rd quarter 2021. Online unter: https://www.statista.com/statistics/264810/number-of-monthly-active-facebook-users-worldwide/ [Abruf am 16.11.2021] [2] Holzki, Larissa (2019): Wikipedia-Mitgründer Jimmy Wales startet Facebook-Konkurrenz ohne Werbung. Online unter: https://app.handelsblatt.com/technik/it-internet/soziale-netzwerke-wikipedia-mitgruender-jimmy-wales-startet-facebook-konkurrenz-ohne-werbung/25252992.html [Abruf am: 23.11.2021] [3] Bovermann, Philipp (2021): Achtung, an diesem Text wird gebaut!. Online unter: https://www.sueddeutsche.de/digital/jimmy-wales-social-media-facebook-alternative-twitter-1.5173137 [Abruf am: 20.11.2021] [4] Moreau, Elise (2020): WT Social: What It Is and How to Use It. Online unter: https://www.lifewire.com/wt-social-what-it-is-and-how-to-use-it-4783366 [Abruf am: 20.11.2021] [5] Affan, Ahmad (2020): WT Social Media by Wikipedia, Wikitribune Social Review: Features and Future?. Online unter: https://www.linkedin.com/pulse/wt-social-media-wikipedia-wikitribune-review-features-ahmad-affan [Abruf am: 02.12.2021] [6] Polywka, Marlene (2019): „WT:Social“ – was steckt hinter der Facebook-Alternative?. Online unter: https://www.techbook.de/apps/social-media/wtsocial-facebook-alternative [Abruf am: 20.11.2021] [7] Bacon, Jono (2019): WT.Social is Interesting, But Can It Work? Well, Maybe. Online unter: https://www.forbes.com/sites/jonobacon/2019/11/18/wtsocial-is-interesting-but-can-it-work-well-maybe/ [Abruf am: 30.11.2021]
Quelle – Beitragsbild: https://pixabay.com/de/illustrations/wikipedia-b%c3%bccher-enzyklop%c3%a4die-1802614/ Quelle – Subwiki Bild: https://blog.novatrend.ch/2019/12/02/wp-social-waechst/
Ein klassischer hölzerner Zettelkatalog mit dutzenden kleinen Schubladen
Ursprünglich wurden Bibliotheksbestände in Zettelkatalogen verzeichnet. Ein Zettelkatalog bestand aus vielen Katalogkarten (oder Zetteln), wobei auf jedem Zettel genau eine der in der jeweiligen Bibliothek vorhandenen Publikationen verzeichnet wurde. Die Zettel wurden üblicherweise in extra dafür angefertigten Katalogkästen nach dem Alphabet geordnet aufbewahrt. Meist wurden mehrere Zettelkataloge geführt, die nach verschiedenen Kriterien (Verfassernamen, Themen, Titel der Publikation) geordnet waren. Diese benötigen aber viel Platz und die Recherchemöglichkeiten sind limitiert – in der Regel sind Zettelkataloge nach dem Nachnamen der Autoren aufgestellt, manchmal auch unter dem Titel des Werks. Ist beides nicht bekannt, kommen Bibliotheksnutzende schnell an ihre Grenzen und werden im schlechtesten Fall gar nicht fündig.
Deshalb entstanden in den späten 1970ern die ersten digitalen Kataloge in Bibliotheken, vorrangig an solchen mit wissenschaftlichem Schwerpunkt, und legten den Grundstein für den modernen OPAC.1
Was ist eigentlich ein OPAC?
OPAC steht für "Online Public Access Catalogue". Es ist ein international genutzter Begriff, der Online-Kataloge von Bibliotheken bezeichnet.2
Aber auch die ersten digitalen Kataloge bestachen noch nicht durch eine große Auswahl an Sucheinstiegen oder Komfortfunktionen, über die heutige OPACs verfügen. Im Laufe der Zeit wurden bekannte Funktionen wie Trunkierungen etabliert, die inzwischen als selbstverständlich gelten. An eine erweiterte bzw. Expertensuche, die es ermöglicht, exakt nach dem Erscheinungsjahr, der Sprache oder dem Verlag des gewünschten Titels zu suchen, war beim Gebrauch eines Zettelkatalogs nicht zu denken. Zudem erleichterten diverse Anzeigemöglichkeiten wie eine Sortierung nach Erscheinungsdatum oder Relevanz die Recherche.3
Anfangs gestaltete sich die Etablierung des OPACs als schwierig, da sie eine gravierende Umstellung für Bibliothekspersonal und -nutzende bedeutete. Die gesamte Herangehensweise musste geändert werden, um das Gewünschte erfolgreich recherchieren zu können. Manche Bibliotheken hielten ihren OPAC unter Verschluss, sodass er nur für das Personal nutzbar war. Das Übertragen der Daten aus dem Zettelkatalog in ein digitales Format war zeitaufwendig. Manche Bibliotheken übertrugen deshalb keine Altbestände, nutzen den OPAC nur für die Suche nach neuen Medien und parallel den Zettelkatalog, um nach älteren Beständen zu recherchieren.4
Vor der Verbreitung des Internets waren OPACs nur vor Ort in den jeweiligen Bibliotheken nutzbar, seit Mitte der 1990er Jahre können die meisten aber bequem von Zuhause eingesehen werden.5
OPAC-Recherchestationen früher und heute
Usability eines modernen OPACs
Unter Usability versteht man die Gebrauchstauglichkeit von Produkten. Dabei geht es um die Betrachtung, wie effektiv, effizient und zufriedenstellend die Nutzung eines Produktes ist.7 Für den Bereich des Onlinekatalogs liegt momentan das Augenmerk auf dem Angebot der Recherchemöglichkeiten, den Onlineservices im Benutzerkonto und der Barrierefreiheit.
Für die Recherche bieten moderne Onlinekataloge meist verschiedene Recherchewege an. Die von Nutzenden am häufigste verwendete ist die Einfache Suche über einen Suchschlitz, wie er insbesondere durch Google bekannt ist. In einem nächsten Schritt können die Ergebnisse über sogenannte Facetten weiter eingegrenzt werden. Über die erweiterte Suche lassen sich je nach OPAC-Anbieter vor dem Beginn der Suche die Ergebnisse, beispielsweise nach einem Medientyp oder einem Autor, eingrenzen. Eine weitere Möglichkeit ist der Gebrauch von Schlagworten bei der Recherche.
Durch den OPAC können die Nutzenden auf das eigene Benutzerkonto zugreifen und dort verschiedene Services nutzen. So können Nutzende einsehen, welche Medien sie entliehen haben, diese verlängern oder sie bei der Nutzung von E-Medien auch online zurückgeben. Einige OPACs bieten ihren Nutzenden den Service, nicht verfügbare Medien vorzumerken oder sich für angebotene Veranstaltungen anzumelden.
Die Umsetzung der Barrierefreiheit bei der Nutzung eines Onlinekatalogs beschäftigt momentan die meisten Bibliotheken.
Was ist Barrierefreiheit?
Die barrierefreie Gestaltung von digitalen Angeboten, bedeutet diese auch für Menschen mit körperlichen oder kognitiven Einschränkungen uneingeschränkt und eigenständig, bzw. mit Hilfe von Assistenzprodukten, nutzbar zu machen.8
Visionen für die Zukunft
Sowohl wissenschaftliche als auch öffentliche Bibliotheken haben erkannt, dass ein Onlinekatalog ihren Nutzenden einen weitaus größeren Mehrwert bieten kann, als nur eine vielfältigeres Recherchetool zu sein oder den Zugriff auf das eigene Benutzerkonto zu bieten.
Viele Bibliotheken legen den Fokus schon jetzt eher aufs Stöbern als auf das gezielte Suchen. Nutzende sollen nicht zwingend mit einem exakten Titel in die Recherche starten müssen, sondern sich vom Angebot der Bibliothek inspirieren lassen. Dabei helfen z.B. Themen- bzw. Genre-Sucheinstiege, Titel, die dem gerade aufgerufenen ähnlich sind, oder eine Sortierung nach Beliebtheit. Auch Neuerscheinungen oder gerade zurückgegebene Medien können direkt auf der Startseite angepriesen werden.
Bei der Entwicklung von OPACs wird vermehrt Wert darauf gelegt, sie auf Mobilgeräten mindestens genauso funktional und ansprechend benutzbar zu machen wie auf dem klassischen PC oder Laptop. Mobile Endgeräte haben stationäre überholt und sind das beliebtere Mittel der Nutzenden um im Internet zu surfen – und um Recherchen durchzuführen.9
Eine weitere zukunftsweisende Idee ist, Nutzende beim Bestandsaufbau und der Erschaffung inhaltlichem Mehrwerts der Medienbeschreibungen mit einzubeziehen. So können Anschaffungswünsche anonym oder auch personenbezogen über ein Formular geäußert werden. Ein OPAC-Anbieter macht den Nutzenden persönliche Lesevorschläge anhand der Titel die andere Leser auch ausgeliehen haben. Die Nutzenden können Medien mit Sternen bewerten und eigene Rezensionen schreiben.
Youtubevideo zur Gestaltung eines OPACs zur Kundengewinnung
Denkbare Weiterentwicklungen sind Wunschlisten und die Benachrichtigung über neuerworbene Titel aus diesen Listen. Für eine neue Ausstellung im Schiller-Nationalmuseum in Marbach soll ein digitales Miniaturmodell eines literarischen Gedächtnisspeichers entstehen, der aus verschiedenen Perspektiven erforscht und erfahren werden kann.10
Abschließend lässt sich sagen: Ein OPAC muss einfach und intuitiv zu bedienen sein und eine Suche schnell zum Ziel führen. Gleichzeitig soll er aber auch zum Verweilen und Stöbern einladen und Nutzende auf die vielen verschiedenen Möglichkeiten hinweisen, die die Bibliothek bietet, ohne überladen zu wirken.
Themenverwandte Blogs
Digitale Transformation – Digitale Leseräume als neuer Ort des Zusammenkommens
Die Website ist die Bibliothek
Quellen
1Frank, Silke (o.J.): Gestaltung von Benutzeroberflächen und Recherchemöglichkeiten bei OPACs: State of the art und Trends. Berlin: Institut für Bibliotheks- und Informationswissenschaft (Berliner Handreichungen zur Bibliotheks- und Informationswissenschaft, Heft 188). S. 9
2vgl. IGI-Global (2022): What is OPAC. Online unter: https://www.igi-global.com/dictionary/social-software-use-public-libraries/21147 [Abruf am 07.03.2022]
3vgl. Störberl, Cornelius (2016): Discovery-System versus OPAC der Herzog August Bibliothek. Eine vergleichende Studie der Recherchefunktionalitäten. Hannover, Hochschule Hannover. S. 4-5
4vgl. Bowman, J. H. (2007): OPACs: the early years, and user reactions. London: University College. Library History, Vol. 23. S. 317-318
5vgl. Klaus Gantert (2016): Bibliothekarisches Grundwissen. 9., vollständig neu bearbeitete und erweiterte Auflage. München: Saur. S. 228.
6vgl. Tiemann, Sarah (2016): Vom klassischen OPAC zum modernen Rechercheportal : Ansätze zur Einführung eines Discovery Systems an der ZHB Lübeck. Berlin: Institut für Bibliotheks- und Informationswissenschaften der Humboldt-Universität. (Berliner Handreichungen zur Bibliotheks- und Informationswissenschaft , Bd. 406). S. 16
7vgl. Grünwied, Gertrud (2017): Usability von Produkten und Anleitungen im digitalen Zeitalter. Handbuch für Entwickler, IT-Spezialisten und Technische Redakteure. Erlangen. Publicis Publishing. S. 11
8vgl. ebenda S. 76
9vgl. Enge, Eric (2021): Mobile vs. Desktop Usage in 2020. Online unter: https://www.perficient.com/insights/research-hub/mobile-vs-desktop-usage [Abruf am 16.03.2022]
Wie kodiere ich einen Stammbucheintrag mit XML-TEI und welchen Nutzen hat die Anwendung dieser Mark-Up-Language bei der Erschließung des Eintrags für die Forschung? Mit diesen Fragen befasst sich dieser Beitrag.
Zum Abschied bekam ich ein Album Amicorum – in Holland, Deutschland und in den skandinavischen Ländern ist das eine beliebte Sitte. Man geh mit diesem Buch zu einem Freund, der etwas Selbsterfundenes hereinschreibt oder einen Ausspruch irgendeines Autors, und seinen Namen daruntersetzt; wenn er kann, zeichnet er noch etwas hinzu. So hat man etwas mit dessen Hilfe man sich an seine Freunde erinnern kann. Keine schlechte Idee, aber auch ein bisschen skurril.1
James Boswell
Den meisten von Ihnen dürfte der von James Boswell 1764 in seinem Journal beschriebene Brauch aus Kindheitstagen bekannt sein, denn beim hier erwähnten Album Amicorum – auch Stammbuch genannt -, handelt es sich um ein frühes Poesiealbum. Im Gegensatz zu heute waren jedoch meist Erwachsene, die als Stammbuchhalter bezeichnet werden, die Besitzer dieser Alben, die sie auch auf Reisen mit sich trugen.
Entstanden ist diese Tradition Mitte des 16. Jahrhundert in Wittenberg, als es Mode wurde, die Autographen der Reformatoren um Luther zu sammeln. Anfangs vor allem unter Studenten Anklang findend, waren die Stammbücher später in fast allen Gesellschaftsschichten beliebt und erfreuten sich im Besonderen in Deutschland bis Mitte des 20 Jahrhunderts gesellschaftlicher Wertschätzung. 2
Stammbücher können in verschiedenen Disziplinen als wertvolle Quelle dienen. So geben sie Auskunft über die Studienorte und Reiserouten sowie die sozialen Netzwerke ihrer Eigentümer. 3
Ferner lassen sich Rückschlüsse über die Alltagskultur ziehen und sie fungieren als Zeugnisse der Wissenschaftsgeschichte und Literaturhistorie. Für Sprachwissenschaftler sind die Alben inbesondere wegen der Vielfalt der Sprachen, in denen die Beiträge verfasst sind, von Interesse.4
Viele Bibliotheken und Archive sind heute im Besitz von Stammbüchern. Die weltweit größte Sammlung stellt die der Herzogin Anna Amalia Bibliothek mit über 1900 dieser Freundschaftsbücher dar.
Zentral für die Einrichtungen ist es dabei, die Erforschung ihrer Sammlungen zu ermöglichen. Doch wie soll das realisiert werden? Neben der zunehmenden Digitalisierung rückt auch eine tiefergehende Erschließung der Alben in den Fokus. So kann beispielsweise im Katalog der Herzogin Anna Amalia Bibliothek seit einiger Zeit nach Einträgen, Einträgern, Erscheinungsorten und Erscheinungsjahren der Stammbücher recherchiert werden. Die UB Tübingen wiederum stellt Transkriptionen ihrer Freundschaftsbücher zur Verfügung, die mit TEI kodiert wurden.
2. Was ist TEI?
TEI, kurz für „Text Encoding Initiative“, ist ein Dokumentenformat, das auf der Markup-Language XML basiert und der Auszeichnung von Texten dient. Beschrieben wird es in den TEI Guidelines. Neben dem Markup von textgestalterischen bzw. strukturellen Elementen, wie beispielsweise Absätzen, Zeilenumbrüchen oder der Position einer Illustration, können auch semantische Auszeichnungen vorgenommen werden. Hierzu zählt etwa die Kennzeichnung von Personennamen oder Orts- und Datumsangaben. TEI stellt heute den De-facto-Standard bei der Textkodierung dar und kommt daher bei der Erstellung von Digitalen Editionen regelmäßig zum Einsatz.5
Während jedoch beispielsweise mit TEI erstellte Briefeditionen häufiger vorkommen, sind – mit Ausnahme des Tübinger Projekts – mittels TEI kodierte Stammbucheinträge bislang sehr rar gesät.
3. Kodierung des „Werther-Stammbuchs“ mit TEI
Welche Vorzüge die Kodierung von Stammbucheinträgen mit TEI für die Forschung mit sich bringt und wie bei der Auszeichnung vorgegangen werden kann, soll daher nachfolgend exemplarisch anhand TEI-kodierter Eintragungen aus dem auch als „Werther-Stammbuch“ bezeichneten Album von Ludwig Schneider (1750-1826), einem Juristen, veranschaulicht werden.
Den inoffiziellen Titel „Werther-Stammbuch“ trägt es, da es einen deutlichen Bezug zu Goethes Aufenthalt in Wetzlar im Sommer 1772 aufweist, als dieser die Bekanntschaft mit Charlotte Buff, dem Vorbild für Werthers Lotte sowie deren Verlobten Johann Christian Kestner machte. Von allen drei Personen finden sich Einträge im Stammbuch.6
Kodierung des Stammbucheintrags von Christian Albrecht von Kielmannsegg
Wie auch anhand der von Christian Albrecht von Kielmannsegg, ebenfalls Jurist und Jugendfreund Goethes, gestalteten Seite (Abbildung 2) deutlich wird, weisen Stammbucheinträge, die als Inskriptionen bezeichnet werden, typischerweise eine Zweiteilung auf. Auf eine im weiteren Sinn poetische Textpassage folgt in der Regel eine Widmungspassage, die aus immer wiederkehrenden Strukturelementen besteht.
Auszeichnung der Widmungspassage
Unter „Adressierung“ fallen alle Elemente, die Informationen über den Stammbuchhalter enthalten. Je nach Charakter der Beziehung kann hier die namentliche Nennung variieren. Des Weiteren kann sie durch Statusangaben angereichert werden.7
Die Elemente der „Motivierung“ und „Charakterisierung“ sind oftmals nur schwer voneinander abzugrenzen, da sie häufig fließend ineinander übergehen. Während die Komponente der Motivierung den Fokus auf den Schreibanlass legt, definiert sich die Charakterisierung dadurch, dass auf die vorangegangene Textpasssage zurückverwiesen wird. Der Stellenwert des Textteils wird hervorgehoben und Aussagen über seine Funktion getroffen.8
Den Abschluss der Passage bildet in der Regel eine sogenannte Sprachhandlungsformel, die das Verfassen des Stammbucheintrags meist als „schenken“, „widmen“, „sich empfehlen“, näher definiert.9
Dieser charakteristische Aufbau lässt sich durch TEI nachbilden. Wie das Codebeispiel zum Eintrag von Kielmannsegg zeigt, wurde der eigentliche Text als <div> (Textabschnitt) getaggt, während die Widmungspassage mit dem Element <closer> ausgezeichnet wurde, das aus der Briefedierung stammt.
[C]loser> fasst Grußformeln, Datumszeilen und ähnliche Phrasen zusammen, die am Ende eines Abschnitts stehen.10
</teiHeader>
<text type="Stammbucheintrag">
<body>
<div type="Dramenverse">
<cit>
<quote xml:id="Fußnote1">
<l>Am beſten iſt, und wahrſten der mein Freund,</l>
<l>Der warm, nicht heiß das Gute, das ich habe;</l>
<l>Der ſtreng nicht, doch genau den Fehl auch ſieht.</l>
<l>Hat dieſer Freund ein Herz der Redlichen,</l>
<l>So liebt er mich, wie ich geliebt mag ſayn.</l>
</quote>
<bibl>
<author ref="http://d-nb.info/gnd/118563386" rend="underlined"
>Klopstock</author>.</bibl>
</cit>
</div>
<closer>
<salute rend="right"><seg type="Adressierung">dem Herrn Beſitzer dieſes
Buchs</seg>
<seg type="Schreibhandlungsformel">em-<lb/>pfiehlt ſein Andenken beſtens
und gehorſamſt.</seg></salute>
<signed rend="right">
<persName ref="http://d-nb.info/gnd/116157372"><forename><choice>
<abbr>C.</abbr>
<expan>Christian</expan>
</choice></forename><surname> Kielmannsegg</surname></persName> aus <placeName
ref="http://d-nb.info/gnd/4038197-3">Meklenburg</placeName></signed>
<dateline rend="left"><placeName ref="http://d-nb.info/gnd/4065878-8"
>Wetzlar</placeName>, den <date when="1773-05-16">16ten May 1773</date></dateline>
</closer>
</body>
<note type="editorial" target="#Fußnote1">Die Verse wurden dem Trauerspiel <name type="work"
>David.Ein Trauerspiel</name> von <persName ref="http://d-nb.info/gnd/118563386"
><forename>Friedrich Gottlieb</forename><surname> Kloppstock</surname></persName>
entnommen.</note>
</text>
</TEI>
Innerhalb dieses Abschnitts wiederum wurden die Adressierung und Sprachhandlungsformel näher spezifiziert. Zunächst wurden sie durch das Element <salute> als Bestandteil der Grußformel ausgewiesen und anschließend anhand des <seg>-Elements (Segment) in Verbindung mit dem type-Attribut eindeutig als Addressierung (<seg type=“Adressierung“) bzw. Schreibhandlungsformel (<seg type=“Schreibhandlungsformel“) gekennzeichnet.
Als problematisch kann sich in diesem Zusammenhang die Tatsache erweisen, dass XML keine Überlappungen zulässt. So ist es grundsätzlich möglich, dass Textteile sowohl Bestandteil der Motivierung als auch der Charakterisierung sind und sich darüber hinaus gleichzeitig der Sprachhandlungsformel zuordnen lassen. Als pragmatische Lösung hierfür bietet sich jedoch an, nur die jeweils charakteristischen Worte den entsprechenden Bestandteilen der Widmung zuzuordnen.
Der Name bzw. die Unterschrift des Einträgers wird als <signed> (Unterschrift) getaggt und als <persName> – unterteilt in <fore- und surname> – erfasst, während Orts- und Datumsangabe zunächst unter <dateline> zusammengefasst und dann durch <placeName> bzw. <date> gekennzeichnet werden. Durch die Verwendung des when-Attributs in Verbindung mit <date> wird das Datum zusätzlich noch in maschinenlesbarer und normierter Form aufgenommen. Das <signed>-Element dient dazu, dass der Name des Einträgers später eindeutig maschinell herausgefiltert werden kann, da an mehreren Stellen im Stammbucheintrag Personennamen in unterschiedlichen Funktionen vorkommen können. Eine Besonderheit stellt hier die Auszeichnung des Namens dar. Kielmannsegg hat seinen Vornamen mit C. abgekürzt, was durch das Element <abbr>, Abbrevation kodiert wird. TEI lässt es jedoch zu, durch das Element <expan> (Expansion) gleichzeitig den ermittelten, vollen Namen anzugeben.
Auch ein weiterer großer Vorteil der Verwendung von TEI wird in diesem Zusammenhang deutlich. So ist es durch das ref-Attribut möglich auf Normdaten zu referenzieren. Konkret wurde hier mittels des Attributs bei <persName> der GND-Eintrag des Verfassers Christian Kielmansegg verlinkt. Auch bei den Entitäten Eintragungsort und Herkunftsort des Verfassers, ebenfalls durch <placeName> ausgezeichnet, wurde ein Link zum GND-Eintrag aufgenommen.
Neben der eindeutigen Identifizierung kann diese Erfassung der Normdaten der Erforschung und Visualisierung von Personennetzwerken oder der Sichtbarmachung der Wege und Aufenthaltsorte des Stammbuchhalters sowie der Einträger dienen.
Dazu ein Beispiel aus der Goethe-Forschung: Lange ging man davon aus, dass Johann Caspar Goethe, der Vater des berühmten Dichters, zu einem bestimmten Zeitpunkt Berufspraxis in Wien sammelte, da er dies in einem Bittgesuch an Kaiser Karl zu Protokoll gegeben hatte. Anhand von zwei Stammbucheinträgen konnte man jedoch nachweisen, dass er tatsächlich aber -mutmaßlich im Rahmen einer Bildungsreise – in Augsburg weilte und auch, dass er nicht alleine reiste, da sich eine weitere Person, Johann Georg Cocceji, jeweils am selben Tag wie Goethe in beide Stammbücher eintrug. 11
Die Position der Grußformel und Datumszeile auf der Seite, die sich in vielen Stammbucheinträgen wiederfindet, lässt sich durch das Attribut rend=“right“ oder rend=“left“ ausdrücken, z. B. <dateline rend=“left“>.
Auszeichnung der Textpassage
Werfen wir nun einen Blick auf die der Widmung vorangestellte Textpassage. Typischerweise besteht diese aus wenigen Gedichtversen oder knappen Prosatexten, die zum Nachdenken angeregen, Einsichten vermitteln oder an das Befolgen bestimmter Maxime appellieren.12 Im Regelfall handelt es sich dabei um bereits bestehende Texte, die wortgenau oder leicht verändert, mit oder ohne Angabe des Urhebers, zitiert werden.13
Auch Kielmansegg bedient sich eines bereits vorhandenen Textes. So zitiert er ein Werk Friedrich Gottfried Kloppstocks. Der Zitatcharakter des Elements wurde durch das Element <quote> deutlich gemacht.
Da der Einschreiber außerdem Kloppstock als geistigen Schöpfer angegeben hatte, wurden diese Quellenangabe und das Zitat zusätzlich durch das Elternelement <cit> (cited quotation) ausgezeichnet. So heißt es in den TEI:
Dabei wird der gesamte Zitatblock, inklusive Zitat und Quelle, mit dem dafür vorgesehenen <cit>-Element umschlossen. Die Quellenangabe wird mit dem <bibl>-Element kodiert, das […] unstrukturierte bibliografische Angaben repräsentiert.14
Innerhalb der Quellenangabe wurde Kloppstock mit <author> getaggt und der GND-Normdatensatz verknüpft. In einem editorischen Stellenkommentar <note>, der über eine xml:ID und das Attribut target mit der referenzierten Passage verknüpft ist, können zusätzliche Informationen zum Text festgehalten werden. In diesem Fall wurde darauf hingewiesen, dass die Verse dem Trauerspiel „David“ von Kloppstock entnommen sind.
Das Zitat wiederum wurde zusätzlich mit dem Element <div> ausgezeichnet , was erst einmal recht allgemein für Textabschnitt steht. Durch die Verwendung des Attributs type, konnte jedoch eine Aussage über die Gattungszurordnung, hier type=“Dramenverse“ getroffen werden.
An dieser Stelle wird deutlich, dass die TEI-Kodierung nicht nur in Bezug auf die personengeschichtliche Forschung, sondern auch im Hinblick auf die in den letzten Jahren stärker werdende Beschäftigung mit der literarischen Gestaltung der Stammbucheinträge Potential bietet. So werden intertextuelle Verweise sichtbar und eine Auswertung der Kodierung lässt beispielsweise Aussagen über die Häufigkeit der Zitierung bestimmter Autoren oder die Verwendung von Textgattungen zu. Angesichts der wachsenden Zahl an Werknormdaten in der Gemeinsamen Normdatei wäre es in diesem Zusammenhang zukünftig wünschenswert, auch auf diese zu verweisen. Im Fall des Kloppstockschen Trauerspiels war leider kein Normdatensatz vorhanden.
Auch Besonderheiten bei der textlichen Gestaltung können ausgezeichnet werden. So wird die Unterstreichung des Namen Kloppstock durch das Attribut rend=“underlined“ ausgedrückt und die verwandten langen s („ſ“) der Kurrentschrift werden durch Unicode dargestellt.
Neben den Texten finden sich auch immer wieder Illlustrationen in den Stammbüchern. Bei der Erstellung bediente sich der Einschreiber den unterschiedlichsten künstlerischen Techniken, die von Bleistift- Buntstift-, Kohle- und Tuschezeichnungen über Aquarellmalereien und Gouache zu Druckgrafiken reichen. Ebenso vielfältig ist auch die Wahl der Motive. So finden sich darunter zum Beispiel Wappenzeichnungen oder Porträts, aber auch Bildgegenstände, die sich auf den Text, den Eigentümer des Stammbuchs oder sein Verhältnis zum Einträger beziehen.15
Auszeichnung der Bildbeigabe
Auch diese bildlichen Elemente können durch TEI ausgezeichnet werden. So wurde die Vogel-Zeichnung (Abbildung 3) in dem hier in Auszügen vorgestellten kodierten Eintrag von Dietz Kayß zunächst mittels <div type=“Bildbeigabe“> getaggt und zusätzlich mit dem Element <figure> als Abbildung ausgezeichnet. Durch das type-Attribut wurde sie näher als Tuschezeichnung klassifiziert. Mittels des Elements <graphic> in Kombination mit dem Attribut url kann die Quelle angegeben werden. <FigDesc> (description of figure) ermöglicht eine detailllierte Beschreibung des Bildinhalts.
Die Kodierung der graphischen Bestandteile des Eintrags erlaubt es auch hier, die Daten später gezielt maschinell auszulesen, um beispielsweise Aussagen über die Verwendungshäufigkeit von Techniken oder Motiven zu treffen.
</teiHeader>
<text type="Stammbucheintrag">
<body>
<pb n="60"/>
<div type="Bildbeigabe">
<figure type="Tuschzeichnung">
<graphic url="bildconcordia.jpeg"/>
<figDesc>Bei der Abbildung handelt es sich um die Zeichung eines Vogels im Flug,
mutmaßlich einer Taube, der ein Spruchband mit der Aufschrift "Concordia" im
Schnabel hält. In der rechten oberen Ecke des Bildes ist eine strahlende Sonne mit
grimmigen Gesichtsausdruck zu sehen. Augenscheinlich wurde die Zeichnung mit
brauner Tinte angefertigt.</figDesc>
</figure>
</div>
Die Auszeichnung der Textkomponente dieser Inskription (Abbildung 4) wiederum zeigt, dass TEI auch der Erforschung, in welchen Sprachen die Stammbucheinträge verfasst wurden, Rechnung trägt. So wurde das erste Zitat, bei dem es sich um eine Gnome – also einen Sinnspruch – handelt, mit dem Attribut xml:lang und dem Sprachcode „la“ ausgezeichnet, um auszudrücken, dass es, abweichend vom restlichen Text, in lateinischer Sprache vorliegt. In diesem Zusammenhang wurde auch durch @rend=“latintyp“ die Verwendung der lateinischen Schrift gekennzeichnet.
Bei den darunter befindlichen Versen konnte durch das <rhyme>-Element zunächst deutlich gemacht werden, dass es sich um einen Reim handelt und mittels des Attributs label wurde zusätzlich das hier verwendete Reimschema getaggt.
Als problematisch erwies sich die Kodierung des Studentenordens im Beispiel. Eigentlich eher ein Schriftsymbol – und damit textuelles Element – wurde er dennoch in Ermangelung einer spezifischeren Auszeichnungsmöglichkeit als Abbildung getaggt.
<pb n="61"/>
<div type="Gnome">
<p><quote xml:lang="la" rend="latintyp" xml:id="Fußnote1">Amicus certus in re incerta
cernitur</quote></p>
</div>
<div type="Gnome">
<quote>
<lg type="rhyming_couplet">
<l>Gute Freunde in der <rhyme label="a">Noth</rhyme></l>
<l>gehen tausend auf ein <rhyme label="a">Loth</rhyme></l>
</lg>
</quote>
</div>
<closer>
<salute rend="right">
<seg type="Adressierung">
<choice>
<abbr>HochEdelgebℓ</abbr>
<expan>Hochedelgeborener</expan>
</choice> Herr und <choice>
<abbr>Br.</abbr>
<expan>Bruder</expan>
</choice></seg>
</salute>
<salute rend="right">
<seg type="Motivierung">Habe die Gewogenheit, und erinnere<lb/> Dich öfters Deines<lb/>
<choice>
<abbr>gehorſℓ</abbr>
<expan>gehorſamen</expan>
</choice>
<choice>
<abbr>Dr.</abbr>
<expan>Dieners</expan>
</choice> und Freunds</seg></salute>
<signed rend="right">
<abbr>K.A.F.</abbr>
<unclear reason="illegible" cert="medium"><persName><forename>Dietz</forename>
<surname>Kayß</surname></persName></unclear>. <abbr>Not.</abbr></signed>
<dateline rend="left"><placeName ref="http://d-nb.info/gnd/4020989-1">Giesen</placeName><lb/>
<date when="1771-03-28">28.3.1771</date>
</dateline>
</closer>
<figure type="Zeichen_eines_Studentenordens" rend="left">
<figDesc>Zeichen eines Studentenordens, enthält augenscheinlich die Zahl 1770 und ein
C</figDesc>
</figure>
</body>
<note type="editorial" target="#Fußnote1">Gnome wird <persName
ref="http://d-nb.info/gnd/118520814"><forename>Marcus Tullius</forename>
<surname>Cicero</surname></persName>zugeschrieben.</note>
</text>
</TEI>
4. Ausblick
Generell stellen neben den Illustrationen auch die vielfältigen anderen Beigaben eine Herausforderung bei der Kodierung von Stammbucheinträgen mit TEI dar. Mitunter findet man Papierschnitte, Stickarbeiten, getrocknete Blumen, Siegelabdrücke, Musiknoten, aber auch Haarlocken sind keine Seltenheit.16
Während für die Kodierung von Siegeln mit <seal> ein spezifisches Element zur Verfügung steht und auch Musiknoten innerhalb eines Textes sich über <notatedMusic> taggen lassen bzw. für Musiknoten mit den MEI sogar eigene Codierungsrichtlinien existieren, sind die TEI für die Auszeichnung der anderen (dinglichen) Objekte (zumindest bislang) nicht ausgelegt.
Auch im Hinblick darauf, dass diese Beigaben sich ebenso bei Briefen finden lassen, wäre eine Weiterentwicklung der TEI in dieser Hinsicht wünschenswert. Festzuhalten bleibt aber auch, dass diese Mark-Up-Language bereits jetzt durch die inhaltlich, formal und strukturell tiefgehende Erschließung der Einträge neue Perspektiven für die Stammbuchforschung eröffnen kann.
[metaslider id=“16967″]
Zum Download als PDF-Datei stehen nachfolgend die vollständigen Kodierungen der im Text erwähnten Beispiele sowie weitere exemplarisch kodierte Stammbucheinträge bereit:
Die dazugehörigen Digitalisate sind in der Slideshow (Abbildung 5-8) zu finden.
Falls Sie noch nicht mit TEI vertraut sein sollten, diese Mark-Up-Sprache jedoch Ihr Interesse geweckt hat, finden Sie beispielsweise im Internetauftritt der Universität Bern einen ausführlichen Crashkurs und Workshop.
Quellen
1Boswell, James: Journal, hrsg. von Helmut Winter. Stuttgart 1986. Zitiert nach Linhart, Eva: Vom Stammbuch zum Souvenir d’Amité. Deutscher Schicksalsfaden. In: Schmidt, Volker [Hrsg.]: Der Souvenir : Erinnerung in Dingen von der Reliquie zum Andenken. Köln 2006, S. 202-232 ↩
4Vgl. Eberhards Karls Universität Tübingen [Hrsg.]: Stammbücher der UB Tübingen. Stand 25.01.2021. http://www.dh-profil.uni-tuebingen.de/tuebinger-stammbuecher/index.html, Zugriff 23.01.2022↩
5Vgl. Universität Graz. Zentrum für Informationsmodellierung in den Geisteswissenschaften [Hrsg.]: Text Enconding Initiative. 2006-2008. , Zugriff 23.01.2022 ↩
6Vgl. Heumann, Konrad: Bedeutendes Stammbuch der Wertherzeit. (Unveröffentlichtes Typoskript) ↩
7Vgl. Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 22↩
8Vgl. Schnabel, Werner Wilhelm: Das Album Amicorum. Ein gemischtmediales Sammelmedium und einige seiner Variationsformen. In: Kramer, Anke [Hrsg.]: Album : Organisationsform narrativer Kohärenz. Göttingen 2013, S. 213-239, hier S. 215; Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 22↩
9Vgl. Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 22↩
10Text Encoding Initiative. P5: Richtlinien für die Auszeichnung und den Austausch elektronischer Texte. Version 4.3.0. Last updated on 31st August 2021. https://tei-c.org/release/doc/tei-p5-doc/de/html/ref-closer.html, Zugriff 23.01.2022↩
11Vgl. Heumann, Konrad: Unterwegs nach Italien. Johann Caspar Goethes Reise nach Nürnberg und Augsburg im Jahr 1739. In: Hopp, Doris: »Goethe Pater». Johann Caspar Goethe (1710–1782). Frankfurt 2010, S. 52-61↩
12Vgl. Schnabel, Werner Wilhelm: Das Album Amicorum. Ein gemischtmediales Sammelmedium und einige seiner Variationsformen. In: Kramerm Anke [Hrsg.]: Album : Organisationsform narrativer Kohärenz. Göttingen 2013, S. 213-239, hier S. 215↩
13Vgl. Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 20↩
14Karl-Franzens-Universität Graz [Hrsg.]: Elektronische Repräsentation mit dem Standard der TEI↩
15Vgl. Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 21; Schnabel, Werner Wilhelm: Das Stammbuch : Konstitution und Geschichte einer textsortenbezogenen Sammelform bis ins erste Drittel des 18. Jahrhunderts. Tübingen 2003. S. 104↩
16Vgl. Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 21; Schnabel, Werner Wilhelm: Das Album Amicorum. Ein gemischtmediales Sammelmedium und einige seiner Variationsformen. In: Kramer, Anke [Hrsg.]: Album : Organisationsform narrativer Kohärenz. Göttingen 2013, S. 213-239, hier S. 218↩
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2021/22, Dr. Stefanie Elbeshausen) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Bibliotheken haben den Auftrag, Medien und Informationen für Nutzerinnen und Nutzer aufzuarbeiten und bereitzustellen. Doch jedes Jahr werden mehrere Millionen Publikationen veröffentlicht. Die DNB allein verzeichnete den Zugang 2.352.693 neuer Einheiten im Jahre 2020[1]. Wer soll da den Überblick behalten? Text und Data Mining kann hier Abhilfe schaffen.
Text Mining, Data Mining, Text Data Mining, Textual Data Mining, Text Knowledge Engineering, Web Mining, Web Content Mining, Web Structure Mining, Web Usage Mining, Content Mining, Literature Mining und sogar Bibliomining[2] – viele Begriffe, die alle das selbe Konzept – teilweise mit unterschiedlichen Schwerpunkten – bezeichnen, welches im Folgenden Text und Data Mining, kurz TDM, genannt werden soll. Grob gesagt ist damit die algorithmusbasierte automatische Analyse digitaler Daten jeglicher Form gemeint.
TDM beinhaltet dabei explizit sowohl die Verarbeitung natürlichsprachiger Texte, sogenannter unstrukturierter Daten, als auch beispielsweise Tabellen und anderer strukturierter Daten, welche unterschiedliche Anwendungsfälle und Herausforderungen mit sich bringen. Dabei gibt es zwei große Aspekte: das Auffinden bereits bekannter Informationen und die Schaffung neuen Wissens durch die Verknüpfung oder Neuinterpretation von Bekanntem.[3]
Ganz allgemein lassen sich Verfahren des TDM in drei große Bereiche aufteilen:
Musterextraktion (Programm analysiert, welche Daten oft gemeinsam auftreten)
Es lässt sich natürlich noch feiner unterteilen in Regressionsanalysen, Abhängigkeits- oder Abweichungsanalyse, Beschreibung, Zusammenfassung, Prognose, Assoziation etc., was die große Bandbreite an Nutzungsmöglichkeiten des TDM aufzeigt[4], für uns aber gerade zu weit geht, da wir nur den Bereich der Bibliotheken betrachten wollen.
Anwendungsmöglichkeiten für Bibliotheken
Empfehlungssysteme
Eine Möglichkeit der Kataloganreicherung ist die Implementierung eines Empfehlungsdienstes. Dieser analysiert Recherche- und/oder Ausleihdaten, um Nutzenden während ihrer Recherche weitere Medien vorzuschlagen, die relevant für sie sein könnten[5]. Ein solcher Dienst ist BibTip, welcher an der Universität Karlsruhe entwickelt wurde und mittlerweile von vielen wissenschaftlichen und öffentlichen Bibliotheken in Deutschland verwendet wird.
Maschinelle Indexierung
Die inhaltliche Erschließung bietet einen großen Mehrwert bei der Recherche, ist jedoch ein zeit- und personalaufwendiger Aspekt der bibliothekarischen Arbeit. Schon 2009 begann die Deutsche Nationalbibliothek, diese Arbeit mit maschineller Unterstützung durchzuführen. Dabei wurden die in der GND hinterlegten Schlagwörter als Grundlage für die automatische Verschlagwortung mithilfe des Averbis-Programms verwendet.[6]
Herausforderungen
Urheberrecht
TDM war viele Jahre eine rechtliche Grauzone. Unklarheiten bezogen sich unter anderem darauf, ob maschinelle Verarbeitung durch die bestehenden Lizenzverträge abgedeckt war, ob temporäre für die Auswertung erstellte Kopien unerlaubte Vervielfältigung bedeuteten, inwieweit die Ergebnisse Dritten zugänglich gemacht werden durften und vieles mehr.[7] Die Urheberrechtsnovelle 2018 sorgte für mehr Klarheit, indem durch § 60d UrhG explizit die Nutzung von TDM für die wissenschaftliche Forschung erlaubt wurde.
Datenschutz
Datenschutz ist vor allem bei der Verarbeitung personenbezogener Daten wie der Analyse von Ausleih- oder Recherchevorgängen relevant. Im Sinne der Datensparsamkeit dürfen nur so viele Daten erhoben werden, wie erforderlich sind und diese auch nur so lange wie nötig gespeichert werden. Aus Datenschutzgründen werden die Daten deshalb anonymisiert gespeichert und verarbeitet. Dies schränkt beispielsweise die Empfehlungsdienste ein, da so nur die aufgerufenen oder ausgeliehenen Medien während eines einzelnen Vorgangs analysiert werden, diese jedoch nicht mit früheren Vorgängen der selben Person verknüpft werden können.
Formatvielfalt
TDM kann nur funktionieren, wenn die auszuwertenden Daten in geeigneter Form vorliegen. Dabei kann es verschiedene Hürden geben, sowohl rechtlicher Natur, wenn Daten im Besitz von Personen oder Institutionen sind, sowie technischer Natur, wenn Daten nicht in maschinenlesbarer Form vorliegen, oder zu viele verschiedene (inkompatible) Dateiformate genutzt werden.[8]
Ausblick
Schon heute profitieren Bibliotheken von TDM-Anwendungen, besonders Empfehlungsdienste sind verbreitet. Maschinelle Indexierung wird zumindest vereinzelt eingesetzt, bleibt in der Qualität aber noch weit hinter der intellektuellen Erschließung durch Menschen zurück.[9] Aufgrund des technischen Fortschritts und dem immer zuverlässiger werdenden natural language processing darf man hier jedoch hoffnungsvoll in die Zukunft blicken.
Doch Bibliotheken sind nicht nur Anwenderinnen, sondern können und sollten ebenfalls Sorge dafür tragen, dass ihre eigenen Bestände für TDM nutzbar sind. Dies wird erleichtert durch § 60d UrhG, aber sollte auch bei der Aushandlung von Lizenzverträgen, bei der Auswahl der anzubietenden Formate von elektronischen Medien wie auch bei der Retrodigitalisierung beachtet werden.
Quellen
[1] Deutsche Nationalbibliothek (2021): Jahresbericht 2020. S.45. Online unter urn:nbn:de:101-2021051859
[2] Mehler, Alexander; Wolff, Christian (2005): Einleitung: Perspektiven und Positionen des Text Mining. In: LDV-Forum, Jg. 20, Nr. 1, S. 1–18. Online unter urn:nbn:de:0070-bipr-1688
[3] Saffer, Jeffrey; Burnett, Vicki. (2014). Introduction to Biomedical Literature Text Mining: Context and Objectives. In Kumar, Vinod; & Tipney, Hannah (Hg.): Biomedical Literature Mining. New York: HumanaPress, Springer. S. 1–7. Online unter doi.org/10.1007/978-1-4939-0709-0_1
[4] Drees, Bastian (2016): Text und Data Mining: Herausforderungen und Möglichkeiten für Bibliotheken. In: Perspektive Bibliothek, Jg. 5, Nr. 1, S. 49-73. Online unter doi.org/10.11588/pb.2016.1.33691
[5] Mönnich, Michael; Spiering, Marcus (2008): Erschließung. Einsatz von BibTip als Recommendersystem im Bibliothekskatalog. In: Bibliotheksdienst, Jg. 42, Nr. 1, 54–59. Online unter doi.org/10.1515/bd.2008.42.1.54
[6] Uhlmann, Sandro (2013): Automatische Beschlagwortung von deutschsprachigen Netzpublikationen mit dem Vokabular der Gemeinsamen Normdatei (GND). In: Dialog mit Bibliotheken, Jg. 25, Nr. 2, S.26-36. Online unter urn:nbn:de:101-20161103148
[7] Okerson, Ann (2013): Text & Data Mining – A Librarian Overview [Konferenzbeitrag]. Herausgegeben von IFLA. Online unter http://library.ifla.org/252/1/165-okerson-en.pdf (Abruf am 29.01.2022)
[8] Brettschneider, Peter (2021): Text und Data-Mining – juristische Fallstricke und bibliotheksarische Handlungsfelder. In: Bibliotheksdienst, Jg. 55, Nr. 2, S. 104-126. Online unter doi.org/10.1515/bd-2021-0020
[9] Wiesenmüller, Heidrun (2018): Maschinelle Indexierung am Beispiel der DNB. Analyse und Entwicklungmöglichkeiten. In: O-Bib, Jg. 5, Nr. 4, S. 141-153. Online unter doi.org/10.5282/o-bib/2018H4S141-153
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2021/22, Dr. Stefanie Elbeshausen) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Wie sich die Fan-Fiction-Kultur professionalisiert und was aus dieser Entwicklung erwächst
Abschnitt 1 – Der ReichenbaChfall
Altes Konzept – modernes Phänomen
„Handschrift“ by Rob van Hilten is licensed under CC BY-NC-SA 2.0
Das Weitererzählen, Verändern oder Umformen bestehender Erzählungen hat eine lange Historie und Tradition.
Im Mittelalter wurden antike Stoffe aufgegriffen und für die bestehende höfische Gesellschaft neu interpretiert und arrangiert. Auch die Artus-Sage wurde vielfach aufgegriffen und in Versform gegossen. Für die eigene Erzählung griff man dabei fast immer auf bereits bestehendes Material zurück. Alles war miteinander verwoben.
Auch Bertold Brechts berühmte Dreigroschenoper ist eine Bearbeitung eines bestehenden Werkes. Der Dramatiker ließ sich von der Beggar’s Opera aus dem Jahr 1728 inspirieren. Einige Lieder, die Brecht in seinem Stück verwendet, stammen zudem von dem spätmittelalterlichen Dichter François Villon. Brecht übernahm sie wortgetreu. Ohne Quellenangabe.[1]
Ein weiteres modernes Beispiel ist der Kosmos von H. P. Lovecraft, der noch zu seinen Lebzeiten durch Erzählungen von befreundeten Autoren, mit denen er rege korrespondierte, angereichert und erweitert wurde.
Fan Fictions und schriftbasierte Roleplaying-Games, die an ein beliebtes Buch, eine Serie oder einen Film anknüpfen, reihen sich also in eine lange Tradition der Stoffadaption ein. Was sie machen ist somit keineswegs neu. Doch aufgrund ihrer Form und der veränderten Bedingungen sind sie doch etwas vollkommen Neuartiges – ein modernes Phänomen. Ein Phänomen, das von Beginn an ein Spannungsfeld erzeugte.
Denn nach wie vor sind die meisten Fan Fictions und RPGs eigentlich illegal.
Wie sich die Fan-Fiction-Kultur entwickelte
Im Jahr 1893 stürzen zwei Männer in den Tod. Die tragische Szene ereignet sich in der Schweiz, aber sie wird vor allem in Großbritannien für große Bestürzung sorgen. Aber auch für Empörung und Unverständnis. Dabei sind die beiden zu Tode gekommenen Männer nicht einmal real. Es sind fiktive Figuren. Der eine ist der »Napoleon des Verbrechens«, der andere der vermutlich schon damals berühmteste Detektiv der Welt – Sherlock Holmes.
„‚The Death of Sherlock Holmes‘ (frontispiece from The Memoirs of Sherlock Holmes, 1894)“ by Toronto Public Library Special Collections. Licensed with CC BY-SA 2.0.
Arthus Conan Doyle tötet den Protagonisten seiner Detektivgeschichten und die Tat treibt seine Leser auf die Straße. Öffentlich wird der Tod der literarischen Figur betrauert. Weil Doyle erst 1903 ein Einsehen hat und Holmes von den Toten auferstehen lässt, vernetzen sich die Leser miteinander, um das Gedenken an den Detektiv lebendig zu halten.[2] Damit legen sie den Grundstein für das erste organisierte Fandom. In verlagsunabhängig publizierten Magazinen und Essays werden Figuren und Handlung besprochen, Lücken gefüllt und kontradiktorische Angaben in den Geschichten diskutiert.[3]
Die Begrifflichkeit Fan Fiction etabliert sich in den 1960ern, als das Star-Trek-Universum immer mehr Menschen in seinen Bann zieht und mit Spockanalia das erste Fanzine entsteht, in dem Fans Bilder, Kommentare und eigene Geschichten publizieren.[4]
Seitdem entstanden unzählige weitere Fandoms, basierend auf Filmen, Serien, Büchern oder Comics und sie alle fanden in den 90ern im Internet eine neue Heimat, das mit seinen Möglichkeiten der weltweiten Vernetzung, Interaktion und Publikation optimale Bedingungen für die kreative Fankultur bot.
Verbreitung im Internet
»Heute ist Fan Fiction ohne die zugrunde liegenden digitalen Praktiken der Vernetzung von Dokumenten und Akteuren kaum mehr denkbar.«
Reißmann, Klaas, Hoffmann: Fan Fiction, Urheberrecht und Empirical Legal Studies
Fan Fictions fanden zunächst über fandom-spezifische Foren und Mailinglisten Verbreitung[5], waren aber auch bald schon auf eigenständigen Plattformen zu finden. Dadurch konnten sie mitunter eine große Leserschaft gewinnen. Die größten Plattformen und Archive diese Art, wie die englischsprachigen Seiten ‚Archiv of your own‘ (AO3) und ‚FanFiction.net‘, haben heute Nutzerzahlen in Millionenhöhe.[3]
Durch die Vernetzung der Community entstehen ständig neue Projekte. Es kommt zu Kooperation oder inhaltlichen Crossovers, bei denen Charaktere aus verschiedenen Vorlagen aufeinandertreffen.
Fan Fictions sind aber nicht die einzige Ausdrucksform literarischer Kreativität von Fans im Internet. In forengestützten Role-Playling Games (RPGs) werden Geschichten aus Sicht einzelner Figuren kollaborativ erzählt. Als Grundlage dient dabei meist ein spezifisches Universum, das durch die verschiedenen Handlungsstränge stetig erweitert, verändert oder neu ausgestaltet wird. Durch den kollektiven Schreibprozess kommt es zu einer Verschmelzung von Autor und Leser und oft auch zu einer starken Identifizierung mit der eigenen Figur.
Die Urheberrechtsproblematik
Durch das Internet wurden Fan Fictions immer mehr zu einem Massenphänomen. Die bereits bestehende Frage, in welchem Rahmen die Nutzung von urheberrechtlich geschütztem Material in einem nicht-kommerziellen Kontext praktiziert werden kann, gewann durch diese Entwicklung neue Brisanz. Denn was im Privaten problemlos möglich ist, erhält im Internet eine ganz andere Dimension.
Sobald ein Text der Allgemeinheit zugänglich gemacht wird, und dazu zählt auch das Publizieren in Foren oder Online-Archiven, fällt er unter geltendes Recht. Und dieses besagt:
»Bearbeitungen oder andere Umgestaltungen des Werkes dürfen nur mit Einwilligung des Urhebers des bearbeiteten oder umgestalteten Werkes veröffentlicht oder verwertet werden.«
§ 23 UrHG
Dieser Schutz gilt bei literarischen Werken nicht nur für die Gesamtdarstellungen, sondern auch für einzelne Figuren, sofern deren Darstellung charakteristisch für das Werk ist. Gemeint sind damit handelnde Figuren mit Wiedererkennungswert, wie bpsw. Harry Potter oder Bella Swan, aber auch Nebenfiguren, wie Severus Snape oder Charlie Swan, Bellas Vater.
»Der Gestaltenschutz der Rechtsprechung honoriert somit die individuelle Konzeption einer fiktiven Figur.«
Claudia Summerer: „Illegale Fans“
Allerdings gibts es unter Juristen eine differenzierte Debatte darüber, wie eng oder weit der Gestaltenschutz gefasst werden kann und sollte.[6] Für Fan-Fiction-Autoren und RPG-Autoren ist diese Uneindeutigkeit ein Unsicherheitsfaktor, da im Zweifelsfall unklar bleibt, ob bspw. bereits die Zuschreibung bestimmter Charakteristiken für eine bestimmte Figur den Gestaltenschutz berührt oder nicht.
Mit dieser Problematik befasst sich auch Rechtsanwalt Christian Solmecke in seinem Video zum Thema Urheberrecht und Fan Fiction.
In der Fan-Fiction-Community (RPGs mit eingeschlossen) herrschte lange die Annahme vor, sich in einer rechtlichen Grauzone zu bewegen. Mitunter wird auch heute noch vereinzelt davon ausgegangen.
Gründe für diese Annahme waren und sind zum einen Differenzen zwischen verschiedenen nationalen Rechtsnormen, wie dem deutschen Urheberrecht und dem amerikanischen Copyright Law, aber auch einzelne Aspekte der jeweiligen Gesetze.
Das Urheberrecht unterscheidet bspw. zwischen freier Benutzung und unfreier Bearbeitung.[7] Die freie Benutzung greift immer dann, wenn ein urheberrechtlich geschütztes Werk lediglich als Inspirationsquelle verwendet wird und das neu entstandene Werk selbst urheberrechtlich schutzfähig ist. Dafür müssen beide Werke jedoch ausreichend unterschiedlich sein. Trifft dies zu, dann gilt:
»Ein selbständiges Werk, das in freier Benutzung des Werkes eines anderen geschaffen worden ist, darf ohne Zustimmung des Urhebers des benutzten Werkes veröffentlicht und verwertet werden.«
§ 24 UrhG
Ab wann sich zwei Werke ausreichend voneinander unterscheiden, ist allerdings nicht näher bestimmt. Es sollte daher nicht verwundern, dass die freie Benutzung von Fan-Fiction- und RPG-Autoren im Zweifelsfall weiter gefasst wurde und wird als von Urheberrechtsinhabern.
Es muss jedoch davon ausgegangen werden, dass bereits die Erwähnung charakteristischer Handlungsorte oder Nebenfiguren, selbst wenn der Rest des Werkes eindeutig eine kreative Eigenleistung darstellt, dazu führen kann, dass das gesamte Werk nicht mehr im Einklang mit dem Recht auf freie Benutzung steht.
E. L. James, Autorin von Fifty Shades of Grey, änderte aus einem ähnlichen Grund, noch bevor ihre Geschichte als Buch publiziert wurde, die Namen ihrer Protagonisten, die an Edward Cullen und Bella Swan angelegt waren, ab.
Dem Gestaltenschutz, der nicht näher definierten Trennlinie zwischen freier Bearbeitung und unfreier Benutzung, sowie weiteren rechtlichen Unsicherheiten wird durch die gängige Praxis Tribut gezollt, in einem Disclaimer auf die Rechteinhaber des Ausgangsmaterials zu verweisen und sich von allen Eigentumsansprüchen an den verwendeten Figuren und übernommenen Inhalten freizusprechen.
Diese Disclaimer, egal welcher Art, haben jedoch keine rechtliche Gültigkeit und schützen im Zweifelsfall nicht vor einer Abmahnung oder Anklage. Diese Tatsache ist auch bereits seit langem in der Community bekannt, dennoch werden Disclaimer standardmäßig verwendet, weil sie a) zum guten Ton gehören b) den Schöpfer des zugrundeliegenden Werks würdigen und c) nach außen signalisieren, dass sich die Autoren bewusst sind, dass sie ein urheberrechtlich geschütztes Werk als Grundlage für ihre eigenen Texte verwenden und es sich somit nicht heimlich „aneignen“.
Die Urheberrechtsreform
Auch die Urheberrechtsreform, die 2018 vom EU-Ministerrat auf den Weg gebracht und im März 2019 vom EU-Parlament beschlossen wurde und bis zum 07. Juni 2021 in nationales Recht umgesetzt werden muss, half nicht dabei, die bereits bestehenden Unsicherheiten auszuräumen. Zwar waren Fan-Fiction- und RPG-Autoren von der Reform allenfalls indirekt betroffen, bedingt durch den allgemeinen Aufschrei im Internet und den massiven Protest, der sich sowohl im Digitalen als auch auf der Straße formierte, wurde allerdings ein neues Bewusstsein für geltende Rechtsnormen und bestehende Probleme geschaffen.
Aber auch außerhalb der Community geriet durch die Urheberrechtsreform einiges in Bewegung. Fan Fictions wurden bspw. im Kontext der Grundsatzdiskussion über das Urheberrecht in Bezug auf Mashups und Remixes thematisiert[8] oder zum Gegenstand wissenschaftlicher Forschung.
An der Universität Siegen befasste sich eine Projektgruppe im Rahmen des Sonderforschungsbereichs „Medien der Kooperation“ am Beispiel von Fan Fiction mit den sozialen und juristischen Rahmenbedingungen kooperativen und derivativen Werkschaffens im Netz. Die Projektleiterin Dr. Dagmar Hoffmann (Professorin für Medien und Kommunikation) kommt zusammen mit Dr. Wolfgang Reißmann dabei zu folgender Einschätzung:
»Zwar suggeriert die derzeitige Situation – zumindest im Bereich Fan Fiction – eine Koexistenz der kreativen Fans, die gewisse rote Linien nicht überschreiten, und der Medienindustrie, die von weitgehender Verfolgung absieht. Dieses fragile Nebeneinander kann letztlich jedoch nicht darüber hinwegtäuschen, dass für die Fans Rechtsunsicherheit besteht und sie im Zweifelsfall, wenn ihr Handeln nicht in die Verwertungs- und Marketingstrategien der großen Medienunternehmen passt, rechtlich am „kürzeren Hebel“ sitzen.«
Selbstbestimmung in Fan-Fiction-Kulturen. In: M&K, Jahrgang 66 (2018), Heft 4.
Die beiden Forscher äußern im Weiteren ihre Hoffnung, dass die wissenschaftliche Betrachtung eine produktive Grundlage für die bestehende Auseinandersetzung bieten wird.
Derzeit zeigen sich die meisten Autoren und Verlage aufgeschlossen gegenüber dem kreativen Schaffen der Fans. Ohne eine Sicherheiten schaffende Reformierung des geltenden Urheberrechts auf nationaler Ebene bleibt die Fan-Fiction-Kultur damit aber abhängig vom guten Willen und der Duldung der Urheberrechtsinhaber.
Dass eine solche Toleranz keinesfalls selbstverständlich ist, hat die Vergangenheit gezeigt.
Abschnitt 3 – Trends und Herausforderungen
Wie Autoren die Fan-Fiction-Kultur bewerten
Zu Beginn des neuen Jahrtausends spitzte sich der Konflikt zwischen Rechteinhabern und Fan-Autoren zu. Es wurde mit Abmahnungen gedroht und vereinzelt kam es auch zu juristischen Auseinandersetzungen.[9] Einzelne Autoren ging es darum, die alleinige Deutungshoheit über ihr Schaffenswerk zu behalten, andere fürchteten Plagiate und Umsatzeinbußen durch Fan Fictions.
Die kommerzielle Verwertung von Fan Fictions und RPG-Inhalten spielte allerdings weder zum damaligen Zeitpunkt noch danach eine relevante Rolle. Auch Plagiate blieben eine absolute Seltenheit. Stattdessen erkannten große Verlage und Markeninhaber, dass die Fan-Fiction-Kultur vor allem positive Effekte hervorruft, bspw. indem sie zur Bekanntheit eines Werkes beiträgt oder für eine langfristige Kundenbindung sorgt.[9]
Das veränderte die Wahrnehmung der Fan-Fiction-Kultur, die nun weitaus positiver bewertet und auch von einigen äußerst populären Autoren, wie J. K. Rowling, Stephanie Meyer oder Terry Pratchett, als Würdigung ihrer eigenen Werke verstanden wurde. Das führte im Allgemeinen zu einem weniger konfrontative Umgang mit Fan-Fiction- und RPG-Autoren.
Trotzdem befassen sich auch aufgeschlossene Schriftsteller meistens nicht direkt mit den Texten ihrer Fans, zum einen weil sie mögliche Rechtsstreitigkeiten von vorneherein vermeiden wollen, aber auch, um nicht in einen Interessenskonflikt zu geraten. Im Regelfall bleiben Fan Fictions daher bewusst unbeachtet. Die meisten erfolgreichen Autoren sind sich allerdings ihrer schreibenden Fans bewusst.
Fortschreitende Professionalisierung
Inzwischen ist aber nicht nur die Außenwahrnehmung von Fan Fictions eine andere, auch die Fan-Fiction-Kultur hat sich stetig verändert und weiterentwickelt. Durch neue Plattformen, wie Wattpad, aber auch ein gewandeltes Selbstverständnis der Autoren befindet sich die Community in einem Prozess der Professionalisierung.
Hinter großen Online-Archiven und Plattformen aber auch kleineren RPG-Foren stehen Administratoren- und Support-Teams, die sich um den technischen Unterbau kümmern. Moderatoren betreuen die Community, kontrollieren den Einhalt der Regeln und schlichten Streitigkeiten. Archive of Our Own bietet seinen Mitgliedern im Einzelfall sogar Unterstützung bei Rechtsstreitigkeiten.
»We are committed to defending fanworks against legal challenges. Our position on transformative fanworks is detailed in the OTW FAQ. We have legal resources and alliances on which we can draw. However, that is not a guarantee that the organization can or will fight each battle. The Board will take into account a variety of factors, both legal and otherwise, in responding to a legal challenge.«
AO3 – Terms of Service – What we believe
„Spend“ by 401(K) 2013. Licensed with CC BY-SA 2.0.
Diese Arbeit wird entweder durch Spenden finanziert (z. B. bei AO3) oder durch Werbeeinnahmen (z. B. bei Wattpad). Generell ausgeschlossen ist jedoch weiterhin, dass die Autoren mit ihren Geschichten Geld verdienen. An diesem Grundsatz, der aufgrund der urheberrechtlichen Bestimmung eigentlich nicht verhandelbar ist, wird derzeit jedoch gerüttelt. Auf Patreon suchen inzwischen auch vermehrt Fan-Fiction-Autoren nach monetärer Unterstützung, was in der Community recht kritisch gesehen wird, weil befürchtet wird, dass, sollten immer mehr Autoren diesem Beispiel folgen, die Duldung von Fan Fiction durch die Rechteinhaber auf’s Spiel gesetzt wird.
Für die großen Plattformen ist dies ebenfalls ein Problem. Bei AO3 ist die Verbreitung von kommerziellen Produkten und Aktivitäten bspw. generell untersagt. Bereits die Verlinkung auf Patreon ist in diesem Kontext hochproblematisch, weshalb es immer wieder zur Sperrung von Accounts kommt. Letztlich können aber auch die Plattformbetreiber die Nutzung von Patreon nicht unterbinden.
Im Bereich der RPGs ist diese Entwicklung eher irrelevant, da an den kollaborativ erzählten Geschichten kein einzelner Autor die Rechte daran für sich allein beanspruchen und auf diesem Wege monetarisieren könnte.
Ob die Nutzung von Patreon und ähnlicher Angebote daher zu einem Problem für die Fan-Fiction-Kultur an sich wird, ist zumindest im Moment noch nicht klar. Zweifelsohne wird diese Entwicklung aber zu neuerlichen Debatten über die derzeit geltenden rechtlichen Bestimmungen führen und gegebenenfalls sogar eine juristische Nachjustierung erzwingen.
Die Urheberrechtsreform ist zwar erst vor 2 Jahren beschlossen worden und wird erst in diesem Jahr in nationales Recht umgesetzt, das bedeutet aber noch lange nicht, dass sie auch auf der Höhe der Zeit ist.
[9] Reißmann, Wolfgang; Hoffmann, Dagmar: Selbstbestimmungen in Fan Fiction Kulturen. In: M&K, Jahrgang 66, Heft 4, S. 470 (2018)
Beitragsbild
„Urheberrecht“ by Skley. Licensed with CC BY-ND 2.0.
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2020/21, Prof. Dr.-Ing. Steinberg) entstanden. Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Kommentare werden geladen …
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.





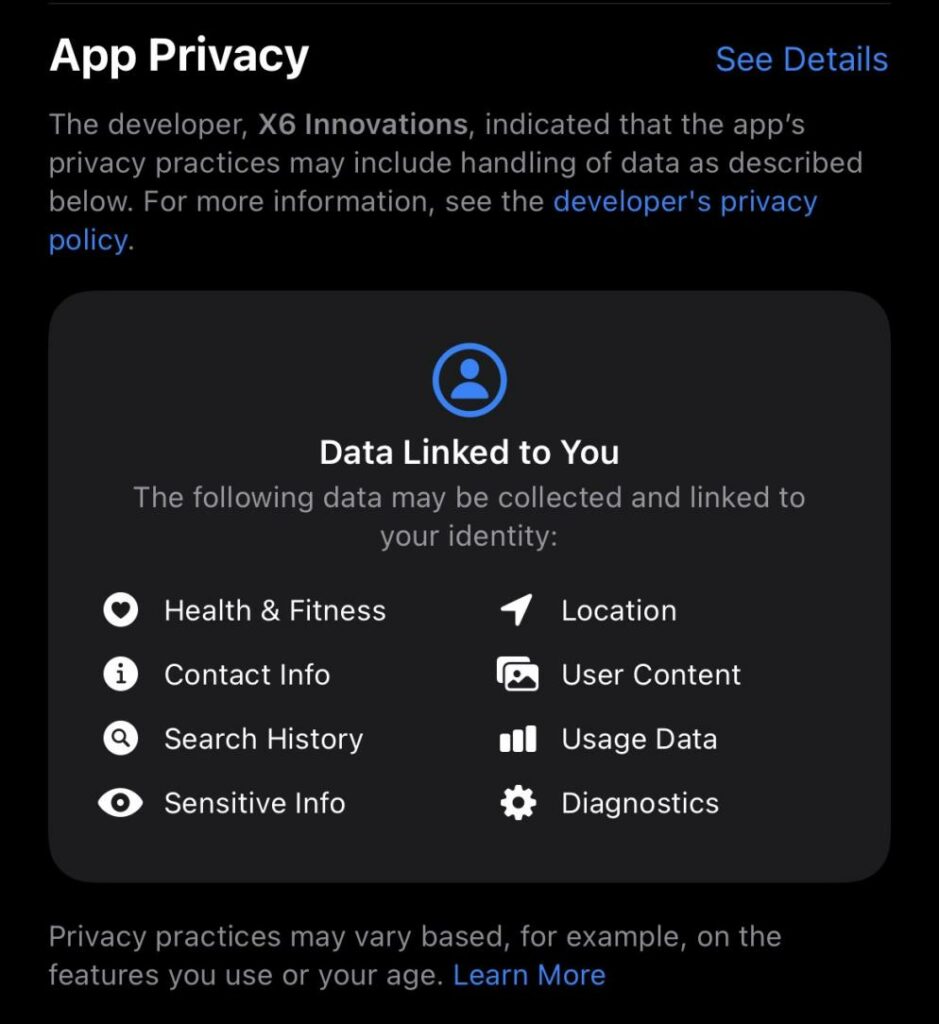














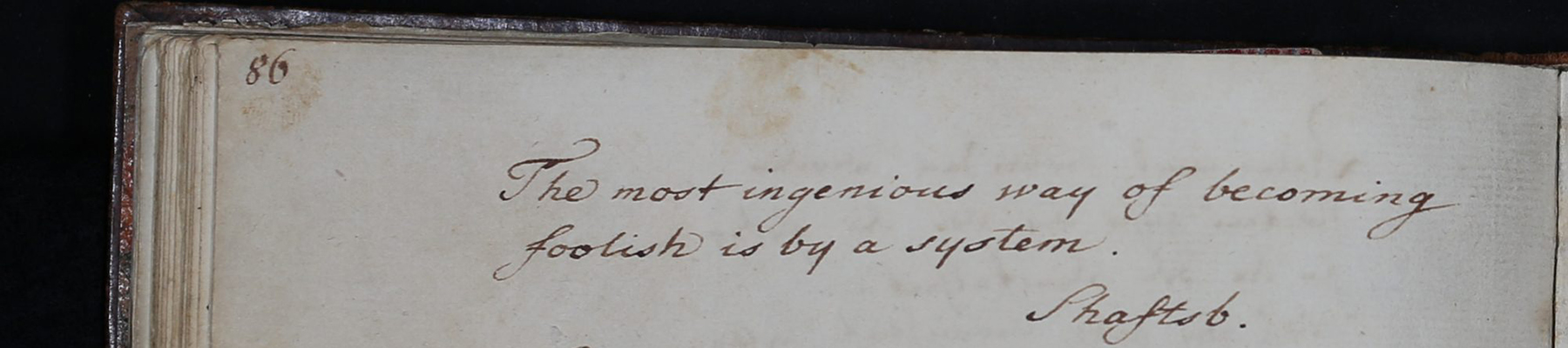









{kind=link}
{kind=link}