In einem TikTok-Video berichtet eine etwa 30-jährige Frau von einem tragischen Vorfall.
Ein 16 Jahre alter Junge namens Daniel engagierte sich ehrenamtlich in einer Flüchtlingsunterkunft. Als Daniel jedoch in Gegenwart der ukrainischen Flüchtlinge russisch sprach, wurden einige von ihnen aggressiv und schlugen den Jungen zusammen. Dieser starb an seinen Verletzungen. Die Täter wurden straffrei zurück in ihre Unterkunft geschickt.
Die Frau berichtete in Ihrem Video den Vorfall sehr detailliert und emotional. Sie brach in Tränen aus und verstand nicht, wie so etwas passieren konnte.
Was geht in Ihnen vor, wenn Sie das lesen? Verwirrung? Wut? Mitleid? Es ist ganz normal, dass man einem so aufrichtigen Statement zunächst erst einmal Glauben schenkt und nicht weiter hinterfragt.
Die Rede ist von dem Mord in Euskirchen, der nie stattgefunden hat.
WICHTIGE Info: Über das Internet wird derzeit ein Video verbreitet, in dem von einem Überfall auf einen 16-jährigen Jugendlichen im Bereich Euskirchen berichtet wird. Angeblich sei dieser von einer Gruppe Ukrainer zu Tode geprügelt worden. Die Sprache des Videos ist russisch. /1
Die Bundespolizei NRW bezieht zeitnah Stellung zum geschilderten Vorfall.
Zahlreiche Nachrichtenagenturen berichten von dieser Falschmeldung, wie z.B. die Frankfurter Allgemeine[1], t-online[2] und der ZDF[3].
Zusammenhang
Doch was hat der Gefühlsausbruch der TikTokerin mit KI-Bots zu tun?
Die Dame, die die o.g. Falschmeldung verbreitet hat, erklärte, sie habe diese Information über mehrere Ecken erfahren und hätte selbst fest geglaubt, dass es wahr sei. Sie hat also in erster Linie darauf vertraut, dass eine Meldung, die Freunde von ihr teilten, wahr sein müsste und deshalb nicht auf ihren Wahrheitsgehalt überprüft werden müsse.
Ferngesteuerte Demonstrationen
Am 21. Mai 2016 fand eine größere Demonstration gegen die Islamisierung in Texas statt. Diese wurde von der Facebook-Gruppe “Heart of Texas” organisiert. Dem entgegen organisierte die Gruppe “United Muslims of America“ einen Gegenprotest[4].
Durch diese Positionierung wurde das politische Augenmerk auf das Thema Muslime gelenkt und andere Themen verschwanden aus dem Fokus.
Aber ausgelöst und organisiert wurden die Demos pro und kontra Muslime von Menschen, bzw. Rechnern, die in Petersburg stehen. Es wurde keiner der Organisatoren vor Ort gesichtet, weil alles inszeniert war.
Es versammelten sich echte Menschen, weil für sie relevante Themen angesprochen, verschärft und anschließend durch Social-Bots kommentiert, geteilt und geliked werden. So werden sie gesehen und je mehr Interaktion stattfindet, desto offizieller kommt die Information beim Konsumenten an.
Hasskommentare sind ebenfalls ein fester Bestandteil von Social-Bots. Oft sind diese sehr polarisiert, wenig kreativ und schnell verfasst. Ihr Ziel ist es, Vertreter einer ungeteilten Meinung zum Schweigen zu bringen. Selbst vor Morddrohungen wird nicht zurückgeschreckt.
Einen Blick in die Vergangeneit
Es ist in Ordnung, anderer Meinung zu sein. Aber warum gibt sich jemand die Mühe, mehrere Menschen zu beschäftigen, damit sie ausgewählte Nachrichten teilen, oder gegen bestimmte Personen anzugehen?
Häufig wird bei den organisierten Troll-Aktionen auch von Propaganda gesprochen.[6]
So ähnlich wurde bereits der zweite Weltkrieg eingeläutet. Durch Falschmeldungen hatte man glauben lassen, dass Polen Deutschland angegriffen habe und dass der erste Angriff lediglich eine Gegenmaßnahme sei .[7] In der damaligen Zeit konnte man noch nicht so einfach wie heute durch das Internet überprüfen, wie hoch der Wahrheitsgehalt einer Nachricht sein kann. Jedoch ist es heute umso leichter eine Falschmeldung zu verbreiten und jeder Rechercheaufwand ist eben mit einem Aufwand verbunden.
Doch das Ziel solcher Aktionen wird mit einem Vergleich klar. Der Hintergrund von Fake-News ist die Lenkung von politischen Positionen.
Bot-Produktion
Nun wurden in diesem Artikel oft die “Social-Bots” genannt. Aber woher kommen diese Social Bots und wie viel Mensch und wie viel KI steckt dahinter?
Zunächst werden Bots von einem Menschen erstellt und mit verschiedenen Accounts versorgt. Ein Algorithmus mit typischen wenn-dann-Abfolgen lässt diese dann auf Sozialen Netzwerken interagieren. Bestimmte Wörter triggern diese Bots zu vorgeschrieben Ineratkionen, wie einem Kommentar, einem Like oder das Teilen bestimmter Beiträge.[8]
Nicht alle werden dafür genutzt, Meinungen zu manipulieren. Viel häufiger werden Social-Bots zu Marketing-Zwecken genutzt. Die einfachste Form ist, einen Anbieter entsprechender Bots dafür zu bezahlen, um eine erste Followerschaft zusammenzustellen. Das heißt, dass mehrere Hundert Fake-Accounts einem Unternehmen folgen und mit Beiträgen interagieren. Diese Interaktion ist zwar nicht komplex, reicht aber, um eine gewisse Nachfrage und Bekanntheit vorzugaukeln und den Algorithmus der Plattform zu triggern, wodurch die eigenen Beiträge öfter von verschiedenen Menschen gesehen werden.
Wie erkenne ich einen Bot?
Ein Erfolgsrezept existiert leider nicht.
Aber obwohl man es niemals wirklich wissen kann, gibt es ein paar Anhaltspunkte, an denen man sich orientieren kann. Wie allgemein ist die Account-Beschreibung gehalten und wie neu ist der betreffende Account? Bei prominenten Persönlichkeiten gibt es Merkmale zur Verifizierung, wie es den blauen Haken bis vor kurzem bei Twitter gab. Wenn ein Account neu ist und sehr viel Zeit nur mit dem Verfassen von Kommentaren und dem Teilen von Beiträgen verbringt, ist es ein weiteres Indiz, dass ein Social-Bot dahinterstecken könnte. Manchmal ist ein Antworttext in sekundenschnelle Geschrieben, obwohl man so aktiv ist und Lesen und Verfassen i.d.R. mehr Zeit in Anspruch nehmen müsste. Zudem scheitert ein Bot, wenn eine Unterhaltung komplexer wird, da die geschriebenen Programme nicht jede Eventualität, die ein Gespräch einschlagen kann, berücksichtigen.[9]
Wir befinden uns im digitalen Zeitalter und die Digitalisierung in Schulen ist ein Thema, das bereits seit einigen Jahren sehr präsent ist. Die Coronapandemie hat gezeigt, wie schlecht Schulen teilweise ausgestattet sind, wenn es um die Bereitstellung einer digitalen Infrastruktur geht, doch spätestens seit der DigitalPakt Schule des Bundes beschlossen wurde, kommen Schulclouds zunehmend zum Einsatz.
Digitale Technologien haben längst Einzug in den Alltag gefunden, deshalb sollte auch der Stellenwert der digitalen Bildung steigen. Es ist durchaus sinnvoll im schulischen Kontext einen bewussten und sozial verantwortbaren Umgang mit digitalen Technologien zu lehren und bereits erworbene Kenntnisse zu fördern.[1] Mit dem Einsatz von Schulclouds kann so eine Grundlage geschaffen werden, die nachhaltig, zukunftsoffen und datenschutzkonform ist und zu einer digitalen Umwandlung des deutschen Schulsystems beitragen kann.[2] Der Einsatz von Schulclouds kann dabei nicht nur als Ergänzung im Unterricht dienen, sondern auch eine große Unterstützung für organisatorische Aufgaben von Schulleitung und Lehrpersonen sein.
„In den Unterrichtsstunden entlastet mich die Schulcloud: Ich kann viel von den normalerweise anfallenden strukturellen und organisatorischen Aufgaben abgeben, weil ich das im Vorfeld schon vorbereite. Somit habe ich im Unterricht selbst freie Kapazitäten für die Lernbegleitung.“
Am Beispiel des OSZ Gastgewerbes in Berlin wird deutlich, wie vielseitig Schulclouds eingesetzt werden können, dass sowohl Schülerinnen und Schüler als auch Lehrpersonen davon profitieren.
Einsatz der schul.cloud im OSZ Gastgewerbe in Berlin
Chancen
Durch Schulclouds ist der Zugang zu Lern- und Lehrmaterialien mit entsprechender Hard- und Software jederzeit und überall möglich.[4] Schülerinnen und Schüler können gemeinsam an Lösungen arbeiten, da ihre Aufgaben zentral abrufbar sind. Lehrpersonen haben die Möglichkeit die Aufgaben individuell an das Lerntempo der Lernenden anzupassen.[5] Das selbstständige, selbstgesteuerte und kooperative Arbeiten in Clouds, ermöglicht nicht nur eine individuelle Förderung von Lernprozessen[6], sondern begünstigt auch binnendifferenzierten Unterricht und Inklusion.[7] Zusätzlich erwerben Schülerinnen und Schüler digitale Medienkompetenzen, die auch für den späteren Berufsalltag hilfreich sind, da diese immer häufiger gefordert werden.[8]
Herausforderungen
Natürlich bringen Clouds nicht nur Vorteile mit sich. Nachteilig zu nennen ist unter anderem die kostenintensive Anschaffung digitaler Geräte, welche die Lernenden zum Arbeiten benötigen. Auch eine gute Internetverbindung muss für die Nutzung durch Schülerinnen und Schüler jederzeit vorhanden sein. [9] Des Weiteren gelten mehr rechtliche Grundlagen als beim Einsatz analoger Medien. Dabei müssen nicht nur die umfangreichen Bestimmungen zum Schutz personenbezogener Daten der Datenschutzgrundverordnung (DSGVO) eingehalten werden, sondern auch die Datenschutzvereinbarungen des jeweiligen Bundeslandes.[10] Beim Einsatz von Cloud-Software muss dazu noch die Zustimmung der Lehrkräfte und Eltern eingeholt werden, damit das Recht auf informationelle Selbstbestimmung nicht verletzt wird. [11] Die Schulen sind dann angehalten, ein Angebot mit alternativer Software zur Verfügung zu stellen, sollte die Zustimmung ausbleiben. [12] Die praktische Vernetzung der Schülerinnen und Schüler, kann zu einem Rückgang des sozialen Austauschs führen, was wiederum Probleme wie soziale Ungleichheit verstärken. [13]
Verwendete Clouds in den einzelnen Bundesländern
Im System des deutschen Föderalismus liegt die Hoheitsgewalt über die Bildung in der Verantwortung der einzelnen Bundesländer. Deshalb gibt es bei der Verwendung von Clouds und Lernplattformen auch keine bundeseinheitliche Lösung. Immerhin haben drei der 16 Bundesländer sich zusammengetan. Brandenburg, Niedersachsen und Thüringen nutzen als Basis für ihre landeseigene Cloudlösung die HPI Schul-Cloud, die vom Hasso-Plattner-Institut entwickelt wurde. Seit 2021 werden diese drei Clouds von der dbildungsclouds gehostet, doch aufgrund unterschiedlicher Ansprüche wie beispielsweise dem Datenschutz, gibt es weiterhin länderspezifische Versionen der Cloud. [14] Andere Bundesländer, wie Bayern oder Nordrhein-Westfalen, verwenden ebenfalls landeseigene Lösungen oder greifen auf vorhandene Software von Moodle oder itslearning zurück. Die Entscheidung, welche Software von den Schulen letztendlich verwendet wird, liegt bei den Schulen oder den Trägern der Schulen selbst mit Ausnahme des Landes Bremen. [15]
Übersicht der genutzten Schulclouds und Lernplattformen in Deutschland[16]
Meinel, Christoph (2020): Die HPI Schul-Cloud: Eine zukunftssichere IT-Infrastruktur für das deutsche Bildungswesen. In: Ternès von Hattburg, Anabel; Schäfer, Matthias (Hg.): Digitalpakt – was nun? Ideen und Konzepte für zukunftorientiertes Lernen. Berlin: Springer VS, S. 81-87. Online unter: https://doi.org/10.1007/978-3-658-25530-5 S. 83 ➔[1] ➔[7]; S. 82 ➔[2]
Schön, Nadine (2020): Digitalkompetenz für die Bildung der Zukunft. In: Ternès von Hattburg, Anabel; Schäfer, Matthias (Hg.): Digitalpakt – was nun? Ideen und Konzepte für zukunftorientiertes Lernen. Berlin: Springer VS, S. 9-19. Online unter: https://doi.org/10.1007/978-3-658-25530-5 S.15 ➔[5]
Spratt, Annie (2020): Young teen doing schoolwork at home after UK schools close due to the Coronavirus. Online unter: https://unsplash.com/photos/V_yEK9wOuPw [Abrufdatum: 30.12.2022]
Progressive Web Apps (PWA) sind Websites, die Eigenschaften nativer Apps mit sich bringen. Richtig eingesetzt bringt die immer noch recht neue Technologie einige Vorteile mit sich wie schnelle Ladezeiten, Offline-Funktionalität und eine bei Bedarf einfache Installation. Außerdem werden PWA wie „normale“ Websites über eine URL aufgerufen. Da Inhalte so für Suchmaschinen zugänglich sind, macht sie diese Eigenschaft auch interessant für den Einsatz von Suchmaschinenoptimierung (SEO). In diesem Artikel geht es deshalb darum, wie Progressive Web Apps zu einem guten Suchmaschinenranking beitragen können.
Progressive Web App – was ist das überhaupt?
Zunächst soll die Frage geklärt werden, um was es sich bei Progressive Web Apps überhaupt genau handelt.
PWA verknüpfen die Eigenschaften von Websites mit den Merkmalen nativer Apps, sie sind quasi Website und App in einem. So wie eine native App können PWA Funktionen des Gerätes wie etwa Kamera, Mikrofon oder GPS-Ortung nutzen.1 Jedoch lassen sie sich über eine URL im Browser aufrufen, womit sie grundsätzlich unabhängig vom Betriebssystem sind und keine Installation über einen App-Store voraussetzen.2 Gleichzeitig lassen sie sich über eine Anzeige bei Bedarf auch wie eine gewöhnliche App auf Handy, Tablet oder Desktop installieren:
Installation der ZDF-Mediathek im Edge-Browser. Mobil ist der Button ebenfalls verfügbar.
Da im Hintergrund aber immer noch der Browser zum Einsatz kommt, müssen sich Benutzer nicht um Installation von Updates kümmern. Insofern unterscheiden sich PWA auch vom bereits existierenden Prinzip der Hybrid-Apps und Web-Apps: Anders als bei Hybrid-Apps ist keine Installation notwendig. Web-Apps laufen hingegen zwar ebenfalls browserbasiert, im Unterschied zu ihnen passen sich PWA aber dem Nutzungsrahmen an. Konkret bedeutet dies, dass Benutzer, deren Geräte und/oder Browser nicht mit allen Funktionen kompatibel sind, die App dennoch nutzen können.2
Technisch gesehen basieren PWA wie auch Websites auf den Sprachen HTML, CSS und JavaScript. Eine Besonderheit ist die Integration sogenannter Service Worker. Diese werden im Hintergrund des Browsers ausgeführt und bei erstmaliger Anwendung mit dem dazugehörigen Cache im Browser gespeichert. Durch das Aufrufen von Inhalten aus Cache ermöglichen die Service Worker schnelle Ladezeiten oder auch die Nutzung ganz ohne Internetverbindung.1
Weitere Informationen zu technischen Einzelheiten und der Erstellung von PWA bietet eine Playlist der Google Chrome Developers. Google fördert die Entwicklung von PWA besonders.2
Playlist Progressive Web App Training der Google Chrome Developers
Progressive Web Apps und SEO: Gibt es da einen Zusammenhang?
Da PWA eine URL besitzen, können sie wie gewöhnliche Websites durch Suchmaschinen indexiert werden. Beachtet werden muss an dieser Stelle nur, dass PWA in der Regel viel JavaScript enthalten, welches die Suchmaschinen-Crawler lange Zeit nur begrenzt richtig lesen konnten. Zwar hat sich die Situation in den letzten Jahren verbessert, will man jedoch sicher gehen, dass alle Suchmaschinen PWA richtig und schnell interpretieren, sollte man sich mit der Fragestellung beschäftigen. Eine mögliche Lösung ist der Einsatz sogenannten dynamischen Renderings, durch das Suchmaschinen Seiten als vorgerenderte HTML ausgegeben bekommen.3
Verbessert nun alleine der Einsatz von PWA das Suchmaschinenranking? Diese Frage lässt sich recht simpel mit einem nein beantworten, zumindest ergeben sich alleine durch die PWA-Eigenschaft keine bekannten oder vermuteten Benefits. Google verneint eine Bevorzugung gegenüber konventionellen Websites sogar explizit.4 Vorteile entstehen vielmehr mittelbar: PWA bieten im Optimalfall eine sehr gute User Experience, welche dann das Ranking in den Suchmaschinen positiv beeinflusst.
„Our advice for publishers continues to be to focus on delivering the best possible user experience on your websites and not to focus too much on what they think are Google’s current ranking algorithms or signals.“
Amit Singhal, Google Fellow
Gleichzeitig beharrte Google aber darauf, dass das Nutzerverhalten keinen Einfluss auf das Ranking nehmen soll. Dies dürfte aber nur die halbe Wahrheit darstellen: Schließlich trainiert Google seine Ranking-Algorithmen mit Sicherheit auch mit Nutzerdaten und nutzt dann das Trainingsergebnis als Rankingfaktor. So fließt Nutzerverhalten schließlich nicht direkt, aber doch mittelbar in das Ranking ein – nämlich indem die Algorithmen nach Merkmalen suchen, die auf ein positives Nutzererlebnis hinweisen.6
Im Jahr 2021 führte Google mit der sogenannten Page Experience schließlich offiziell einen Rankingfaktor ein, der Merkmale, die sich zur User Experience zählen lassen, erfasst. Zu den aufgezählten Signalen, die auf eine gute Page Experience hindeuten, gehören zum einem die Core Web Vitals. Dies sind Kennzahlen, die Ladezeiten, Interaktivität und visuelle Stabilität bewerten. Daneben sind aus Google-Sicht eine Optimierung der Seite für mobile Geräte, die Verwendung von HTTPS und der Verzicht auf störende Popup-Werbungen wichtig.7 Details lassen sich direkt bei den Google Developers nachlesen.
Zusammengefasst ist User Experience also wichtig für ein gutes Suchmaschinenranking, da sie für Zufriedenheit beim Nutzer sorgt und sich dies positiv auf das Ranking auswirkt. Hinweise darauf, was aus Google-Sicht weiterhin auf eine gute User Experience hindeutet, geben im Übrigen eine Reihe von „UX Playbooks“. In den Playbooks finden sich zusammengefasst folgende konkrete Kennzahlen:6
Time on Site (Verweildauer): Bleiben Benutzer länger auf der Seite, spricht dies dafür, dass die Erwartungen erfüllt wurden
Page Views (Seitenaufrufe): Je mehr Seitenaufrufe Benutzer auf einer Seite machen, desto höher scheint das Interesse zu sein
Bounce Rate (Absprungrate): Verlassen Benutzer eine Seite gleich wieder nach Aufruf, ist er vermutlich nicht fündig geworden
Mit Progressive Web Apps eine gute User Experience gewährleisten
Viele Eigenschaften von PWA lassen sich mit den eben genannten Merkmalen, die auf gute User Experience hindeuten, in Verbindung bringen. Beispiele finden sich viele: PWA sorgen für schnelle Ladezeiten, verfolgen für gewöhnlich den Mobile-First-Gedanken und können Benutzer durch Interaktion zu längerer Verweildauer motivieren, etwa durch Push-Benachrichtigungen wie bei gewöhnlichen Apps. Allgemein sorgt das Aussehen und die Handhabung einer nativen App für eine schnelle und flüssige Interaktion mit der Website; durch die Offline-Verfügbarkeit können Nutzer auch ohne oder mit nur schwacher Verbindung auf Websites zugreifen. Weiterhin nutzen sie das HTTPS-Protokoll.8
Aufgepasst werden sollte bei PWA allerdings, wenn sie zusätzlich zu einer klassischen Variante der Website angeboten werden. Wird auf beiden Seiten derselbe Inhalt verwendet, könnten Suchmaschinen dies als Duplicate Content werten und dann eine oder beide Seiten abwerten. Vermieden werden kann dies jedoch durch ein rel=canonical im Header der URL.9
Fazit
Alleine durch den Einsatz von Progressive Web Apps ergeben sich noch keine Vorteile im Suchmaschinenranking. Sie können aber richtig eingesetzt für eine sehr gute User Experience sorgen und sich so auch im Suchmaschinenranking gegenüber anderen Websites absetzen. Dafür müssen die Stärken von PWA ausgespielt werden, ohne aber gleichzeitig die sonst auch üblichen Faktoren der Suchmaschinenoptimierung zu missachten.
Im Zeitalter der Selbstoptimierung gibt es unzählige Apps, die das Leben einfacher machen. Gesundheits-Apps werden genutzt, um zum Beispiel Kalorien zu zählen oder Sportübungen zu tracken, aber auch um mithilfe von Zyklus-Apps den Menstruationszyklus zu dokumentieren. Nutzende berichten, dass solche FemTech-Apps ein wertvolles Mittel sind, um mehr über sich und die eigene Gesundheit zu erfahren und den eigenen Körper besser kennenzulernen.[1][2]
Der Begriff FemTech wurde 2016 von Ida Tin geprägt und in den letzten Jahren ist die Bandbreite an sogenannten FemTech-Apps, also nutzerzentrierten und technologischen Lösungen, die sich an feminine Bedürfnisse richten, stark gewachsen.[3]
Sie versprechen Autonomie und werden als empowerndes Tool vermarktet.[4] FemTech-Apps werden folglich genutzt, um die Menstruation und die eigene Fruchtbarkeit zu überwachen. So helfen sie dabei, unabhängig und selbstbestimmt agieren zu können, denn die App nimmt die lästige und zeitaufwendige Arbeit des Zählens und Dokumentierens ab. Dadurch fällt es vielen Menschen leichter, dies längerfristig und regelmäßig zu tun.[5]
Noch angenehmer fühlt es sich an, wenn man nichts dafür bezahlen muss. Aber das stimmt nur bedingt, denn auch bei kostenlosen Apps wird in Daten bezahlt und der Preis kann erschreckend hoch sein.[6] Personenbezogene Daten sind wertvoll und die Daten einer schwangeren Frau zum Beispiel noch mehr. Nutzt sie eine FemTech-App, werden diese Daten nicht zwingend ihr privates Eigentum bleiben.[7] Aber warum ist das eigentlich ein Problem?
Profite durch sensible Daten
Wenn wir betrachten, was FemTech-Apps machen, dann wird schnell klar, dass die gesammelten Daten intimer und persönlicher kaum sein können. Es entstehen große Mengen an Datensätzen, in denen neben Geburtsdaten auch Daten wie z.B. Gefühle und Stimmung, Ausfluss und andere körperliche Begleiterscheinungen oder sogar sexuelle Aktivitäten festgehalten werden.[8]
Screenshot aus der App ‚Flo‘
Folglich sollte es also eigentlich selbstverständlich sein, dass solche Daten nur durch die nutzende Person weitergegeben werden dürfen. Tatsächlich sind sich die meisten aber häufig nicht über die Tragweite der Datenweitergabe bewusst.[9] Denn anders als bei Krankenakten, die bei den Ärzten und Krankenhäusern der Schweigepflicht unterliegen, gibt es keine Klarheit, wie datenschutzrechtlich mit den sensiblen Daten umgegangen werden soll.
Das bedeutet, dass es FemTech-App-Anbietern freisteht, welche Daten sie wie sammeln[10] oder welche Informationen sie an Werbepartner weitergeben, um personalisierte Werbung für bspw. Windeln zu schalten oder neue Nutzende zu rekrutieren.[11]
Aber es gibt doch Datenschutzbestimmungen!
Natürlich könnte man meinen, dass jede Person, die eine FemTech-App nutzt und durch die Nutzung den Datenschutzbestimmungen dieser spezifischen App explizit oder implizit zustimmt, auch weiß, worauf sie sich einlässt. So einfach ist es allerdings nicht. Das liegt an verschiedenen Gründen.
Zum einen sind Datenschutzerklärungen sprachlich so gestaltet, dass sie schwer zu verstehen sind und ein gewisses sprachliches Niveau Voraussetzung ist, um ihren Inhalt zu durchschauen. Zum anderen sind sie auch nicht immer offensichtlich und es gibt auch keine Möglichkeit, den Datenschutzerklärungen zu widersprechen.[12] Die Mozilla Foundation hat festgestellt, dass in der Mehrheit der FemTech-Apps Datenschutz nicht gewährleistet werden kann.[13]
Das heißt, auch wenn die Datenschutzbestimmungen gesehen, gelesen und verstanden wurden, heißt es noch nicht, dass sie positiv für die Nutzenden sind oder es bleiben.
Datenschutzbestimmungen sind angepasst worden im Verlauf der Lebensdauer der Apps, da es immer wieder kontrovers diskutiert worden ist, ob die sensiblen Daten sicher sind.
Erst 2021 gab es Empörung, als bekannt wurde, dass die meist genutzte Menstruations-App Flo Daten an Dritte weitergab.[14] Als Reaktion darauf hat Flo die Daten anonymisiert.
Und nun: Apps löschen oder behalten?
Es stellt sich letztendlich die Frage, wie unter diesen Gesichtspunkten mit FemTech-Apps verantwortungsvoll und doch persönlich bereichernd umgegangen werden kann. Gerade im Verlauf des Umwurfs von Roe vs Wade in den USA haben sich viele Nutzende dazu entschieden, die Apps zu löschen, da im schlimmsten Fall die Daten an Strafverfolgungsbehörden weitergegeben werden können.[15] Wenn nicht klar ist, was mit den Daten passiert, wird sich zu der Lösung entschieden, erst gar keine Daten zu generieren.
Welche Folgen der Eingriff in die Privatsphäre im Zusammenhang mit dem Fall Roe vs. Wade haben könnte, wurde in diesem Video gut zusammengefasst:
Auch wenn FemTech-Apps keinen optimalen Datenschutz bieten, so ergeben sich dennoch Vorteile, die viele Personen nicht aufgeben möchten, denn der Nutzen ist für sie unumstritten.[16] FemTech blind gegenüber den Problematiken zu nutzen ist allerdings auch keine gute Idee. Apps müssen die Privatsphäre der Nutzenden wahren.
Ausblick
Anstatt auf absolute Lösungen zu setzen, sollte die Informationskompetenz der Nutzenden gefördert und für die Datenflüsse sensibilisiert werden. Die Risiken und der Nutzen müssen gegeneinander aufgewogen und eine persönliche Entscheidung getroffen werden,[17] die fundiert und informiert getroffen werden kann. Da diese Apps auch ein Bestandteil von reproduktiver und sexueller Selbstbestimmung und Freiheit sein können, brauchen wir Wege, die weiter gehen, als eine „ganz oder gar nicht“ Entscheidung.
Es werden Apps mit freier und offener Software benötigt und es braucht Transparenz, welche Daten verarbeitet und gesammelt werden. Das Verantwortungsbewusstsein für die Sensibilität der Daten sollte nicht nur bei den Nutzenden liegen, sondern auch bei denen, die diese Apps erstellen und anbieten.
Quellen
Amelang, Katrin (2022): (Not) Safe to Use: Insecurities in Everyday Data Practices with Period-Tracking Apps. In: New Perspectives in Critical Data Studies. Palgrave Macmillan, Cham, S. 297-321. Online unter https://doi.org/10.1007/978-3-030-96180-0_13 S. 307 ➔[2]➔[16]
Bretschneider, Richard A. (2015): A Goal- and Context-Driven Approach in Mobile Period Tracking Applications. In: Springer, Cham, S. 279287. Online unter https://doi.org/10.1007/978-3-319-20684-4_27 S. 283-284 ➔[8]
Epstein, Daniel A.; Lee, Nicole B.; Kang, Jennifer H.; Agapie, Elena; Schroeder, Jessica; Pina, Laura R.; Fogarty, James; Kientz, Julie A.; Munson, Sean (2017): Examining menstrual tracking to inform the design of personal informatics tools. In 2017/05/02. ACM. Online unter https://doi.org/10.1145/3025453.3025635 S. 6. ➔[1]
Fowler, Leah R.; Gillard, Charlotte; Morain, Stephanie R. (2020): Readability and accessibility of terms of service and privacy policies for menstruation-tracking smartphone Applications. In: Health promotion practice, Jg. 21, H. 5, S. 679-683. Online unter https://doi.org/10.1177/1524839919899924 S. 681 ➔[12] ; S. 682 ➔[9]
Gilman, Michele Estrin (2021): Periods for profit and the rise of menstrual surveillance. In: Columbia Journal of Gender and Law, Jg. 41, H. 1, S. 100-113. Online unter https://doi.org/10.52214/cjgl.v41i1.8824 S. 100 ➔[4] ; S. 103 ➔[6]
Healy, Rachael L. (2020): Zuckerberg, get out of my uterus! An examination of fertility apps, data-sharing and remaking the female body as a digitalized reproductive subject. In: Journal of Gender Studies, Jg. 30, H. 4, S. 406-416. Online unter https://doi.org/10.1080/09589236.2020.1845628 S. 411 ➔[11]
Siapka, Anastasia; Biasin, Elisabetta (2021): Bleeding data: the case of fertility and menstruation tracking apps. In: Internet Policy Review, Jg. 10, H. 4. Online unter https://doi.org/10.14763/2021.4.1599 S. 2 ➔[5]
Pflegeroboter sollen zukünftig vermehrt in Altenheimen eingesetzt werden. Vielleicht denken Sie auch darüber nach? Erwarten Sie nicht nur Freudenschreie seitens der Senioren[1]. Wahrscheinlich werden Ihnen mindestens so viel Skepsis und Ängste wie Neugierde entgegenschlagen. Die gute Nachricht ist: Sie können ganz viel dafür tun, die Hemmschwelle für Ihre Bewohner zu senken und somit die Akzeptanz von Pflegerobotern bei Senioren erhöhen.
Schauen Sie zunächst auf Ihre eigene Einstellung zum Pflegeroboter. Hoffen Sie insgeheim, im Gerät einen Ersatz für eine menschliche Pflegekraft zu finden? Das sollten Sie ändern. Erstens ist Ihre Hoffnung aus technischer Sicht unhaltbar, denn ein Roboter „spürt“ nichts und folgt strikt seiner Programmierung. Daher ist er geeignet für wiederkehrende, langweilige Aufgaben.
Der Care-O-bot 4 ist ein Beispiel eines Pflegeroboters des Fraunhofer-Instituts. Das Video wird in doppelter Geschwindigkeit abgespielt.
Er transportiert (sehr langsam – siehe Video!) Dinge von A nach B und kann unterhaltend sein. Jedoch wissen Sie aus eigener Erfahrung, was gute Pflege ausmacht: den Menschen in seiner Ganzheit zu sehen und mit allen Sinnen wahrzunehmen[2]. Das können Menschen. Maschinen scheitern bereits an der intuitiven Aufgabe den schmalen Grat zwischen einspringender und vorausspringender Fürsorge zu erkennen[3] .
Heben Sie zweitens das Gerät sprichwörtlich in den Himmel, können bei den Zupflegenden die unerwünschten Worte „Qualitätsminderung“ und „Kostensenkung“ ankommen[4]. Erzählen Sie vielmehr, dass der Roboter dem Personal freie Zeit schafft, die wiederum den Senioren zu Gute kommt. Und noch wichtiger: Handeln Sie auch so.
Ein weiterer Grundsatz ist, dass Sie aus ethischer Sicht niemanden zum Umgang mit einem Pflegeroboter zwingen dürfen[5]. Auch können Ihre Bewohner eine Patientenverfügung mit dem Themenbereich „Robotik“ haben, wie sie Oliver Bendel vorschlägt[6]. Beachten Sie daher, dass sich die Akzeptanz von Pflegerobotern bei Senioren mit einem freiwilligen Kontakt erhöht.
Gewohnheit & Vertrauen der Senioren
Bei der heutigen Altersheimgeneration handelt es sich um einen Personenkreis, der nicht wie selbstverständlich einen Staubsaugerroboter und ein Sprachassistenzsystem (z.B. Alexa / Siri) sein eigen genannt hat. Entsprechend unsicher ist unter Umständen der Umgang mit diesen Geräten.
Laut einer Studie neigen technikferne Menschen dazu, mit Robotern zu reden wie mit Menschen. Sie nutzen lange verschachtelte Sätze und möglicherweise den lokalen Dialekt[7]. Mit dem Ergebnis, dass der Roboter den Wunsch nicht befolgt. Das kann Ihre Bewohner enttäuschen oder sie resignieren ganz. Andersherum verstehen Senioren die Sprachausgabe des Pflegeassistenten nicht, wenn die Lautstärke zu leise ist oder aber die Bedeutung seiner Worte unklar bleiben[8]. Auch andere körperliche Beeinträchtigungen können die Bedienung verhindern. Achten Sie daher auf die passende Einstellung und üben Sie mit den Senioren den Umgang mit dem Gerät. So stehen die Chancen gut, dass sich bald ein gewisses Vertrauen einstellt[9].
Persönlichkeit des Pflegeroboters
Alle Übungen im Umgang sind jedoch zwecklos, wenn das Verhalten und die „Persönlichkeit“ des Pflegeroboters unpassend zum Einsatzgebiet ist[10]. Ein aggressiv-wirkendes Assistenzsystem wird kaum Sympathien erwecken können. Denn obwohl das Handeln des Roboters auf seine Programmierung zurückzuführen ist, werden die Senioren der Maschine menschliche Attribute wie Fleiß, Neugierde, Abenteuerlust oder eben Aggressivität ect. zuschreiben. Sie werden dem Roboter eine Persönlichkeit zuschreiben wie bei einem Menschen. Wissenschaftler nennen diese Gleichbehandlung von künstlichen und natürlichen Gegenüber „Media Equation“[11]. Dabei muss der technische Interaktionspartner nicht einmal eine menschenähnliche Gestalt haben. Auch „fleißige“ Staubsaugerroboter, genießen den Status einer Persönlichkeit, leben als Familienmitglied und haben einen Namen. Ebenso schimpfen wir mit dem „dummen“ Drucker. Vielleicht möchten Sie zusammen mit den Bewohnern einen Namen für den Pflegeroboter aussuchen?
Eine weitere wichtige Erkenntnis ist das „Uncanny Valley“ . Dabei handelt es sich um ein Phänomen, das erstmals von Masahiro Mori beschrieben wurde. Werden Roboter zu menschenähnlich gruseln sie uns. Wir erkennen, dass etwas im Gegenüber fehlerhaft ist und lehnen es ab[12]. Sind sie hingegen mit großen Kulleraugen auf „niedlich“ und mit ihren Körpern auf „ungefährlich“ getrimmt, dulden Menschen sie eher in ihrer Nähe. Das Design macht also für die Akzeptanz von Pflegerobotern bei Senioren einen großen Unterschied.
„Ein zentraler Punkt ist die Frage des Gefühls beim Menschen – ob er das Gegenüber als Roboter wahrnimmt und sich in seinen Bedürfnissen wahrgenommen fühlt. Verniedlichung ist zum Beispiel ein Weg dorthin zu kommen.“[13]
(Professor Dr. Jan Ehlers, 2020)
Schauen Sie sich an, welche weiteren Faktoren einen Roboter sympathisch oder unsympathisch werden lassen:
Nutzen für Senioren
Für die Akzeptanz von Pflegerobotern bei Senioren spielt die empfundene Nützlichkeit eine Rolle[18]. Das wäre beispielsweise bei intimen Situationen der Fall, bei denen auf die Anwesenheit eines Menschen verzichtet werden könnte (z.B. Waschen, Toilettengang, etc.)[19] [20]. Der Pflegeroboter ist in der Lage in diesen Situationen zeitunabhängiger, vertrauensvoller und gelassener zu wirken als eine menschliche Pflegekraft. Beachten Sie dabei die Individualität Ihrer Schützlinge. So hat eine Umfrage ergeben, dass Patienten im Krankenhaus Pflegeroboter bei bestimmten Aufgaben annehmen (z.B. Getränke servieren), jedoch bei ähnlichen Tätigkeiten (z.B. Medikamente bringen) ablehnen[21].
Die Ablehnung eines Pflegeroboters kann ebenso von der persönlichen Einstellung herkommen: „So ein Hilfsmittel brauche ich nicht, so alt bin ich noch nicht“[22]. Der Roboter steht in diesem Fall symbolisch als Zeichen für eine Schwäche, ähnlich wie ein Rollator. Im Gegensatz zum Rollator kann er jedoch körperlich unabhängigen Menschen durch seine Unterhaltungsfunktionen dienen oder durch das Sportprogramm Verletzungen vorbeugen. Allerdings ist das Erlernen der neuen Technologie für ältere Menschen anstrengend, nicht zuletzt weil kognitive Fähigkeiten nachlassen[23]. Ihre Senioren werden genau abwägen, ob sich der Aufwand lohnt. Verdeutlichen Sie daher bei der Einführung jedem Ihrer Schützlinge worin für ihn der Vorteil in der Roboternutzung besteht.
Fazit
Insgesamt tragen viele verschiedene Ansätze dazu bei die Akzeptanz von Pflegerobotern bei Senioren in Ihrem Altenheim maßgeblich zu steigern. Dafür müssen die Funktionen und die Einsatzmöglichkeit für die nutzenden Personen ersichtlich sein. Kostensenkung und Personalersatz sollten für Sie nicht im Vordergrund stehen, sondern die Entlastung des Personals. Freigewordene Zeit lassen Sie am besten den Heimbewohnern zu Gute kommen. Verbale und nonverbale Körpermerkmale des Pflegeroboters sind entscheidend für die Sympathie und sollten bei der Wahl, sowie bei der Programmeinstellung beachtet werden. Grundsätzlich sollten Sie niemanden zum Umgang mit dem Pflegeroboter zwingen. Viel Erfolg.
Literaturverzeichnis 1vgl. SRG SSR (2018): Halten Sie den Einsatz von Betreuungs-Robotern in Altersheimen und Spitälern für gut?. In: Statista Online unter: Schweiz – Einsatz von Betreuungs-Robotern in Altersheimen und Spitälern 2018 | Statista [Letzter Abruf am 30.11.2022] 2vgl. Maio, Giovanni (2018): Mittelpunkt, Mensch, Lehrbuch der Ethik in der Medizin. Mit einer Einführung in die Ethik der Pflege. 2., überarbeitete und erweiterte Auflage. Stuttgart: Schattauer, S. 280 u. 282 3vgl. Schiff, Andrea; Dallmann, Hans-Ulich: Ethische Prinzipien in der Pflege. In: Ethik in der Pflege. München : Ernst Reinhardt Verlag (Pflege studieren),S. 48-49 4vgl. Afflerbach, Thomas (2021): Serviceroboter : Digitalisierung von Dienstleistungen aus Kunden-, Mitarbeiter-, und Managementperspektiven. Wiesbaden: Springer Gabler. (essentials), S. 32 5vgl. Misselhorn Catrin (2019): Grundfragen der Maschinenethik. 4., aktualisierte Auflage. Stuttgart: Reclam (Reclams-Universalbibliothek, Bd. 19583), S. 155 6vgl. Bendel, Oliver (2017): Ergänzende Patientenverfügung zum Einsatz von Robotern. Online unter: https://www.informationsethik.net/wp-content/uploads/2017/03/PV_Robots_V_1_0.pdf [Letzter Abruf am 22.12.2022] 7vgl. Früh, Michael; Gassner, Alina (2018): Erfahrungen aus dem Einsatz von Pflegerobotern im Alter. In: Bendel, Oliver (Hg.): Pflegeroboter. Wiesbaden: Springer Gabler, S. 54 8vgl. ebenda, S. 55 9vgl. Bleuler Tanja; Caroni, Pietro (2021): Roboter in der Pflege . Welche Aufgaben können Roboter heute schon übernehmen? In: Serviceroboter. Wiesbaden: Springer Gabler, S. 449 10vgl. Remmers, Peter (2021): Humanoide, animaloide und dingliche Roboter. Begriffliche, ethische und philosophische Aspekte. Bendel, Oliver (Hg.): Pflegeroboter. Wiesbaden: Springer Gabler, S. 220 11vgl. Watson, Richard (2014): Uncanny Valley — Das Phänomen des „unheimlichen Tals“. In: 50 Schlüsselideen der Zukunft. Springer Spektrum, Berlin, Heidelberg. Online unter https://doi.org/10.1007/978-3-642-40744-4_35 [Letzter Abruf am 28.11.2022] 12vgl. Mori, Masahiro; MacDorman, Karl F.; Kageki, Norri (2012): The uncanny valley [from the field]. In: IEEE Robotics & Automation Magazine. Jg.19, H.2. Onliner unter: https://ieeexplore.ieee.org/document/6213238/authors#authors. DOI: 10.1109/MRA.2012.2192811 [Letzter Abruf am 31.11.2021], S. 100 13Sieger, Heiner (2020): Soziale Roboter: „Der fühlt ja nichts!. Zuletzt aktualisiert am 21.12.2020. Online unter: https://digitales-gesundheitswesen.de/soziale-roboter/ 14 vgl. Paetzel-Prüsmann, Maike (2021): Komm schon, gib dir doch etwas mehr Mühe. Wie wir die Persönlichkeit von Robotern wahrnehmen und verändern können. Bendel, Oliver (Hg.): Pflegeroboter. Wiesbaden: Springer Gabler, S. 368 15vgl. ebenda, S.373 16vgl. ebenda, S. 370 17vgl. Bleuler Tanja; Caroni, Pietro (2021): Roboter in der Pflege . Welche Aufgaben können Roboter heute schon übernehmen? In: Serviceroboter. Wiesbaden: Springer Gabler, S. 454 18vgl. Chatzopoulos, Annika et al (2018): Roboter Akzeptanz in der Pflege : Untersuchung der Akzeptanz bei der Pflege durch Roboter mit dem Fokus auf körperliche Interkation. In: Valdez, André Calero (Hg.): Akzeptanz autonomer Robotik : Einsatz in Industrie, Büro und Pflege. 1. Auflage. Aachen : Apprimus Verlag (studentische Reihe; Stu 1), S. 26 19vgl. Deutscher Ethikrat (Hg.) (2020): Robotik für gute Pflege. Stellungnahme. Berlin: Deutscher Ethikrat. https://www.ethikrat.org/fileadmin/Publikationen/Stellungnahmen/deutsch/stellungnahme-robotik-fuer-gute-pflege.pdf [Letzter Abruf am 22.3.2022] [E-Book], S. 39-40 20vgl. Gisinger, Christoph (2018): Pflegeroboter aus Sicht der Geriatrie. Bendel, Oliver (Hg.): Pflegeroboter. Wiesbaden: Springer Gabler, S. 113-114 21vgl. Honekamp, Ivonne et al (2019): Akzeptanz von Pflegerobotern im Krankenhaus : eine quantitative Studie. In: Ta TU-uP: Zeitschrift für Technikfolgenabschätzung in Theorie und Praxis. Jg.28, H.2. Online unter: https://www.tatup.de/index.php/tatup/issue/view/9/10 [Letzter Abruf am 28.11.2022], S. 62 22vgl. Früh, Michael; Gassner, Alina (2018): Erfahrungen aus dem Einsatz von Pflegerobotern im Alter. In: Bendel, Oliver (Hg.): Pflegeroboter. Wiesbaden: Springer Gabler, S. 53 23vgl. Seifert, Alexander; Ackermann, Tobias (2020): Digitalisierung und Technikeinsatz in Institutionen für Menschen im Alter. Studie im Auftrag von CURAVIVA Schweiz. Zürich: Zentrum für Gerontologie. Online unter: https://www.zora.uzh.ch/id/eprint/185291/1/Sonderauswertung_Alter_20200131_5.pdf [Letzter Abruf 7.12.2022]
Wir alle kennen es, man spricht mit einem Freund oder Partner über irgendein Produkt o.ä. ohne dabei überhaupt das Handy entsperrt zu haben und dann möchte man etwas googeln und die Werbung handelt von dem eben besprochenen Thema. Ich meine klar, hat so seine Vorteile da weiter machen zu können, wo die Unterhaltung aufgehört hat. Aber ist das nicht eigentlich ein bisschen unheimlich, dass dir dein Smartphone immer zuhört und alles mitbekommt, was man in dessen Umgebung sagt? Passieren tut das durch Big Data.
Was ist denn eigentlich Big Data?
Der Begriff Big Data beschreibt eine große Masse an personenbezogenen Daten, die Unternehmen wegen ihrer Schnelllebigkeit und Komplexität zu Analysezwecken nutzen. Unter den Begriff fallen unter anderem Daten in Form von Zahlen, Texten, Standortverläufen, Videos, Zahlungsunterlagen, Bilder oder auch das gesprochene Wort.
3V-Modell
Der Branchenanalytiker Douglas Laney beschrieb Big Data mit dem 3V-Modell. Das erste V steht für Velocity, also die Geschwindigkeit, mit der neuen Daten ankommen und man diese verarbeiten muss. Dann gibt es noch das Volume, also die gesamte Masse an Daten aus den unterschiedlichsten Quellen. Als drittes V gibt es Variety, welches die Vielfalt der Formen der gesammelten Daten beschreibt. Aber im Laufe der Zeit kamen weitere Vs dazu. So auch das V für Variability, also der Schwankung des Datenflusses und Form der Daten. Des Weiteren gibt es noch Veracity, was die Richtigkeit der Daten beschreibt und diese einordnet und sortiert. Je nachdem wo man schaut, gibt es noch die Kategorie Value. Diese beschreibt den Geschäftswert der Daten.
Speicherung
Anfang der 2000er fand der Begriff Big Data das erste Mal Einzug in die Köpfe der Menschen. Da fing nämlich die Speicherung und Interpretation von Daten aus dem Internet an. Damals ging es noch eher um das Klickverhalten auf der eigenen Webseite oder die IP-Adresse des Kunden. Von damals zu heute hat sich aber einiges getan, die Form der Daten hat sich geändert und natürlich auch die Datenmenge. Allein im Jahr 2012 wurden weltweit 6,5 Zettabyte an Daten gesammelt. Was ist ein Zettabyte, fragt ihr euch jetzt? Ein Zettabyte steht für EINE MILLIARDE TERRABYTE. Im Jahr 2020 waren es dann auch schon 64,2 Zettabyte. Das bedeutet, dass jeder Mensch, der irgendwie mit dem Internet verbunden ist, durchschnittlich tagtäglich ca. 150 Gigabyte an persönlichen Daten übermittelt. Um sich das mal auf der Zunge zergehen zu lassen, der Film Titanic aus dem Jahr 1997, der wohlgemerkt über drei Stunden läuft, verbraucht in HD einen Speicherplatz von 8,5 Gigabyte.
Screenshot der Statista-Statistik zu Speicherplatz von Big Data
Zweck
Diese unfassbar riesige Menge an Daten wird für Unternehmen interessant, da diese dadurch Zeit in der Entwicklung neuer Produkte und Dienstleistungen einsparen. So analysiert man Trends um zu prüfen, wo es noch Marktlücken gibt. Ein offensichtlicher Vorteil der Big Data Analyse ist auch die personalisierte Werbung. Der Algorithmus weiß, wie man einen am besten anspricht und wofür man sich interessiert, vielleicht sogar besser als man selbst. Des Weiteren können klügere geschäftliche Entscheidungen getroffen werden, da man durch die Echtzeitanalyse, Veränderungen und Unsicherheiten bewerten und dementsprechend handeln kann. Zudem kann die Produktion effizienter gestaltet werden, da der Kunde einem sagt, was man braucht, wenn auch unfreiwillig. Das Gesprochene und geschriebene Wort, so wie Chats oder Sprachnachrichten, wird zum Füttern von Deep Learning KIs genutzt, um die maschinelle Art des Schreibens und Sprechens zu optimieren und menschlicher/natürlicher machen zu können.
Weitere Orte an denen Daten über einen gesammelt werden sind Autos die mit dem Handy und mit dem Internet verbunden sind. Außerdem auch Bankdaten, Smart-Home Gadgets und ihre Assistenten wie bpsw. Alexa oder halt klassische Überwachungsmaßnahmen.
Aufschrei Big Data
Facebook Skandal
Erinnert ihr euch noch ans Jahr 2018? Bevor die Pandemie über uns hereinbrach, brach etwas anderes zusammen. Die Reputation von Facebook. Damals kam nämlich raus, dass Facebook (Meta) Daten von mindestens 87 Millionen Nutzern durch Camebridge Analytica (C.A.) auswerten ließ, um so illegal Werbung für den Trump-Wahlkampf zu machen. Die Muttergesellschaft von C.A., die SCL-Group hat es sich zum Geschäftsmodell gemacht, politische Wahlen und Stimmungen durch Big Data Auswertung zu beeinflussen.
Auswertung
Big Data ist aber nicht nur für Meta ein Geschäftsmodell. Google und TikTok machen nichts anders. Es wird alles gespeichert, von der Sucheingabe (was suchst du, wie suchst du es, was schreibst du, welche Wörter nutzt du) bis zurzeit, die du brauchst um dich für ein Ergebnis zu entscheiden. Was klickst du auf der Seite an? Wie lange bist du auf der Seite unterwegs? Wo geht es nach dem Besuch der Webseite hin? Wie schnellt scrollst du weiter? Welche Webseiten besuchen deine Freunde und Familie? All das wissen die Unternehmen wie C.A. schon bevor du selbst irgendwas gemacht hast. Jeder Schritt wird verfolgt, jede neue Suche, jede Meinungsänderung wird wahrgenommen. Man wird komplett durchleuchtet.
Social-Credit-Score
Kleiner Funfact am Rande, wusstest du, dass Big Data der Grundbaustein für den Social-Credit-Score in China ist? So wird genau erkannt, wo du wie viel reininvestiert, was du mit deinem Alipay Account bezahlt und ob du dein Leihfahrrad auch wieder am richtigen Ort abgestellt hast. Das in Verbindung mit ausgereifter Gesichtserkennungssoftware an öffentlichen Plätzen und du bist durchsichtig. Dadurch, dass heutzutage alles miteinander verbunden ist und alles einfacher werden soll, wird auch vieles noch komplizierter. So auch das Profil was Meta über Nicht-Nutzer anlegen kann, welches auf Daten basiert, die von Bekannten irgendwie irgendwo gespeichert worden sind und die Organisation Zugriff drauf hat.
kurzer Einblick in das System Social-Credit-Score
Wert
Es gibt noch ewig viele Beispiele, was mit Big Data überall auf der Welt gemacht wird und wie man mehr und mehr die Entscheidungsgewalt über sich selbst abgibt. Aber eine Frage ist noch interessant, auf die ich noch nicht eingegangen bin. Wie viel sind diese Daten eigentlich Wert? Auch wenn man Big Data als das Erdöl der digitalen Wirtschaft bezeichnet, kann ich hier leider keine sichere Zahl nennen. Aber ich möchte nur so viel sagen, dass die E-Scooter, die man überall in der Stadt sieht, mit einer durchschnittlichen Lebensdauer von wenigen Monaten, so viele Daten über uns sammeln, dass die Unternehmen locker an die Börse gehen können. Und das nur durch den Verkauf der gesammelten Daten.
Emissionen
Ach so, ganz vergessen. Diese Zettabyte an Daten, die anfallen, müssen irgendwo gespeichert werden. Und wo macht man das? Genau. In riesigen Rechenzentren, die weltweit im Jahr 2020 zwischen 100 und 500 Millionen Tonnen CO2 ausgestoßen haben. Und das Problem hierbei ist, dass es nur noch mehr wird. Es werden mehr Menschen -> mehr Menschen, die einen Internetzugang haben -> mehr Daten -> mehr Server -> mehr Rechenzentren -> mehr CO2. Aus einer ARTE Dokumentation habe ich entnommen, dass im Jahr 2025 geschätzt wird, dass 25 % des gesamten Energieverbrauches nur auf Rechenzentren zurückzuführen sind.
Rechenzentrum von Meta in Odense
Die Datenschutzgrundverordnung (DSGVO)
Doch wie sieht das Ganze in der Europäischen Union aus? Was für Vorgaben gibt es hier?
In der EU wurde im Jahr 2016 die DSGVO eingeführt. Die erste Datenschutzbestimmung kam aus dem Jahr 1995, als das Internet noch lange nicht den Umfang angenommen hat wie heute. Die DSGVO soll somit alle datenschutzrechtlichen Themen und Rechte aus den unterschiedlichen Mitgliedsstaaten für die gesamte EU festhalten. Der Grund für die Einführung der neuen Verordnung ist, dass Unternehmen einen festen Fahrplan brauchen, wie sie mit den personalisierten Daten umzugehen haben, um nicht das Persönlichkeitsrecht der Nutzer und Besucher zu verletzen. Folgende Grundlagen werden deshalb in der DSGVO festgehalten:
Rechtmäßigkeit (Ob die Daten verarbeitet werden dürfen/ wenn ja wie)
Transparenz (welche Daten werden verarbeitet)
Zweckbindung (nur für bestimmten Zweck)
Speicherbegrenzung (Daten müssen gelöscht werden, wenn irrelevant oder gewollt)
Richtigkeit (keine falschen Daten verwenden)
Datenminimierung (Menge für Zweck angemessen)
Integrität und Vertraulichkeit (Schutz vor unfreiwilliger Weitergabe)
Rechenschaftspflicht (Dokumentation des Verarbeitungsprozesses)
Neue Datenschutzregeln
direkter Widerspruch
Das Problem hierbei ist jedoch, dass Big Data ein Sammelbegriff für solche Daten ist. Somit ist festzuhalten, dass Big Data an sich gar nicht den Prinzip der Datenminimierung einhalten kann. Big Data sammelt nicht nach einem Zweck, sondern die Daten an sich bestimmen zu welchem Zweck sie dienen. Vergleichbar ist das mit der Vorratsdatenspeicherung, die hierzulande für Aufsehen gesorgt hatte, da diese ab 2015 gegen das EU-Recht verstoßen hat. Big Data ist das, nur in noch größer… Die einzige Ausnahme sind Kinder, denn ihre Daten dürfen nicht analysiert werden. Da frage ich mich nur, woher wissen die denn, ob es sich um ein Kind handelt?
Witzige finde ich persönlich ja auch, dass in der DSGVO der Begriff Big Data unter dem Punkt Profiling fällt. Allein dieses Wort beschreibt die Existenzgrundlage der Big Data. Man versucht damit ein Bild oder Profil des Nutzers zu schaffen, mit all seinen guten und schlechten Seiten, Kreditwürdigkeit, Essgewohnheiten und alles was zum Leben dazugehört. Sozusagen ein Freundebuch, nur dass wir keine Freunde sind, sondern ein Stalkingopfer, ohne uns darüber bewusst zu sein.
Positive Entwicklung
Aber es muss trotzdem festgehalten werden, dass die restlichen Maßnahmen einen ernsthaften Unterschied im Umgang mit unseren Daten ausmachen. So wird beispielsweise die Dokumentation des Verarbeitungsprozesses eine besonders wichtige Aufgabe, denn dadurch kann nachvollzogen werden, was ausgewertet worden ist und ob das Unternehmen die Analyse solcher Daten valide begründen kann. Außerdem muss eine Risikoanalyse der Datenverarbeitung entwickelt werden und aufgefallene Risiken an die dafür zuständige Aufsichtsbehörde weitergeleitet werden. Einen weiteren positiven Faktor bringt die DSGVO noch mit sich. Dadurch, dass die Datenschutzproblematik mitten in der Öffentlichkeit steht, werden die unterschiedlichen Umgänge mit personenbezogenen Daten ein durchaus wichtiger Wettbewerbsfaktor für viele Unternehmen. Aber nur für die Unternehmen innerhalb der EU. Im EU-Ausland sieht das ganze anders aus.
Eine Expertenmeinung
Die Expertin ist Prof. Yvonne Hofstetter. Sie ist Autorin, Juristin und Essayistin, welche in Softwareunternehmen tätig ist und sich um die „Positionierung von Multi-Agentensystemen bei der Rüstungsindustrie und für den algorithmischen Börsenhandel“ kümmert, schilderte in einem Vortrag vom YouTube-Kanal BildungsTV aus dem Jahr 2014, wie das Geschäft mit Big Data funktioniert. So beschreibt sie unter anderem, dass der Finanzmarkt durch die Auswertung jeglicher verfügbaren Informationen, dem Militärsektor sehr ähnelt. So funktioniert der teilweise illegale Hochfrequenzhandel, bei dem Händler und Banken zusammenarbeiten, um dem Investor die Aktien möglichst teuer, weiterzuverkaufen. Auch Aktienpreise werden durch Algorithmen, die durch Unmengen an Finanzdaten gefüttert werden, gedrückt bzw. manipuliert. Außerdem zeigt sie das Ziel der Big Data Analyse im Wirtschaftssektor auf, welches ist, den Menschen zu manipulieren.
Das Beispiel
Der Wirtschaftlicher Erfolg ist nicht der einzige Zweck der durch Verarbeitung großer Datenmengen verfolgt wird. So habe sie einst an einem Projekt dem LKA Bayern mitgeholfen, bei dem man überprüfen wollte, ob sich der Drogenhandel von der einen Stadt in die andere verlegt hat. Dafür wurde ausgewertet, welche Delikte begangen worden sind, wer mit wem im Gefängnis saß, wer mit wem verwandt ist oder wer mit wem schonmal etwas zu tun hatte. Durch diese Analyse wurde dann klar, dass sich sowohl die Gruppierung, verantwortlich für den Drogenhandel geändert hatte, als auch Informationen über den Hintermann. Problematisch ist es nur dann geworden, als die Vorstrafen des Mannes gelöscht worden sind, jedoch das Wissen der Hintermann-Tätigkeit noch immer bestand. Das LKA entschied sich dann für den Datenschutz und das Löschen dieser Informationen, nachdem das Löschdatum von einem Rohdatensatz überschritten worden war.
Das Problem
Frau Professor Yvonne Hofstetter sieht das große Problem darin, dass die Technik, die zur Überwachung von Personen einst nur dem Militär zur Verfügung stand, jetzt auch im Privatsektor zu finden ist. Aber der Zweck ist kein anderer. So sagt sie unter anderem: „Wir, wir sind die Ursache für riesige Milliardengewinne bei Google oder Facebook, aber wir kriegen nichts dafür. Wir werden wie ich gerade gesagt habe, ausgebeutet.“
Forderungen
So fordert sie zu einem das Recht auf Gegenleistung für die eigenen Daten. Zudem ein Recht der Kontrolle und die damit verbundene Löschung der Daten. Zuletzt das Recht auf negative Freiheit, was so viel heißt wie, dass man keinen Nachteil durch die Nicht-Nutzung von digitalen Technologien erleidet. Diese Punkte wurden zum Teil in der DSGVO von 2018 umgesetzt und zu EU-Recht gemacht. So beispielsweise das Fenster, in dem man seine Cookies bestimmen kann.
Fazit
Nun denn, was halten wir nun von Big Data? Big Data hat sowohl Vorteile als auch massive Nachteile. Die Analyse der Daten hat zur Folge, dass zukünftige Ereignisse vorhergesagt werden oder bessere Entscheidungen getroffen werden können. Prozesse und Lieferketten können optimiert werden. Werbung wird immer besser die Zielgruppe ansprechen und Dinge über die man gerade gesprochen hat, schon als Werbung angezeigt bekommen. Irgendwie entsteht das digitale Abbild eines Selbst. Nur kommt man hier wieder zu dem unausweichlichen Kritikpunkt, dass der Mensch zum Produkt gemacht wird und eigentlich nichts von der Analyse der eigenen Daten hat. Der Mensch wird manipuliert und unterbewusst zu Entscheidungen gezwungen. Klar sollte sein, dass das eine kritische Entwicklung des Kapitalismus ist. Nur nicht von staatlicher Seite, sondern von Milliardenunternehmen, die nichts mehr interessiert, als uns zu Geld zu machen. Daher, passt, auf was ihr macht. Alleine seid ihr nie.
Die Datenschutzgrundverordnung, versucht hier die Sicherheit für die Nutzer zu wahren, bzw. wiederzuerlangen. Problematisch hierbei ist jedoch, dass nur 20 % der bei einer Bitkom-Umfrage befragten Unternehmen die DSGVO komplett umsetzt. 60 % der Unternehmen sagen, dass man in Deutschland mit dem Datenschutz übertreibe. Gut 80 % der Unternehmen haben fünf Jahre nach DSGVO Verabschiedung noch immer Probleme die Vorgaben durchzusetzen. Aber zumindest haben 60 % der Befragten angeben können, zumindest den Großteil der DSGVO umsetzten zu können. Ein Schritt in die richtige Richtung. Aber fertig sind wir noch lange nicht.
Wie wird die zukünftige Welt aussehen? Das ist eine Frage mit der die Menschheit sich oft auseinandersetzt und die auch in Filmen immer wieder aufgegriffen wird. Häufig spielt dabei Künstliche Intelligenz in Filmen eine Rolle. In vielen Fällen werden Maschinen dargestellt, welche mit Künstlicher Intelligenz oder kurz KI ausgestattet, ihre Schöpfer irgendwann unterwerfen. Aus Science Fiction Filmen sind Roboter dieser Art längst nicht mehr wegzudenken, doch die technischen Voraussetzungen dafür existieren in der realen Welt (noch) nicht.
Im Jahr 1956 wurde der Begriff „Artificial Intelligence“ also Künstliche Intelligenz von einer kleinen Gruppe Wissenschaftlern, die sich am Dartmouth College in den USA trafen, eingeführt. Dieser Workshop, der auch als „Dartmouth Conference“ bezeichnet wird, gilt als die Geburtsstunde der KI (vgl. Siekmann 1994, S. 20). Doch schon fünf Jahre vorher hat Alan Turing einen Test entwickelt, nachdem beurteilt werden kann, ob ein Computersystem „intelligent“ ist oder nicht. Bei diesem Test, den Turing „The Imitation Game“ nannte, wird mit Hilfe natürlicher Sprache getestet, ob ein Computersystem so kommunizieren kann, dass es von einem Menschen nicht mehr zu unterscheiden ist (vgl. Manhart 2022).
Alan Turing (ca. 1938)
Die Geschichte der Künstlichen Intelligenz in Medien
Auch schon bevor es die uns heute bekannte Künstliche Intelligenz gab, wurde sich in früheren Medien mit dem Thema der lebendigen Maschine auseinandergesetzt. So wurde der Begriff der Maschine im deutschsprachigen Raum schon etwa seit dem 17. Jahrhundert verwendet und findet sich so auch im Deutschen Wörterbuch der Brüder Grimm aus dieser Zeit. Hier wurde die Maschine noch als etwas Lebloses, synthetisches mit einem Artefakten-Charakter beschrieben (vgl. Brössel 2021, S. 28). Außerdem befindet sich eine frühe Darstellung von künstlicher Intelligenz auch in dem Werk „Die Automaten“ von E.T.A Hoffmann aus dem Jahr 1814 , in dem eine mechanische Puppe beginnt Fragen von Menschen zu beantworten (vgl. Brössel 2021, S. 27).
Der Beginn von Künstlicher Intelligenz in Filmen
Mit der Erfindung von Filmen verlagerte sich das Thema der lebendigen Maschine auch immer mehr ins Kino und Fernsehen. Eine frühe Darstellung von Künstlicher Intelligenz in Filmen ist z. B. die Verfilmung des Science-Fiction-Romans Metropolis. Der gleichnamige Stummfilm erschien im Jahre 1927 und zeigt eine düstere Zukunft, in der Menschen von Androiden unterdrückt werden. Für den damaligen Stand der Filmtechnik war der Film visuell sehr eindrucksvoll und zeigte unter anderen Aufnahmen von riesigen Häuserschluchten, großen Maschinen und fortschrittlichen Verkehrsmitteln. Auch beeinflusste Metropolis spätere Filme wie Blade Runner oder Matrix stark (vgl. Schreiner 2022).
Trailer zu Metropolis (1927)
Terminator und Ex Machina
Eine Filmreihe, die sich mit einer düsteren Zukunft für die Menschheit auseinandergesetzt, ist Terminator. Der große Erfolg der Terminator Filme prägt bis heute unser Bild von künstlicher Intelligenz und Robotern. Bei der in den Terminator Filmen dargestellten KI handelt es sich stets um eine bösartige Super-KI und Killer-Roboter, die als einziges Ziel die Auslöschung der Menschheit haben (vgl. Schreiner 2022). Mit aktuell 6 Filmen, welche in den Jahren 1984 bis 2019 entstanden sind, gehört die Terminator Filmreihe zu einer der bekanntesten, welche sich mit den negativen Seiten und Folgen von Künstlicher Intelligenz auseinandersetzt. Auch der Film Ex Machina aus dem Jahr 2015 behandelt das Thema der künstlichen Intelligenz und setzt sich unter anderem mit der Frage auseinander, was Bewusstsein ist und ob eine Maschine ein Bewusstsein haben kann (vgl. Schreiner 2022). Eine Besonderheit von Ex Machina ist hierbei, dass die Künstliche Intelligenz in diesen Film nicht primär als Böse dargestellt wird, wie es z.B. in Terminator und vielen anderen Filmen der Fall ist. Sondern das in diesem Werk der Zuschauer dazu ermutigt wird, über das menschliche Wesen, menschliche Züge und die Frage, was einen Menschen von einer Künstlichen Intelligenz unterscheidet, nachzudenken (vgl. Mehnert 2016).
Filme über Künstliche Intelligenz (KI)
Blade Runner (1982)
Tron (1982)
Terminator (1984)
Matrix (1999)
I,Robot (2004)
Transcendence (2014)
Ex Machina (2014)
Avengers: Age of Ultron (2015)
Blade Runner 2049 (2017)
I am mother (2019)
Free Guy (2021)
Ich bin dein Mensch (2021)
Weltherrschaft der Maschinen?
Künstliche Intelligenz in Filmen begegnet uns häufig, aber in den seltensten Fällen wird die Handlung des Films durch sie positiv beeinflusst. Entweder sind sie nur „kindliche Maschinen“ als Nebendarsteller, wie z.B. C-3PO oder aber die Künstliche Intelligenz unterjocht die Menschheit und strebt die Weltherrschaft an, wie die Superintelligenz in „I, Robot“. Doch trotz all der Forschung auf dem Gebiet der KI sind solche, in ihrem Handeln flexible Maschinen, nach heutigem Stand, nicht realistisch (vgl. Lenzen 2020, S.119).
KIs werden in hochspezialisierten Gebieten eingesetzt, in denen sie die Leistung, die ein Mensch erbringen könnte, teilweise heute schon übertreffen. Diese Art Künstliche Intelligenz nennt man schwache KI, da sie nur für eine bestimmte Aufgabe erschaffen wurde. Sobald man dieser KI komplexere Aufgaben stellt, würde sie scheitern. Im Gegensatz zu dieser schwachen KI gibt es noch die starke KI, die ähnlich wie ein Mensch, flexibel auf unterschiedliche Situationen reagieren kann (vgl. zu diesem Abschnitt Volland 2018, S.14).
Doch starke Künstliche Intelligenz existiert bis heute (noch) nicht. Es gibt die unterschiedlichsten Aussagen von Wissenschaftlern, ob und wann diese starke Künstliche Intelligenz tatsächlich entwickelt werden könnte. Dabei schwanken die Aussagen zwischen 20 und 200 Jahren oder auch nie (vgl. Lenzen 2020, S. 120). Zumindest können wir starke Künstliche Intelligenz in Filmen weiterhin bewundern. Im folgenden Abschnitt könnt ihr euer Wissen über KIs in Filmen testen. Viel Spaß!
Quiz
Quellen
Brössel, Stephan (2021): Die Anthropologie der Goethezeit und Automaten: Ein diskursanalytischer Aufriss und eine exemplarische Analyse von E. T. A. Hoffmanns Die Automate(1814). In: Irsigler, Ingo u.a. (Hg.): Roboter, Künstliche Intelligenz und Transhumanismus in Literatur, Film und anderen Medien. Heidelberg: Universitätsverlag Winter, S. 27 – 44
Mehnert, Ann-Kristin (2016): „Ex Machina“ (2015). Philosophische Betrachtungen über das (Selbst-) Bewusstsein im Spannungsfeld zwischen Mensch und Maschine. Online unter https://www.grin.com/document/322981 [Abruf am 26.12.2022]
Siekmann, Jörg (1994): Künstliche Intelligenz: Von den Anfängen in die Zukunft. In: Cryanek, Günther; Coy, Wolfgang (Hg.): Die maschinelle Kunst des Denkens. Braunschweig: Vieweg, S. 11-41
Volland, Holger (2018): Die kreative Macht der Maschinen. Warum Künstliche Intelligenzen bestimmen, was wir morgen fühlen und denken. 1. Auflage. Weinheim: Beltz
„Alexa, wer hat versucht, uns zu erpressen?“ Ganz so leicht ist es dann doch nicht. Die Forensische Linguistik ist eine kriminalistische Hilfswissenschaft, die sich mit Sprache im gerichtlichen Kontext beschäftigt. Dazu zählen sowohl die vor Gericht verwendete Sprache wie auch beispielsweise die Autoren- und Sprechererkennung (Fobbe, S. 15 f.). Oder, um es mit den Worten von Patrick Rotter, selbst in der Forensischen Linguistik tätig, zu sagen: „Für uns Sprachprofiler ist Sprache in erster Linie Identität. Egal ob gesprochen oder geschrieben. Sie ist ein Teil von uns.“ (Rotter, S. 15) Um Identität(-sfindung) soll es in diesem Beitrag gehen – und um die Frage, wie sehr die Künstliche Intelligenz (KI) in diesem Bereich Ermittler*innen entlasten oder vielleicht sogar ersetzen kann.
Entwicklung der Spracherkennung
Der Versuch, Sprache mittels Computern zu analysieren und zu erkennen, ist nicht neu:
Zeitleiste: Meilensteine der computergestützten Spracherkennung
Was aber, wenn es nicht nur darum geht, kurze Nachrichten in Text zu verwandeln, sondern etwa herauszufinden, wer eine anonyme Drohbotschaft versendet hat? In den letzten Jahren gab es mehrere Studien dazu, von denen ich hier zwei vorstellen möchte.
Software & Audioerkennung
Mit Spracherkennung von komplexeren Audiodateien hat sich unter anderem Franz Bellmann in seiner Bachelorarbeit beschäftigt: er testete sechs frei verfügbare Softwares auf die Eignung zur Transkription von Audiodateien (mit verschiedenen Längen, in verschiedenen Sprechgeschwindigkeiten und mit und ohne Dialekt) in einem polizeilichen Kontext (Bellmann, S. 23). Wie seinen Schlussfolgerungen zu entnehmen ist, haben alle benutzten Programme Schwierigkeiten bei der Worterkennung, Google Web Speech API hat sich am besten geschlagen (Bellmann, S. 47). Doch selbst diese beste Alternative hat immer noch eine Fehlerrate von ca. 30%(!) bei der Transkription (Bellmann, S. 44).
Software & Textzuordnung
Manuel Dorobek untersuchte in seiner Masterarbeit 2021 ein ähnliches Projekt, aber auf geschriebene Texte bezogen: kann die KI im Internet veröffentliche Rezensionen zuverlässig den jeweiligen Autor*innen zuordnen? Er wählte 25 Autor*innen mit jeweils 100 verfassten Texten aus (Dorobek, S. 25), die vom besten Modell mit einer Genauigkeit von 96,4% erkannt wurden (Dorobek, S. 149). Zum Trainieren der KI wurden 60 Vorlagetexte genutzt (Dorobek, ebd.). Zwei Autor*innen voneinander zu unterscheiden, gelang schon mit drei Vorlagen (Dorobek, ebd.). Das sind sehr gute Werte, doch in der echten Welt ist der Kreis der Verdächtigen nicht immer so leicht eingrenzbar. Außerdem kann es sein, dass nicht genug Vergleichstexte vorliegen oder keine Texte in ausreichender Länge – weshalb auch Dorobek selbst zu dem Ergebnis kommt: „Für einen Anwendungsfall in der Praxis sind diese Ergebnisse deshalb mit Vorsicht zu betrachten.“ (Dorobek, ebd.)
Fazit
KI kann also bisher beim geschriebenen Wort besser unterstützen als beim gesprochenen. Bis die Technik weit genug entwickelt ist, um gerichtsfeste Ergebnisse zu liefern – denn immerhin geht es hier auch um Straftaten und die Frage, ob Menschen ins Gefängnis kommen! – wird also noch einige Zeit vergehen. Bis dahin gilt die Einschätzung von Patrick Rotter:
„Unsere Lebensleistung an Wort und Text ist schlicht nicht zu erfassen. Und dank der zwangsläufigen Veränderungen auch nicht in starre Muster zu packen. […] Keine künstliche Intelligenz dieser Welt ist in der Lage, sämtliche Dialekte, feinste Nuancen und die ständigen Veränderungen in der Sprache zu begreifen.“ (Rotter, S. 40)
Quellen
Fobbe, Eilika (2011): Forensische Linguistik. Tübingen: Narr Francke Attempto Verlag Rotter, Patrick (2021): Die geheimen Muster der Sprache. 3. Auflage, München: Redline-Verlag Bellmann, Franz (2020): Prototypische Systemintegration und Evaluation von Open Source Sprachmodellen zur automatischen Spracherkennung gesprochener deutscher Texte. Online-Ressource, abrufbar unter BA Bellmann Dorobek, Manuel (2021): Automatisierte Autorschaftsanalyse in der deutschen Sprache mittels forensischer Linguistik. Online-Ressource, abrufbar unter MA Dorobek Bildquelle: Wedekind, Kai: HTML 5 Speech Recognition API. Online abrufbar unter https://miro.medium.com/v2/resize:fit:1100/format:webp/1*iYxrR4zaECeQ5AgSq3jy_A.png Beitragsbild: mohammed_hassan auf Pixabay. Online abrufbar unter https://pixabay.com/images/id-7620463/
Wenn Stricken und Programmieren im selben Satz erwähnt werden, dann meist zur Verbildlichung von Gegensätzen: Tradition trifft auf Moderne, analog trifft auf digital, belächelnswertes DIY-Hobby trifft auf zukunftsorientierten Skill. Es mag widersprüchlich erscheinen, doch die Jahrhunderte alte Handarbeitstechnik und Programmiersprachen haben mehr gemein, als es auf den ersten Blick vermuten lässt. Jemand sitzt stundenlang vor unzähligen Zeilen mit kryptisch anmutenden Kürzeln, oft bis tief in die Nacht hinein und an einem bestimmten Punkt stellt sich das Gefühl ein, die Arbeit einfach nur noch in die Ecke pfeffern zu wollen. Dieses Gefühl kennen sowohl Programmierer:innen als auch Strickende.
Die binäre Basis
So groß wie die Vielfalt an Programmiersprachen ist, so groß ist auch die Vielfalt an Stricktechniken und Mustern – wahrscheinlich sogar größer. Beiden ist jedoch gemein, dass sie sich jeweils auf zwei Grundbausteine zurückführen lassen: Einsen und Nullen bzw. rechte und linke Maschen. An dieser Stelle soll kein Stricktutorial folgen, doch die grundlegenden Strickbegriffe sollten für ein besseres Verständnis bekannt sein.
Eine Strickschrift ist die grafische Repräsentation eines Strickmusters mit Hilfe eines Kästchenrasters und Symbolen für die verschiedenen Maschenarten. Der binäre „Übersetzung“ ist im Vergleich komplexer.
Strickarbeiten können in Reihen oder Runden angefertigt werden. Die Strickrichtung verläuft dabei von rechts nach links. Eine Reihe oder Runde besteht aus Maschen, die während der Arbeit auf der Stricknadel liegen. Rechte Maschen bilden oft die Vorderseite des Gestricks und sehen aus wie „V“s. Sie bilden eine glatte Oberfläche. Linke Maschen erzeugen dagegen kleine Knötchen, wenn sie einzeln auftauchen, bzw. eine Wellenstruktur in der Fläche.
Rechte und linke Maschen sind die Einsen und Nullen des Strickens: Auf ihnen bauen alle weiteren Techniken auf.
Außer rechten und linken Maschen gibt es noch viele weitere Techniken, etwa Ab- und Zunahmen, um das Gestrick zu formen oder dekorative Elemente wie Zöpfe, Umschläge oder tiefer gestochene Maschen. Sie alle beruhen jedoch auf den rechten und linken Maschen, mit denen sich komplette Strickstücke inklusive komplexer Strukturmuster stricken lassen.
Genau dieses Strukturmuster mit binärer Basis sind es, die das Stricken zum perfekten Nachrichtenmedium gemacht haben, lange bevor es ausgefeilte digitale Chiffrier- und Dechriffiertechnologien gab. Selbstverständlich war der Wollpullover mit Noppenmuster nicht der Vorläufer der E-Mail. Besonders in Kriegszeiten hat das Stricken jedoch eine wichtige Rolle beim verschlüsselten Sammeln und Weitergeben von Informationen gespielt.
Steganografie: gestrickte Geheimbotschaften
Eine ältere Dame sitzt am Fenster und strickt. Von ihrem Platz hat sie einen guten Blick auf die Züge, die nicht weit von ihrem Haus entfernt vorbeifahren. Eigentlich eine idyllische Vorstellung, wenn es sich dabei nicht um Kriegsgerät der deutschen Besatzer und eine französische Spionin während des Ersten Weltkrieges handeln würde. Als Spion gilt es unauffällig zu sein, keine Aufmerksamkeit zu erregen. Doch das Stricken ist nicht nur Teil der Tarnung. Die Strickware selbst kann zur geheimen Botschaft werden, indem ein Code in die Maschen eingebaut wird. Diese Form der Steganografie, die verborgene Übermittlung von Informationen, kam sowohl im Ersten als auch im Zweiten Weltkrieg zum Einsatz.
„Drop one for a troup train, purl one for an artillery train“ – so lautet es in der BBC-Dokumentation MI6: A Century in the Shadows, also eine Masche fallen lassen für einen Truppenzug, eine linke Masche stricken für einen Artilleriezug. Man kann davon ausgehen, dass statt „drop one“ hier eher ein Umschlag gemeint ist, der zwar ein Loch erzeugt, aber das Gestrick nicht weiter auflöst. Den Militärhistorikern sei an dieser Stelle ihre Strickunkenntnis verziehen. Wie gut, dass die richtige Spionagearbeit den älteren Damen überlassen wurde …
Eine noch naheliegendere Form der Informationsübermittlung mittels Gestrick ist der Einbau von Morsebotschaften. Die erhabene Struktur der linken Maschen ist ideal, um mit ihnen Strich- und Punktkombinationen nachzubilden. Für das ungeübte Auge wirken sie dabei lediglich wie ein Strukturmuster, besonders, wenn der eigentliche Code durch andere Musterelemente kaschiert wird.
Es ist jedoch nicht nur das Gestrick an sich, das als steganografisches Medium genutzt werden kann. Der Mix aus Kürzeln und Ziffern bietet sich gerade dafür an, verschlüsselte Informationen darin zu verstecken. Aus diesem Grund haben sowohl die USA (im Zweiten Weltkrieg) als auch Großbritannien (im Ersten Weltkrieg) den Auslandsversand von Strickanleitungen verboten. Die durch Abkürzungen bestimmte Form von Strickanleitungen lassen sie für Außenstehende nahezu unverständlich wirken – ganz so wie Programmcode …
Man plauscht auf dem Flur, beredet in der Teeküche Neuigkeiten aus dem Fachbereich und arbeitet natürlich gemeinsam an Projekten: Der (zum Glück nicht mehr nur virtuelle) Kontakt mit Kolleg:innen aus dem eigenen Institut oder der Fakultät ist eine Selbstverständlichkeit für Forschende. Doch wie wäre es, sich mit nur wenigen Klicks mit mehr als 300 000 Expert:innen aus der eigenen Disziplin vernetzen zu können? Wie wäre es, blitzschnell Spezialist:innen für isländische Verkehrsdaten finden zu können? Oder solche für Straßenschild-Design in Deutschland? (Das wären übrigens 18 Personen.) Wenn es doch nur ein praktisches Tool dafür geben würde …
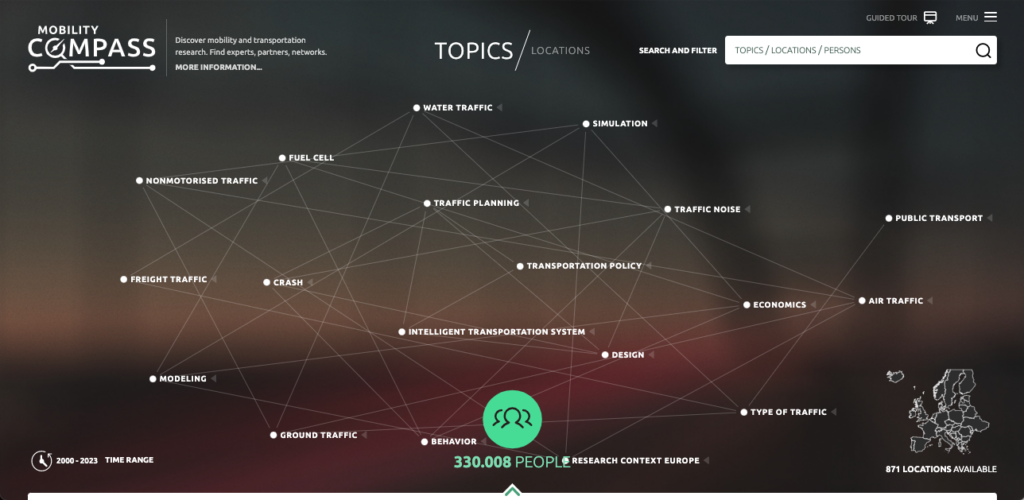
Auftritt: Der Mobility Compass!
Wir – das sind die Teilnehmenden der Veranstaltung Recherche wissenschaftlicher Informationen – durften bei einer Exkursion zur Technischen Informationsbibliothek (TIB) einen umfangreichen Einblick in den FID move erhaschen. Mathias Begoin, der zur Leitung des FID an der TIB gehört, hat uns dabei auch eben jenes Vernetzungswerkzeug vorgestellt, das die Auffindbarkeit von Forschenden des Verkehrswesens drastisch erhöht.
Der FID move (Fachinformationsdienst Mobilitäts- und Verkehrsforschung) wird seit 2018 von der TIB und der SLUB im Rahmen des DFG-Förderprogramms „Fachinformationsdienste für die Wissenschaft“ aufgebaut.
Wie funktioniert der Mobility Compass?
Um es gleich vorweg zu nehmen: super unkompliziert – zumindest für uns Nutzende. Der Mobility Compass wurde von der SLUB Dresden (der Sächsischen Landesbibliothek – Staats- und Universitätsbibliothek) im Rahmen des FID move entwickelt. Er beruht auf der Open Source Software VIVO, die Informationen über Forschende und ihre Arbeiten verwaltet und darstellt. Das wiederum funktioniert über standardisierte Datenformate und verschiedene Ontologien. Das sind, ganz grob gesagt, geordnete Sammlungen von Begriffen eines Themenbereiches und den Beziehungen zwischen ihnen. Mit Hilfe von Ontologien lassen sich also Zusammenhänge und Verknüpfungen darstellen – und das in maschinenlesbarer Form. Doch wie kommen die Daten in den Mobility Compass?
Datengrundlage
Wer forscht und publiziert und sich auch noch um solche lästigen Dinge wie Projektfinanzierung kümmern muss, hat nicht unbedingt Zeit und Lust, jede einzelne Veröffentlichung händisch in zehn verschiedene Datenbanken einzupflegen. Wie gut, dass sich dieser Aufwand drastisch reduziert, wenn die Forschenden eine ORCID iD aufweisen. Mit ihr lassen sich Personen eindeutig identifizieren sowie Arbeiten und Forschungsdaten zuweisen. Ein weiterer großer Vorteil ist, dass die ORCID iD auch mit anderen Systemen verknüpft werden kann. Wäre es nicht fabelhaft, wenn der Mobility Compass einfach auf diese bereits zusammengestellten Informationen in professionell erschlossenen Datenbanken zugreifen könnte?
Natürlich ist das fabelhaft und natürlich tut der Mobility Compass genau das! Neben ORCID gibt es noch elf weitere Datenquellen, aus denen die Daten aktuell bezogen werden. Dazu gehören beispielsweise auch die wissenschaftliche Suchmaschine BASE, die Deutsche Nationalbibliothek aber auch der Verlag Springer Nature. Ein weiterer wichtiger Bestandteil ist der Transportation Research Thesaurus (TRT). Er beinhaltet das standardisierte Normvokabular, auf dessen Grundlage die Inhaltserschließung der Ressourcen erfolgt.
Benutzung des Mobility Compass
„Die frühen 2000er haben angerufen – sie wollen ihr Webseiten-Design zurück.“ Das ist nicht nur der Versuch eines humoristischen Absatzbeginns. Nein, dieser Gedanke kam uns im Seminar Recherche wissenschaftlicher Information öfter, als wir die Benutzeroberflächen so einiger wissenschaftlicher Suchportale sahen. Der Mobility Compass ist mit seinem modernen Design und seiner leichten Bedienbarkeit ein echtes Juwel unter den Webanwendungen.
Der topic graph zeigt eine Auswahl von Themen und verknüpft solche miteinander, die häufig zusammen erforscht werden. Alternativ kann auch nach Thema, Ort oder Person über die Suchzeile gesucht werden.
Visualisierung wird beim Mobility Compass großgeschrieben! Auf der Startseite werden bereits einige Themen und ihre Verknüpfung untereinander angezeigt. Mit Klick auf das jeweilige Thema wird die Liste relevanter Personen eingeschränkt. Statt nach einem Thema kann die Suche auch geographisch (innerhalb Europas) eingeschränkt werden. Dafür kann die Auswahl über die Karte oder über die Suchzeile erfolgen. Einfach, unkompliziert und schnell: So mögen wir unsere wissenschaftliche Recherche!
Fazit
Der Mobility Compass ist ein geniales Vernetzungstool, dass das Auffinden von Forschenden aus dem Bereich des Verkehrswesens enorm erleichtert. Der uneingeschränkte Zugang, die einfache Bedienung und aufgeräumte Oberfläche sorgen für schnelle Ergebnisse bei der Suche. Wir können nur hoffen, dass sich andere Fachbereiche in dieser Hinsicht eine Scheibe vom FID move abschneiden.