Autorin: Linda Görzen
Dieser Beitrag im Überblick:

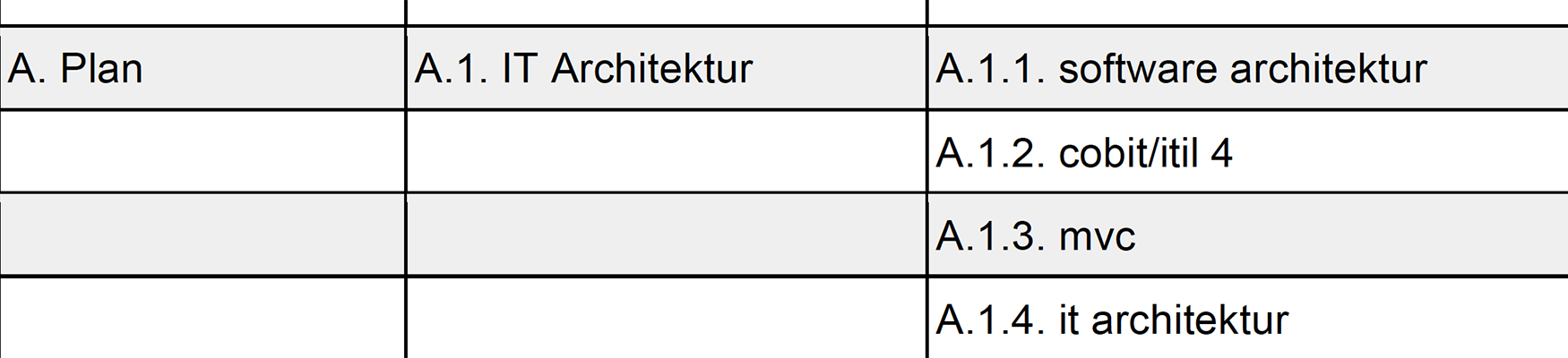
Einführung: Data Mining – Was ist das?
”Signals always point to something. In this sense, a signal is not a thing but a relationship. Data becomes useful knowledge of something that matters when it builds a bridge between a question and an answer. This connection is the signal.”
― Stephen Few, Signal: Understanding What Matters in a World of Noise[5]
Unter Data Mining versteht man einen Prozess, bei dem man mithilfe anspruchsvoller mathematischer und statistischer Algorithmen in großen Datenmengen nach Mustern, Trends und Zusammenhängen sucht.[1] Die Besonderheit des Data Mining ist die automatische Generierung der neuen Hypothesen aus den Datenmengen.[4] So kann man beispielsweise anhand der Verkaufsdaten untersuchen, ob und wann Kunden, die Produkt A gekauft haben, auch Produkt B kaufen.
Ziele der Untersuchung einer Datenmenge können unterschiedlich sein. Je nach Ziel gibt es im Data Mining dafür passende Aufgabenstellungen beziehungsweise -typen und dazugehörige Methoden. Typische Aufgabentypen sind Klassifikation, Regressionsanalyse, Assoziationsanalyse, Ausreißererkennung und Clusteranalyse. Darüber hinaus werden die Aufgabentypen des Data Mining oftmals nur in zwei Gruppen eingeteilt. Diese sind Beobachtungsprobleme (Clusteranalyse, Ausreißererkennung) und Prognoseprobleme (Klassifikation, Regressionsanalyse). [6]
Klassifikation
Die Objekte der vorhandenen Daten werden anhand ihrer Merkmale in Klassen zusammengefasst. Die dadurch gebildeten Klassenmengen dienen als Grundlage für die Entwicklung eines Klassifikationsmodells. Mit dem Klassifikationsmodell lässt sich nun die Klassenzugehörigkeit eines neuen Objekts automatisch vorhersagen.[2]
Regressionsanalyse
Die Regressionsanalyse basiert auf den Konzepten der Varianz und Kovarianz. Dies bedeutet, es wird nach Zusammenhängen beziehungsweise Abhängigkeiten zwischen Variablen gesucht. Meistens setzt man eine Regressionsanalyse bei Prognosen und Vorhersagen ein.[3]
So ist es möglich, aus den historischen Daten der Umsätze eines Kunden und seinem Wohnort eine Kennzahl zu ermitteln. Diese Kennzahl kann beispielsweise der zu erwartende Umsatz, den der Kunde in Zukunft einbringen wird, sein.[8]
Assoziationsanalyse
Bei der Assoziationsanalyse untersucht man die einzelnen Datensätze eines Datenbestandes auf Zusammenhänge, bei denen auf ein Ereignis konsequent ein anderes folgt. [8] Diese Zusammenhänge werden über Wenn-dann-Regeln beschrieben. Typischer Anwendungsbereich der Assoziationsanalyse ist die Untersuchung des Warenkorbes. Ein Beispiel dafür ist folgendes: Wenn ein Kunde Mehl kauft, dann kauft er wahrscheinlich auch die Butter. Die Assoziationsanalyse kann aber auch für die Untersuchung komplexerer Zusammenhänge benutzt werden. Etwa, in welchem Zeitabstand nach dem Kauf des Produktes A, der Kauf des Produktes B erfolgt. [1]
Ausreißererkennung
Ausreißer sind die Werte, die deutlich von den erwarteten Werten abweichen und gar nicht in die Messreihe passen. Sie können die Datenergebnisse stark verzerren und ungültig machen. Aus diesem Grund muss ein Datenbestand von den Ausreißern bereinigt werden. [3] Die Verfahren zur Analyse von Ausreißern sollen mithilfe der historischen Daten die Wahrscheinlichkeit ermitteln, mit der ein neuer Datensatz ein Ausreißer ist. Dieser soll dann entweder automatisch gelöscht oder zur manuellen Analyse gesammelt werden. [8]
Clusteranalyse
Die zentrale Aufgabe einer Clusteranalyse ist es, neue Kategorien bzw. Gruppen zu identifizieren. Denn im Gegensatz zu Klassenanalyse sind bei dieser Methode die Klassen nicht vorgegeben. Bei der Clusteranalyse werden große Datenmengen in kleinere Gruppen eingeteilt (siehe Abbildung 1). Die Mitglieder eines Clusters sollen möglichst ähnliche (homogen) Eigenschaften aufweisen. Die einzelnen Clusterkategorien sollen sich wiederum möglichst stark unterscheiden (heterogen).[7]
Da die Cluster ohne Vorwissen generiert werden, ist es nicht immer eindeutig, was die Cluster ähnlich macht und ob sie auch inhaltlich relevant sind. Für eine Aufklärung sind zusätzliche Analysen zuständig.[7]
Abbildung 1: Clusteranalyse[9] (Autor: Chire Linzenz: CC BY-SA)
Im folgenden Video sind weitere Informationen zum Thema Methoden beziehungsweise Aufgabentypen des Data Mining mit dazugehörigen Beispielen zu finden:
Fazit
Das Anwendungspotenzial des Data Mining ist vielfältig, da es in unterschiedlichen Bereichen verwendet werden kann. Aber vor allem in der Wirtschaft spielt es eine große Rolle. Mit dem Einsatz der Datenanalyse durch Data Mining können sich Händler besser auf das Kaufverhalten der Kunden anpassen und ihnen ein besseres Einkaufsserlebnis sowohl online als auch im Laden anbieten. Ferner können Banken und Versicherungen die Bonität ihrer Kunden schneller beurteilen.
Nichtsdestotrotz sollte man immer bedenken, dass die Daten nicht immer vollständig oder zum Teil fehlerhaft sein können, was zu verfälschten Resultaten führt. Somit ist die Qualität der Daten ausschlaggebend für aussagekräftige Ergebnisse.
Quellen:
1 Computerwoche (2015): Was ist bei Predictiv Analytics? Online unter: https://www.tecchannel.de/a/was-ist-was-bei-predictive-analytics,3199559,2 [Abruf am 25.01.2020]
2 Dürr, Holger (2004): Anwendungen des Data Mining in der Praxis. Online unter: [Abruf am 25.01.2020]
3 Entwickler.de (2014): Data Mining: typische Verfahren und Praxisbeispiele. Online unter: [Abruf am 25.01.2020]
4 Enzyklopädie der Wirtschaftsinformatik Online – Lexikon (2019): Data Mining. Online unter: [Abruf am 25.01.2020]
5 Goodreads (2020): Signal Quotes. Online unter: https://www.goodreads.com/work/quotes/45158439-signal-understanding-what-matters-in-a-world-of-noise [Abruf am 30.01.2020]
6 MSO Digital (2019): Data Mining. Online unter: https://www.mso-digital.de/wiki/data-mining/ [Abruf am 25.01.2020]
7 Novustat (2019): Data Mining Methoden – ein verständlicher Überblick über die wichtigsten Verfahren. Online unter: https://novustat.com/statistik-blog/data-mining-methoden-ueberblick.html [Abruf am 25.01.2020]
8 Ordix AG (o. J.): Data Mining in der Praxis (Teil I). Online unter: [Abruf am 25.01.2020]
9 Wikipedia commons (2016): EM-Gausian-data.svg. Online unter: https://commons.wikimedia.org/wiki/File:EM-Gaussian-data.svg [Abruf am 31.01.2020]
Dieser Beitrag ist im Rahmen der Lehrveranstaltung Content Management im Wintersemester 2019/20 bei Andre Kreutzmann (und Monika Steinberg) entstanden.