Am Anfang steht die Keywordrecherche. Ob Blog, Onlineshop oder Unternehmenswebsite, die Onlinepräsenz spielt heutzutage eine immer größere Rolle und ist nicht mehr wegzudenken. [1] Du möchtest auch mit deiner Präsenz im Netz überzeugen und so viele Menschen wie möglich erreichen? Dann ist die Keywordrecherche genau das Richtige für dich! Finde heraus, worum es sich hierbei handelt und wieso sie so wichtig ist.
Im Vordergrund der Recherche stehen sogenannte Keywords, aber was genau ist ein Keyword?
Im Deutschen steht der Begriff Keyword für Such- und Schlüsselbegriff sowie Schlag- und Schlüsselwort und wird bei der Recherche im Internet in das Suchfeld einer Suchmaschine eingegeben. [2] Damit die passenden Ergebnisse für deine Suchanfrage rausgefiltert werden, gleicht die Suchmaschine die eingegebenen Keywords mit den Seiten aus dem Index ab. [3]
Arten von Keywords
Bevor du dich mit der Recherche befasst, ist es wichtig, zwischen den verschiedenen Arten und Nutzerintentionen von Keywords unterscheiden zu können. Im Folgenden findest du die wichtigsten Varianten. [4]
Fokus Keyword
Das Fokus Keyword wird von dir definiert und ist der Hauptbegriff, für den deine jeweilige Seite in den Suchergebnissen ranken soll. [5]
Nischen Keyword
Von einem Nischen Keyword ist die Rede, wenn ein Suchbegriff ein niedrigeres Suchvolumen, aber auch wenig Wettbewerb hat. Neben dem Fokus Keyword werden auch Nischenkeywords verwendet, da es hier einfacher ist mit diesen Suchbegriffen zu ranken. [6]
Brand Keyword
Von einem Brand Keyword ist die Rede, wenn du mit deiner Suchanfrage nach einer bestimmten Marke suchst. [7]
Bildschirmfoto – Brand Keyword
Informationsorientiertes Keyword
Wenn nach einer bestimmten Information gesucht wird, werden informationsorientierte Keywords verwendet. [8]
Bildschirmfoto – Informationsorientiertes Keyword
Navigationsorientiertes Keyword
Keywords sind navigationsorientiert, wenn du mit deiner Anfrage gezielt nach einer Seite suchst. [9]
Bildschirmfoto – Navigationsorientiertes Keyword
Transaktionsorientiertes Keyword
Wie der Name bereits verrät, sind transaktionsorientierte Keywords Suchbegriffe, die das Durchführen einer Transaktion zum Ziel haben. [10]
Bildschirmfoto – Transaktionsorientiertes Keyword
Compound Keyword
Ein Compound Keyword ist gemeint, wenn du mit deiner Eingabe mehrere Nutzerintentionen erfüllst. Schauen wir uns folgende Suchanfrage an:
Bildschirmfoto – Compound Keyword
Hier suchen wir nicht nur nach einer bestimmten Marke (Brand Keyword), sondern auch nach einer Möglichkeit, den Schuh zu kaufen (transaktionsorientiertes Keyword). [11]
Keywords und ihre Wortlänge
Keywords können zudem auch in ihrer Wortanzahl unterschieden werden. Hierbei unterscheiden wir zwischen Short-, Mid- und Long Tail Keywords.
Short Tail Keyword
Das Short Tail Keyword besteht lediglich aus ein oder zwei Suchbegriffen. Diese haben in der Regel ein hohes Suchvolumen. Aufgrund der Wortanzahl handelt es sich bei den Suchergebnissen eher um unspezifische Treffer. [12]
Mid Tail Keyword
Eine weitere Variante ist das Mid Tail Keyword, welches aus 2 bis 3 Wörtern bestehen kann. Hiermit können Suchergebnisse bereits etwas konkretisiert werden. [13]
Long Tail Keyword
Beim Long Tail Keyword handelt es sich um die spezifischste Suchanfrage. Hier werden Phrasen mit mehreren Wörtern verwendet. [14]
Was ist eine Keywordrecherche?
Bei der Keywordrecherche handelt es sich um eine Methode, mit der du herausfinden kannst, welche Suchanfragen für dich, deinen Kunden oder für deine Zielgruppe wichtig sein können. Zu beachten ist hier, welche Keywords am meisten gesucht werden und welche Nutzerintention diese haben, denn anhand dieser Informationen kannst du deine Website sinnvoll optimieren und weiter ausbauen. Die Keywordrecherche ist der erste und wichtigste Schritt für dein Optimierungsvorhaben und sollte daher fester Bestandteil deiner Arbeit sein. [15]
Dabei kann dir die Recherche helfen
Die Recherche von Keywords ist für den Erfolg einer Website von großer Bedeutung und daher ein fester Bestandteil des Online-Marketings. Du fragst dich trotzdem wieso du dich an einer Recherche versuchen solltest? Hier findest du meine Top 4 Gründe:
1. Do it for the Blog!
Mit Hilfe der Recherche kann auch die Themenfindung für deinen Blog deutlich vereinfacht werden. Mit der Keywordrecherche kannst du herausfinden wonach deine Zielgruppe am meisten sucht. Schreibe deinen Blogbeitrag und pflege dabei Keywords ein. Starte mit dem Fokus Keyword und füge anschließend passende Nischenkeywords hinzu.
Achtung: Keywords sollten nicht nur verwendet werden, weil sie ein hohes Suchvolumen haben. Die Chancen auf ein gutes Ranking sind hier eher gering, da auch weitere Einflussfaktoren wie der Wettbewerb eine Rolle spielen. Trau dich ruhig Keywords mit etwas weniger Suchvolumen zu nutzen. Eine weitere Alternative wären Long Tail Keywords.[16]
2. Werde dir über den Markt bewusst
Die Keywordrecherche hilft dir dabei den Markt besser kennenzulernen und zu verstehen, denn durch diese Methode können unter anderem Probleme und Ängste deiner Kunden offengelegt, neue Kunden dazugewonnen, Mitbewerber analysiert oder neue Märkte erschlossen werden.[17]
3. Für mehr Buzz: Advertising in Suchmaschinen
Falls du Interesse an der Suchmaschinenwerbung (SEA) hast, wird dir die Recherche auch hier helfen, eine erfolgreiche Ads Kampagne auf die Beine zu stellen. Kampagnen mit den richtigen Keywords haben eine größere Reichweite und bringen dir zudem mehr Traffic.[18]
4. Gib deiner Seite den letzten Schliff
Unabhängig davon, ob du einen Blog, Onlineshop oder einer Unternehmensseite führst, durch die Recherche kannst du wertvolle Erkenntnisse gewinnen, um deine Seite zu optimieren. Je besser deine Inhalte sind, desto wahrscheinlicher ist es, dass deine Seite gefunden wird!
Tipp: Setzte dich mit deinen Produkten oder deinen Dienstleistungen auseinander und schaue welche Suchbegriffe genutzt werden. Hier ist dein Verstand gefragt! [19]
Do it yourself!
Du bist neugierig geworden? Dann probier es einfach mal aus! Einen genauen Leitfaden findest du in diesem Video.
Hier findest du eine Übersicht der verwendeten Online-Tools aus dem Video sowie einige Alternativen:
Die Keywordrecherche ist ein unverzichtbares Werkzeug im Online-Marketing und ist das A und O, wenn du deine Seite optimieren möchtest. Schöpfe das volle Potenzial deiner Seite aus, schreibe relevante Blogbeiträge, lerne den Markt und deine Kunden besser kennen oder plane eine erfolgreiche Ads Kampagne. Mit dieser Methode gelingt es dir bestimmt!
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Sommersemester 2020, Andre Kreutzmann) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Auf der Website befinden sich…
…Großartige, Originelle, Ordentliche, Greifbare, Leserliche Ergebnisse!
Und wie erreiche ich dieses?
Indem du deine Inhalte aus SEO-Sicht optimierst! Die nächsten Schritte erklären dir kurz und knapp, was du in Bezug auf deinen Content machen kannst, damit deine Website bei Google eine gute Bewertung erhält. Kommen wir zum Grundlegenden.
Warum sollte ich meine Inhalte für Google optimieren?
Der Weg zu einem besseren Ranking bei Google.
Zuallererst ist es wichtig, dass du den Grund für die Optimierung deiner Ergebnisse verstehst. Siehst du den freundlich lächelnden Smiley? Das bist du. Du hast eine Website, die mit Inhalten gefüllt werden muss. Der Begriff „Inhalt“ ist jedoch sehr breit aufgestellt. Also kommen wir zur ersten eigentlichen Frage – welche Inhalte gibt es?
Content über Content
Wie du sicher schon bemerkt hast, wird der Inhalt einer Website meistens auch „Content“ genannt. Hinter diesem Begriff verstecken sich allerhand Ergebnisse, die du auf deiner Website veröffentlichen kannst, um deine jeweilige Zielgruppe anzusprechen.
Jede dieser Inhaltsformen bringt besondere Anforderungen mit sich. Im nächsten Schritt erfährst du genauer, was du bei Bildern, Texten und Videos machen kannst, damit Google sagt: „Deine Website hat tolle Inhalte, sie bekommt den ersten Platz!“[1]
Bilder, Texte und Videos aus SEO-Sicht
Selbstverständlich gibt es außer Bildern, Texten und Videos noch weitere Inhalte, die du auf deiner Website platzieren kannst. Bei jeglichem Content ist es allerdings wichtig, dass du darauf achtest, dass dieser den Nutzern einen Mehrwert bietet. Das erreichst du im Allgemeinen, wenn der Inhalt einzigartig und auf die jeweilige Zielgruppe ausgerichtet ist. Dabei soll er bestenfalls zu Interaktionen, wie dem Klicken auf Buttons, Teilen oder Liken von Beiträgen oder dem Ausfüllen des Kontaktformulars führen[2]. Damit du dies in Bezug auf Texte, Bilder und Videos erreichst, gehe ich darauf nun detailliert ein.
Bilder optimieren
Durch Bilder auf Platz 1
Es ist wichtig, dass du Bilder auf deiner Website nutzt, da diese zum einen die Optik deiner Seite sehr aufwerten, aber auch wichtige Informationen an den Nutzer bringen können. Das Ranking von bebilderten Websites ist einfach besser.
Dateiformat & Dateigröße anpassen
In Bezug auf die Ladezeit deiner Website rate ich dir, auf Dateigröße und dennoch gute Qualität der Bilder zu achten. Dazu solltest du hochauflösende Bilder ggf. komprimieren und gängige Dateiformate nutzen, wie:
PNG
JPG
GIF
Richtige Datei-Metadaten nutzen
Wie Google den Inhalt deines Bildes erkennt? Durch den Dateinamen! Deshalb bitte das Motiv immer als Name verwenden und nicht einen Platzhalter, wie „Bild1“. Trenne mehrere Wörter dabei mit Bindestrichen (keine Unterstriche verwenden!). Ein letzter Tipp zum Dateinamen – vermeide Großbuchstaben, Sonderzeichen und Umlaute.
Bei der Festlegung des Alt- und Title-Tags gibt es allerdings ebenfalls SEO-Möglichkeiten, du du nutzen solltest. Beim Title-Tag bitte den Dateinamen des Bildes verwenden, da Google dadurch einen Blick in den Bildinhalt erlangt. Den Title-Tag kann der Nutzer sehen, indem er mit der Maus über das Bild fährt.
Der Alt-Tag hingegen erscheint dem User, wenn das Bild nicht angezeigt werden kann. Zudem nutzen Programme diesen, um den Inhalt für Sehbehinderte zu umschreiben. Der Tag ist im Allgemeinen dazu da, das Bild thematisch zu beschreiben, sodass Google es einordnen kann. Dabei kannst du zum Beispiel Synonyme gut unterbringen.
Kontext & Thematik
Dein Bild sollte thematisch immer zum restlichen Inhalt deiner Website passen, da Google, wie zuvor erwähnt, den Bildinhalt erkennen kann und das bei dem Ranking der gesamten Seite berücksichtigt. Bei der Bildposition ist es von großer Bedeutung, dass sich das Bild immer auf den jeweiligen Text bezieht.
schummeln geht nicht
Da die Technologien von Google immer besser werden, kann die Suchmaschine mittlerweile, unabhängig von den Metadaten, grob erkennen, was sich auf deinem Bild befindet, sodass die Angabe falscher Metadaten sehr schädlich ist. Auch ist es besser, wenn du die Bilder selbst erstellst und keine Bilder nimmst, die schon sehr viel im Web herumschwirren. Lade jedes Bild aber bitte nur einmal, sonst handelt es sich um Duplicate-Content! Nichtsdestotrotz kannst du es mehrfach einbetten, wenn es passt“[3].
Suchmaschinenoptimierte Texte
Mit Texten nach oben klettern
Auch Texte beinhalten einige Aspekte, die du beachten und optimieren solltest, damit deine Website bei Google nach oben klettern kann.
Text ist Text
Egal ob es sich bei deinem Text um eine Produktbeschreibung, einen Blogbeitrag oder Ähnlichem handelt – jeder Text sollte für die Suchmaschine aufbereitet und von dieser verstanden werden, um dein Ranking zu verbessern.
Keywords sind King
Bitte nutze Keywords in deinen Texten. Normalerweise geschieht das fast automatisch, wenn du deinen schriftlichen Content an deiner Zielgruppe ausrichtest. Allerdings solltest du Aspekte, wie die Keyworddichte besonders beachten.
Die Keyworddichte beschreibt dabei das relative Verhältnis der Keywords zum restlichen Inhalt deines Textes. Diese sollte ca. 3-4% betragen. Da die Texte in der Regel aber für die Nutzer deiner Website geschrieben werden, ist es ratsam, das Schriftstück nicht zu überladen. Beachte dabei:
Keywords in allen Abschnitten & in den Überschriften verwenden
Synonyme von Keywords nutzen
Kein zwanghafter Einsatz der Keywords
Grammatikalische Anpassungen & Füllwörter sind erlaubt
Benutzerfreundlichkeit ist das A und O!
Auf den Aufbau kommt es an
Die Hierarchie der Überschriften
Deine Überschriften müssen logisch aufgebaut sein. Dabei gibt es immer nur eine als <h1> (HTML) ausgezeichnete Headline. Anschließend kann es mehrere <h2> geben. Werden Abschnitte darunter nochmals gegliedert, kommen <h3> Überschriften zum Einsatz.
Absätze – nicht nur schick, sondern auch praktisch
Absätze sind nützlich, wenn du die Strukturierung deines Textes und die Lesbarkeit für den Nutzer verbessern möchtest. Zudem kannst du sogenannte Sprungmarken einbinden, damit der User zu bestimmten Textstellen springen kann. Diese sind möglicherweise ebenfalls Teil des Google-Suchergebnisses – eine Win-win-Situation!
Nutzer lieben ausklappbare Texte, denn sie ermöglichen eine schnelle Navigation und Übersicht deiner Website. Gerade auf den mobilen Endgeräten ist das von großer Bedeutung. Wichtige Inhalte sollten jedoch gut sichtbar sein. Bezüglich der Schriftart und -farbe musst du ein paar Sachen berücksichtigen:
Herkömmliche Browser müssen deine Schriftart darstellen können
Nutzer müssen deine Schrift gut lesen können
Schriftfarbe ungleich der Hintergrundfarbe verwenden
Technisch: Den Text nicht über „display:none“ verstecken
Die Länge ist alles (oder doch nicht?)
Bezüglich der Textlänge gibt es keine allgemeine Regel. Stattdessen musst du dich in deine Zielgruppe hineinversetzen und überlegen: „Warum sucht der Nutzer danach? Möchte er Informationen bekommen oder nur eine Transaktion abschließen?“ Denn dein Text sollte so lang wie nötig, aber so kurz wie möglich sein. Das heißt, du musst die Suchanfrage deines Nutzers bestmöglich beantworten, ohne den Text künstlich durch Phrasen etc. zu verlängern [4].
Videos sind nicht gleich Videos
Das Ranking pushen durch Videos
Videos können dein Ranking ebenfalls pushen, wenn du weißt wie. Hier ein paar Tipps und Tricks!
Das passende Storytelling
Jedes Video sollte dem Nutzer einen Mehrwert bieten, also inhaltlich wertvoll und aussagekräftig sein. Gestalte die Erzählweise spannend, damit der User lange auf dem Video verweilt, was bei Google und YouTube stark ins Ranking mit einfließt.
Videos zum Mitmachen
Feedback von den Zuschauern in Form von Kommentaren, positiven Bewertungen und Aufrufen wird von Suchmaschinen stark berücksichtigt, weil es einen Einblick in die Qualität und Relevanz des Filmchens gibt. Nichtsdestotrotz musst du dein Video auch aus technischer Sicht etwas aufpeppen, damit es gefunden und thematisch eingestuft werden kann.
Auch hier kommen Keywords zum Einsatz
Bereits zu Beginn solltest du ein Hauptkeyword festlegen. Dies ist dann der zentrale Begriff mit dem du im Ranking gegen Andere antrittst. Der Begriff sollte das Videothema dabei bestmöglich aufgreifen. Tipp: Vergleiche die Synonyme des Begriffs und achte dabei auf ihre Suchbeliebtheit, bzw. das sogenannte Suchvolumen. Das kannst du beispielsweise mit dem Google Keyword-Planner kostenfrei herausfinden.
Den richtigen Namen & Titel finden
Wie bei der Benennung anderer Inhalte ist es essenziell, dass sich der Name auf die Thematik des Videos bezieht und das Keyword enthält. Auch der Titel des Filmchens sollte das Hauptkeyword beherbergen, allerdings möglichst weit vorne, da es dann eine größere Relevanz hat. Beachte:
Der Titel sollte den Inhalt optimal benennen & Neugier wecken
Gestalte den Titel so kurz, wie möglich (max. 60 Zeichen)
Die Gestaltung der Description
Die Description, übersetzt Beschreibung, ist der begleitende Text deines Videos. Er ist am einfachsten zu indexieren und sollte aus mindestens 150-200 Zeichen bestehen. Nutze hier bitte ebenfalls Keywords! Die Reihenfolge spielt allerdings keine Rolle. Unterstütze dein Hauptkeyword durch Synonyme und Nebenkeywords, da es dadurch thematisch genauer eingeordnet werden kann.
Zusätzlich kannst du die Beschreibung dazu nutzen, um deine Ziele zu erreichen. So kannst du URLs in ihrer vollen Läge zu Beginn einbinden, damit die User diese möglichst anklicken. Auch Hashtags (#) können zum Beispiel bei YouTube eingebunden werden und dienen dann automatisch als Links zur Suchergebnisseite. Die Hashtagverwendung bringt folgende Tipps mit sich:
Die Hashtags müssen zum Inhalt passen
Nicht mehr als 15 Stück verwenden
Vor allem bei aktuellen Themen nutzen
Der erste Eindruck zählt – das Thumbnail
Das Vorschaubild muss so gestaltet sein, dass es den Nutzer neugierig auf den Inhalt des Videos macht. Dabei sollte es in Kombination mit dem Titel den Inhalt bzw. die Thematik ansprechend und bestmöglich veranschaulichen.
Videos überall
Internetseiten mit bewegtem Content erhalten bei Google eine größere Relevanz, als Seiten, die nur Text beinhalten. Deshalb bietet es sich an, eigene Videos auf der Website zu platzieren. YouTube kannst du in dem Fall gut als Hoster gebrauchen. Bestenfalls erscheinst du mit dem Video dadurch in den Google-Suchergebnissen mitsamt des Thumbnails. Folgendes kannst du zusätzlich machen:
Nutze zusätzliche Portale & Netzwerke, um Nutzer zu erreichen
Mache Werbung für dein Video über Social Media Kanäle
Es gibt auch die Möglichkeit des Erwerbs von Reichweite, indem du Geld investierst [5].
Content Marketing – eine moderne Disziplin
Die Contentoptimierung in Bezug auf Internetseiten ist mittlerweile ein großer Bestandteil im Arbeitsleben von vielen SEO-Spezialisten geworden. Zum Abschluss hast du hier einen kleinen Überblick, was hinter diesem riesigen Bereich genau steckt und warum das Content Marketing so wichtig ist.
Ein kleines Quiz – teste dich!
Viel Erfolg!
Ich hoffe, dass du mit Hilfe von diesem Beitrag deinem Traum, ganz oben in den Suchergebnissen bei Google zu sein, ein Stückchen näher gekommen bist. Natürlich gibt es keinen goldenen Weg, da sich Technologien fortwährend weiterentwickeln und verändern. Doch hab Geduld, die Arbeit lohnt sich!
4 Vgl. Dziki, Luisa (2018): How To: So schreibst du einen SEO-Text. Herausgegeben von: Seokratie GmbH. Zuletzt aktualisiert am 06.09.2018. Online unter https://www.seokratie.de/seo-texte-schreiben/ [Abruf am 27.05.2020]
5Vgl. how2 AG (2014): Videos selbst Optimieren: Die 10 wichtigsten Punkte für ein besseres Ranking auf Google und YouTube. Zuletzt aktualisiert am 07.09.2014. Online unter https://how2.expert/blog/erklaervideo-video-seo.html [Abruf am 27.05.2020]
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Sommersemester 2020, Andre Kreutzmann) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Was ein Video ist muss ich dir wohl nicht mehr erklären. Bewegte Bilder gibt es durch die Erfindung des Fernsehers bereits viele Jahrzehnte. Videos sind hingegen erst durch das Internet sehr populär geworden. YouTube hat dabei selbstverständlich eine riesige Rolle gespielt.
Bewegte Bilder wurden zunächst live übertragen und durch Videos schließlich auch vorgefertigt aufgezeichnet. Die Technik hat sich durch höhere Auflösungen und bessere Farben etc. deutlich verbessert, aber gab es wirklich revolutionäre Veränderungen für den Zuschauer? Wir sitzen vor dem Bildschirm und gucken nur zu. An der Technik haben wir doch schon so viel getan, warum nicht auch dem Zuschauer neue Funktionen geben? Bist du auch davon gelangweilt die Geschehnisse einfach hinzunehmen? Dann sind interaktive Videos genau das Richtige für dich.
Wenn dir jemand mehr Kontrolle geben will, würdest du es ablehnen?
Interaktive Videos animieren den Nutzern Interaktion durchzuführen und ermöglichen somit Kontrolle über den Inhalt. Somit werden diese Art von Videos nicht passiv konsumiert – ganz im Gegenteil: Du als Zuschauer nimmst eine aktive Rolle ein und beeinflusst den Inhalt. Obwohl diese Videos schon seit Jahren existieren, sind sie immer noch kaum verbreitet.[1]
Einsatzmöglichkeiten
Diese Technik kann in vielen Bereichen eingesetzt werden.
Beispiele:
Lehre
Werbung
Entertainment
Vorteile von interaktiven Videos
Die Marketingagentur Room214 gibt mit ihrer Statistik an, dass die Click-Through-Rate bei interaktiven Videos bei 5-12 % liegt. Die üblichen Videos hingegen liegen bei nur 1-2 %. Außerdem wurden sie zu 90% vollständig angeschaut. Normale Videos wurden hingegen zu 50% – 85% komplett angeschaut. Ein weiterer Vorteil ist, dass die Anzahl der Aufrufe steigt. Dies kommt zustande, weil verschiedene Szenarien auswählbar sind und die Neugier der Zuschauer somit steigt. Sie wollen nämlich wissen, wie das Video ausgeht, wenn sie einen alternativen Pfad auswählen.
Einsatz in der Lehre
Die Technik hat vor allem in der Lehre sein Nutzen. Es ermöglicht über interaktive Punkte die Aufmerksamkeit zu fokussieren. Dadurch können die Inhalte des Videos vertieft werden.
„Diese interaktiven Punkte erlauben es, die Aufmerksamkeit der lernenden Person auf eine bestimmte Sequenz oder ein bestimmtes Detail des Videos zu lenken und tragen damit zum Verständnis des Videoinhalts bei. Auf diese Weise können die Lernenden das Maß an
Informationen regulieren und damit eine kognitive Überlastung vermeiden.“
Abb. 1.: Mehrwert von Videos und interaktiven Videos aus der Sicht von Lehrpersonen[3]
Vor allem für Lernende mit wenig Vorstellungskraft ist diese Technik somit besonders hilfreich!
Beispiele
Honda Presents The Other Side
Beim folgenden Video handelt es sich um eine Werbung von Honda. In diesem Video kannst du parallel zwei Geschichten erleben. Per Mausklick oder R-Taste kannst du entscheiden, welche Story du sehen möchtest.
360° Video New Lipton Magnificent Matcha Tea Takes You Inside the Cup
In diesem Fall dachte sich Lipton „Warum nicht mit einem 360° Video unseren Tee vermarkten?“. Diese Technik ermöglicht dir das Video aus verschiedenen Perspektiven zu sehen. Außerdem kannst du entscheiden, was du dir genauer anschauen möchtest.
Star Wars: Welche Farbe hat dein Lichtschwert?
Star Wars Fans aufgepasst, denn dieses Beispiel ist etwas Besonderes! Hierbei handelt es sich um eine Reihe von Videos die zusammen eine Interaktive Geschichte bilden. Du kannst nämlich am Ende des Videos selbst wählen, wie die Geschichte weitergeht. Dafür wirst du zu einem nicht gelisteten Video weitergeleitet. Am Ende erfährst du welche Farbe dein Lichtschwert hat.
Fazit
Interaktive Videos sind die Weiterentwicklung von Web Videos. Auch wenn die Technik noch nicht sehr verbreitet ist, zeigt sie sehr viel Potential für die Zukunft. Immer mehr Streamingdienste bieten bereits interaktive Titel an, denn die Nachfrage steigt. Video ohne Interaktionen mit dem Zuschauer können in naher Zukunft deutlich an Beliebtheit verlieren. Anbieter wie auch Nutzer profitieren von dieser Technik. Die Nutzung macht nicht nur Spaß, sondern hat viele Vorteile für beide Seiten. Eins ist klar, interaktive Videos werden das Internet revolutionieren!
Quellen
1 Pink University (2016): Interaktives Video in der Weiterbildung – Formate und Vorteile. Online unter [Abruf am 14.07.20]
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Sommersemester 2020, Andre Kreutzmann) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Einen Prototype in dem Designertool Figma zu erstellen ist eine sehr schnelle und einfache Sache. Vielleicht kennst du auch die Bezeichnung Klickdummy für Prototype. Wenn du mal Screens für eine App oder eine Webseite erstellst, kannst du einfach mit einem Klickdummy die User Experience und die User Journey darstellen. Aber wie funktioniert das Erstellen von einem Prototype mit Figma? Und was sind Figma und die User Journey überhaupt? Das und weitere spannende Informationen zu diesem Thema zeigen wir dir in dem folgenden Beitrag!
Fangen wir erst einmal mit Figma an. Figma ist ein Web-basiertes Programm, welches zum Designen von Screens für eine App oder Webseite gedacht ist. Vielleicht kennst du auch das Tool Sketch. Dort kannst du auch leicht und unkompliziert Designs erstellen, jedoch spätestens wenn man zu zweit an einem Projekt arbeitet, kann man sich dort schnell in die Quere kommen. Figma hingegen ermöglicht dir das Designen von Screens mit vier oder mehr Händen! Du fragst dich wie das gehen soll? In Figma können mehrere Designer gleichzeitig an ihrem eigenen Gerät und an derselben Datei arbeiten, ohne sich dabei zu stören.
Das Interface von Figma: Wer mit Figma arbeitet merkt schnell, dass das Interface dieses Tools von Designern für Designer entwickelt wurde. Aber auch für Anfänger ist das Bedienen der Software, nach ein paar Stunden Einarbeitung, kein großes Problem mehr. Die zahlreichen Shortcuts sind unserer Meinung nach unbezahlbar! Shortcuts? Das sind unzählige Tastenkombinationen für verschiedene Werkzeuge. Somit bleiben dir Klicks und Zeit erspart!
Schnell zum Ergebnis mit wenig Aufwand: Wie schon erwähnt ist Figma ein nutzerfreundliches Tool und du kannst den Umgang mit dem Programm schnell lernen. Aber kennst du das Problem, wenn du in einer großen Gruppe arbeitest und du immer alles hin und her schicken musst, um auf dem aktuellsten Stand zu bleiben? Und dann musst du auf das Dokument deines Gruppenmitglieds warten, um mit deiner Arbeit anfangen zu können. Tja, bei Figma kommt sich bei einer Gruppenarbeit keiner mehr in die Quere, denn jeder kann an seinem Gerät in der gemeinsamen Datei arbeiten! Wir finden das großartig, denn so kann jeder die Schritte des anderen verfolgen und dementsprechend seine Arbeit anpassen. Somit musst du nicht mehr auf die anderen warten, bis du mit deiner Aufgabe anfangen kannst.
Verknüpfungen: Jetzt fragst du dich sicherlich was Figma nicht kann? Figma ist ein Tool für die interaktive Gestaltung von Screens, hat aber auch seine Schwächen. Diese umgeht Figma mit Verknüpfungen zu anderen Tools, wie Sketch oder Photoshop. So kannst du ganz leicht Funktionen von anderen Programmen über Figma verwenden.
Für jeden und zu jeder Zeit verfügbar: Du verspürst mitten in der Nacht den Drang, an deinen Screens weiterzuarbeiten, aber dein Gerät liegt auf der Arbeit? Mit Figma kannst zu jederzeit und überall auf deine Dateien zugreifen, solange du einen Internetzugang und deine Zugangsdaten hast.
Immer aktuell sein: Das lästige Problem mit der Aktualität der Dateien ist mit Figma Geschichte. Kein ständiges Fragen mehr, welche Version die aktuellste ist, denn es gibt nur noch die eine Version, die online ist! Auch das selbstständige Speichern von Figma erleichtert deine Arbeit und Ergebnisse können nicht mehr verloren gehen. Perfekt, oder?!
Einen Prototype benötigst du dann, wenn du Funktionen und Sinn von bestimmten Buttons und Interaktionsmodulen zeigen möchtest. Du kannst einen Klickdummy auch für die Darstellung der User Journey, also der Weg, den der Nutzer in deiner App oder auf deiner Webseite beschreiten soll, zeigen[2].
Sowas ist dann nützlich, wenn du zum Beispiel die Screens deinem Auftraggeber vorstellen möchtest. Mit einem Klickdummy kann sich der Auftraggeber besser vorstellen, welche Funktionen ein Button auslöst, wenn der Nutzer darauf klickt. Außerdem ist so ein Prototype auch dann sinnvoll, wenn du deine Logik der User Experience überprüfen möchtest. Denn es kann schon mal vorkommen, dass man zum Beispiel vergisst, einen Zurück-Button einzubauen und der Nutzer nicht mehr den Weg nach Hause – also zur Home Seite – findet.
Tutorial: Wie erstelle ich einen Prototype in Figma?
Jetzt fragst du dich wie das gehen soll? Kein Problem, zu Beginn musst du dafür die Figma Datei öffnen. Wenn du dort noch keine Screens angelegt hast, machst du das jetzt erst einmal. Du wirst die Screens benötigen, welche du anschließend miteinander zu einem Prototype verbinden möchtest.
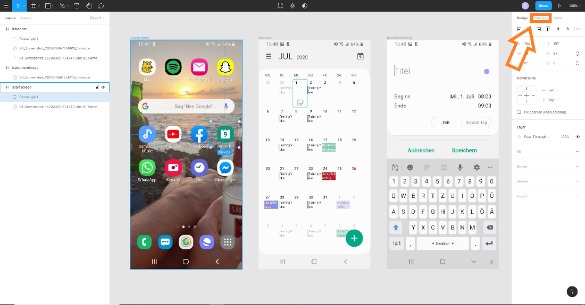
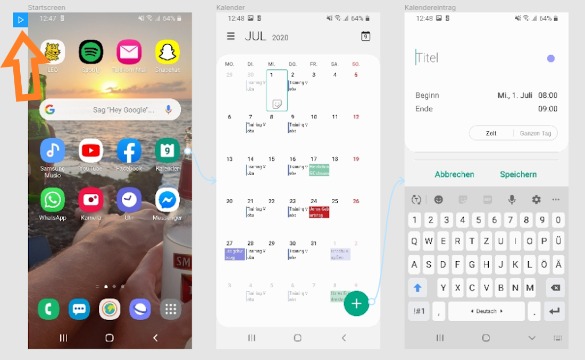
Schritt 1:
Hast du die Screenshots angelegt? Falls du mit ja antwortest, klickst du einfach oben rechts auf das Symbol Prototype. Du weißt nicht genau wo? Siehst du den orangen Pfeil im Screenshot? Er zeigt dir genau den Bereich, den du auswählen solltest. Der Prototype Bereich öffnet sich anschließend nach der Auswahl rechts in Figma (Schritt 1).
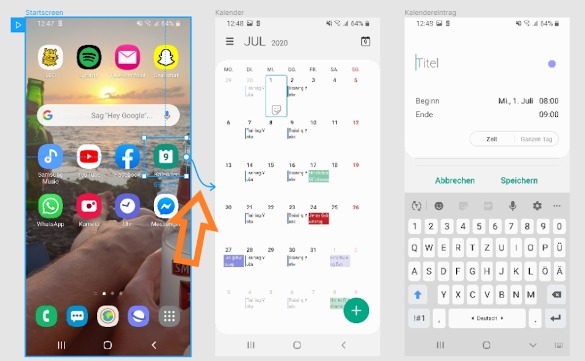
Nun siehst du um das ausgewählte Objekt herum den Umriss eines blauen Vierecks. Klicke auf den Punkt, der sich auf der rechten Kante des Vierecks befindet und halte dabei deine Maustaste gedrückt. Ziehe nun deine Maus auf den nächsten Screen, der danach angezeigt werden soll. Jetzt kannst du einen blauen Pfeil sehen, der von dem ausgewählten Objekt auf den nächsten Screen zeigt (Schritt 3).
In dem von uns dargestellten Beispiel, wählten wir die App Kalender von dem Screen Startscreen aus. Die Kalenderapp soll sich nun bei einem Klick oder Touch mit dem Finger öffnen, dies zeigt jetzt der blaue Pfeil, welcher auf den nächsten Screen Kalender zeigt.
Auf diese Art und Weise kannst du nun weitere Screens mit den vorherigen verbinden und so die User Journey des Nutzers in deiner App oder Webseite darstellen. Genauso kannst du ganz schnell und einfach einen Prototype in Figma erstellen!
Schritt 4:
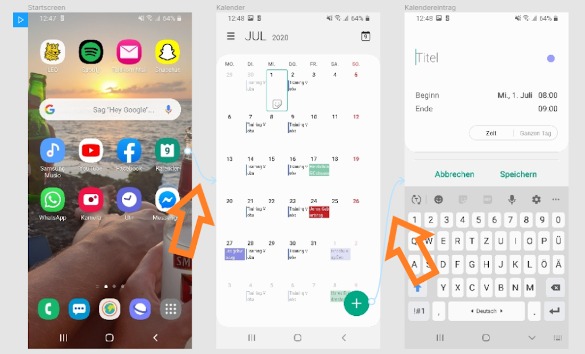
Pass dabei auf, dass du die richtigen Objekte mit den richtigen Screens zusammenführst. Sodass der Prototype die richtige, und von dir gewünschte, Reihenfolge anzeigt. Um die richtige Reihenfolge zu kontrollieren, kannst du dich an den blauen Pfeilen orientieren (Schritt 4).
In unserem Beispiel zeigen wir dir, dass wir vom Startscreen anfangen und auf das App-Symbol des Kalenders drücken. Daraufhin öffnet sich der Kalender, jetzt wollen wir einen Kalendereintrag hinzufügen. Dafür drücken wir auf das runde Plus-Icon und der Kalendereintrag öffnet sich.
Schritt 5:
Wenn du alle Schritte erfolgreich erledigt hast und die Pfeile soweit stimmen, ist es an der Zeit, den Klickdummy zu starten. Dafür klickst du einfach oben links, bei dem ersten Screen, auf das blaue Viereck mit dem weißen Dreieck (Schritt 5).
Daraufhin öffnet sich in einer neuen Datei der, von dir erstellte, Prototype. Jetzt kannst du auf die Objekte klicken, die du zuvor ausgewählt hast. Wenn daraufhin der nächste angezeigte Screen der Richtige ist, stimmt deine User Journey überein und der Prototype ist bereit für die Vorstellung bei deinem Auftraggeber!
Prototype erstellen – Alle Schritte auf einem Blick
Klicke auf Prototype oben rechts bei den Werkzeugtools.
Wähle das gewünschte Objekt, welches du in dem Prototype anklicken möchtest.
Klicke auf den Punkt innerhalb des blauen Vierecks und ziehe diesen zum gewünschten Screen.
Wiederhole jetzt die gleichen Schritte (Schritt 2) für die nächsten Screens.
Klicke oben rechts auf den Pfeil, um den Prototype zu starten.
Etwas hat nicht geklappt, oder hast du vielleicht einen Schritt vergessen? Keine Panik! Im folgenden Video Prototype / Klickdummy über Figma erstellenzeigen wir dir, die einzelnen Schritte per Desktopaufnahme.
Das Prototype-Testing mit Figma Mirror
Du kannst den Klickdummy und die User Journey auch mit der App Figma Mirror testen. Dies bringt dir den Vorteil, dass du deine erstellten Screens auch auf deinem Smartphone sehen kannst. So kannst du das Look and Feel deiner Screens auf deinem Smartphone bekommen. Auch die Größe von deinen Objekten und Texten kannst du so überprüfen.
Dafür brauchst du nur Figma Mirror aus dem Play Store oder dem App Store auf dein Smartphone/Tablet herunterladen. Anschließend meldest du dich mit deinen gewohnten Daten aus Figma an. Zu guter Letzt klickst du in deiner Arbeitsmappe auf den Startscreen deines Prototypes, dieser wird dir nun auf deinem Smartphone angezeigt. Jetzt kannst du auf deine ausgewählten Objekte tippen und so überprüfen, ob der darauffolgende Screen der Gewünschte ist und ob die User Journey mit der gezeigten Reihenfolge übereinstimmt.
Ein Tipp von uns: Wenn du die User Journey von einer App darstellen möchtest, nimm am besten dafür dein Smartphone. Möchtest du dir aber eine Webseite anschauen, welche noch nicht responsiv ist, verwende dafür lieber die App auf einem Tablet.
Wir hoffen, dass wir dir mit der Anleitung für die Erstellung eines Prototypes mit Figma helfen konnten und du damit deine User Journey darstellen kannst!
Quellen
Auf die [Hochzahl] klicken, um zum zugehörigen Absatz zurückzukehren.
1 Vgl. Ornella (2018): Designen mit vier Händen: 5 Gründe warum du Figma brauchst. Online unter [Abruf am 06.06.2020]
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Sommersemester 2020, Andre Kreutzmann) entstanden.
Die besten Tutorials stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Dir sagt es vielleicht nichts, aber Business Intelligence kann dich retten!
Das Scenario
Dein bester Freund/deine beste Freundin und du führen ein Unternehmen. Alles läuft gut. Der Umsatz stimmt, eure Angestellten sind klasse und du kannst sogar 3 mal im Jahr nach Malle fliegen. Doch dann kommt der Tag, an dem alles kippt.
Es trifft euch wie der Schlag!
Quelle: gifimage.net
Die Einnahmen brechen zusammen, die Kunden sind unzufrieden und der Kaffee im Büro schmeckt nach Fuß. Was ist passiert?
Nach einem Jahr bergauf, kam das Tal. Und das war tief. Euch war nicht bewusst, dass ein bisschen Nachdenken hilfreich sein könnte. Ihr habt den Überblick über euer Unternehmen verloren und alle eure Entscheidungen nach dem Erfolg eures Kick-offs waren Grütze.
Doch das muss nicht sein!
Auch wenn ihr nicht die intelligentesten seid, können es immerhin Eure Methoden sein. Business Intelligence (BI) ist das Stichwort. Doch was ist das und wie funktioniert das?
Business Intelligence in 6 Sätzen
Geschäftsanalytik – wie es auf deutsch heißt – ist eine technische und betriebswirtschaftliche Methode zur Entscheidungsfindung. Es ist die erweiterte Analyse des Unternehmens und seines Umfelds. Diese ist in den meisten Fällen von Tools gestützt. Das Ziel dabei ist „Wissensfindung“ oder auch „Knowledge Discovery“.[ 1 ] Denn bei diesen Analysen generierst du Wissen. Nicht nur fallspezifisch, sondern über dein ganzes Unternehmen und darüber hinaus.
Warum genau ist Business Intelligence nun so wichtig?
Um es kurz zu beantworten: BI-Tools können viel mehr gleichzeitig beachten, als du es jemals könntest.
Die längere Antwort:
Entscheidungen zu treffen ist keine leichte Aufgabe. Es ist schwierig. Aufgrund deines Bauchgefühls oder in Anbetracht weniger Faktoren diese zu fällen, ist gefährlich. Eine umfassende Analyse lohnt sich.
Zunächst scheint der Aufwand enorm. Ein Business Intelligence-Tool zu finden, zu bezahlen, aufzusetzen und zu pflegen kostet Zeit und Geld. – Das, was ihr gerade überhaupt nicht habt. – Aber sobald es läuft, kann es euch in so gut wie allen Bereichen helfen.
Es wird euch ermöglicht durch komplexe Zusammenhänge durchzusteigen. Und nachdem ihr diese verstanden habt, könnt ihr nicht nur reaktiv, sondern auch proaktiv handeln.[ 2 ]
Nicht überzeugt? Dann schau mal bei BI-SURVEY.com vorbei – vorsicht Englisch! Dort wird dir der Nutzen auf dem Silbertablett präsentiert.
Befragung zum Nutzen von Business intelligence-Tools in Unternehmen | Quelle: BARC (Business Application Research Center)
Die Grundlagen von Business Intelligence
Vier Schritte trennen Dich und deinen Kumpel/deine Kumpeline vom erneuten Erfolg.
Wie Du sehen kannst, hat BI viel mit Daten zu tun. Doch keine Angst, viel Arbeit kann dir abgenommen werden.
Daten Sammeln und aufbewahren
Grundlage für jede Analyse sind Daten. So ist es auch bei der Geschäftsanalytik. Je nach Ziel deiner Analyse brauchst du sowohl interne, als auch externe, Daten.
Bevor Ihr also mit Analysen beginnt, heißt es sammeln, sammeln und noch mehr sammeln!
Quelle: gifimage.net
Natürlich sammelt Ihr nur Daten, die euer Unternehmen oder euren Markt betreffen. Aber lasst euch nicht dazwischen funken! Denn Grundsatz ist: Je mehr Daten Ihr sammelt, desto mehr könnt Ihr am Ende auswerten.
Wenn Ihr Daten(-quellen) habt, müssen diese natürlich auch bewahrt werden. Dafür eignen sich Datenbanken beziehungsweise ein Data Warehouse. Sobald ihr genügend Daten zur Verfügung habt, könnt Ihr mit dem nächsten Schritt beginnen.
Business Intelligence-Tool wählen und Daten aufbereiten
Je mehr ihr euch mit einem bestimmten Business Intelligence-Tool auseinander setzt, desto schneller könnt ihr euch in die Arbeit mit diesem stürzen. Falls ihr bei eurer Entscheidung ein bisschen Hilfe braucht schaut bei Gartner vorbei! Deren jährlicher Report „Gartner Magic Quadrant for Analytics and Business Intelligence Platforms“ bietet euch einen umfassenden Überblick über den Markt.
Gartner Magic Quadrant für Analytics und Business Intelligence 2020 | Quelle: Gartner (Februar 2020)
Damit ihr die gesammelten Daten verwenden könnt, müsst ihr diese nun aufbereiten. Entweder ihr nutzt dazu das BI-Tool, für welches ihr euch entschieden habt oder ihr macht dies direkt an den Daten selbst. Letzteres kann jedoch schwierig sein. Insofern ihr also nicht darauf besteht an euren Daten direkt rumzupfuschen, lasst es!
Geschäftsrelevante Daten darstellen
Jetzt gehts ans eingemachte! Bevor ihr eure ersten qualifizierten Entscheidungen treffen könnt, müsst ihr die gesammelten und aufbereiteten Daten in einen Kontext bringen. Da kommt das Tool, aber auch euer Gehirnschmalz, ins Spiel. Auch wenn das Tool euch vieles abnimmt, müsst ihr überlegen, welche Verbindungen könnten für euch relevant sein und welche nicht. Das Tool stellt euch dann bspw. dar, wie stark die Verbindungen wirklich sind.
Was hängt zusammen? Was beeinflusst was? Es gibt Unmengen an Möglichkeiten der Darstellung. Probiert euch aus!
Indem ihr mit dem Tool arbeitet, gewinnt ihr an Verständnis für euer Unternehmen bzw. den Markt.
Und dann habt ihr es! Nachdem ihr nun Monate euer Unternehmen, die Mitarbeiter und den Markt analysiert habt, habt ihr es raus.
Euer Produkt ist Schrott!
Quelle: gifimage.net
Es besser machen, als es im Moment ist!
Nun heißt es: Alles besser machen. Das BI-Tool zaubert euch jetzt zwar keine Gelddruckmaschine ins Büro, aber es zeigt euch die Effektivität jeder Änderung im Detail.
Ihr kauft besseren Kaffee? Die Mitarbeiter werden produktiver. Ihr klaut Ideen bei der Konkurrenz und verkauft diese als eure? Eure Umsätze gehen hoch und die der Konkurrenz runter. Ihr landet im Gefängnis wegen Betriebsspionage? Doof, aber weil ihr das BI-Tool habt, kann sogar der Praktikant euer Unternehmen weiterführen.
Also was spricht jetzt noch gegen Business Intelligence in eurem Unternehmen?
Fazit
Natürlich ist das alles nicht so einfach, wie ich es jetzt dargestellt habe. Damit Business Intelligence wirklich gut funktioniert muss viel getan werden. Bis die oben aufgeführten Schritte alle durchgearbeitet sind, ist es ein weiter Weg.
Es dauert Monate, wenn nicht Jahre, bis Auswertungen über die Aussagekraft von simplen Analysen bzw. einem Blick auf eine Excel-Tabelle hinausgehen.
Doch es ist eine Investition in die Zukunft!
Quelle: makeameme.org
Je länger ihr mit einem solchem Tool arbeitet, desto umfassender wird der Nutzen.
Entscheidungen können, aufgrund von Daten, begründet werden. Der Überblick über alle Geschäftsbereiche wird zusammengeführt. Und ihr gewinnt immer mehr Nutzen aus den Daten, die in eurem Unternehmen über Jahre hinweg gesammelt wurden, aber nie genauer angesehen wurden.
Denn:
„There is significant hidden value locked away in corporate databases waiting to be discovered and exploited.“
– Loshin (2003, S.1)[ 3 ]
Quellen
Auf die [Hochzahl] klicken, um zum zugehörigen Absatz zurückzukehren.
[ 3 ] Loshin, David (2003) (Morgan Kaufmann Publishers), Business Intelligence: The Savvy Manager’s Guide, Getting Onboard with Emerging IT, Seite 1.
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Sommersemester 2020, Andre Kreutzmann) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Bestimmt bist du im Netz schon mal der Abkürzung PWA über den Weg gelaufen. Doch, wofür steht diese Abkürzung überhaupt? Was sind PWAs? Um es schnell auf den Punkt zu bringen: PWA steht für Progressive Web App. Jetzt bleibt nur noch die nächste Frage. Was sind Progressive Web Apps?
Im Rahmen dieses Beitrages erkläre ich dir die Grundlagen zum Thema PWAs. Am Ende dieses Beitrages erwartet dich ein Link zu einer Anleitung. Mit Hilfe dieser Anleitung kannst du dir im Handumdrehen eine eigene Progressive Web App erstellen. In relativ kurzer Zeit und ohne viel Aufwand kannst du erste Ergebnisse erzielen! Probier es doch mal aus.
Zunächst kämpfen wir uns durch ein bisschen Theorie. Wir schauen uns den technischen Aufbau und mögliche Funktionen von Progressive Web Apps an. Danach werfen wir einen kurzen Blick auf bereits erfolgreich umgesetzte PWAs. Zum Schluss zeige ich dir am Beispiel der Twitter PWA, wie du diese erfolgreich auf deinem Endgerät installierst.
PWA – Progressive Web App
Der technische Aufbau
Eine Progressive Web App besteht, wie viele Internetseiten heutzutage aus diesen drei wesentlichen Bestandteilen:
Auf Grundlage dieser drei Technologien, die eine unabhängige Plattform darstellen, sollen sich Web-Anwendungen an Zielgeräte so weit anpassen, dass die Nutzung möglich ist. [1]
In diesem Zusammenhang ist auch häufig die Rede von einem sogenannten „responsiven Design“ einer Webseite. Responsive Webdesign stellt eine aktuelle Technik zur Verfügung, welche es ermöglicht mit Hilfe von HTML5 und CSS3 Media-Queries das einheitliche Anzeigen von Inhalten auf einer Website zu gewährleisten. Hierbei wird das Layout einer Website so flexibel gestaltet, dass dieses auf dem Computer- Desktop, Tablet und Smartphone eine gleichbleibende Benutzerfreundlichkeit bietet. Somit kann der Inhalt gänzlich und schnell vom Besucher aufgenommen werden. [2]
Was macht eine Webseite zu einer Progressive Web App?
Progressive Web Apps sind, anders als normale Webseiten, auf dem jeweiligen Endgerät installierbar. Durch diesen Vorteil, bieten sie eine App-ähnliche Erfahrung, wie man sie bereits von Programmen auf einem Computer oder aus Apps aus dem Apple AppStore oder Google Play Store kennt. Das bedeutet auch, dass eine Progressive Web App in einem bestimmten Umfang auch „offline“, also ohne aktive Internetverbindung funktionieren kann. Somit kann eine PWA auch als eine Art Symbiose aus einer responsiven Webseite und einer App beschrieben werden.
Eine große Rolle spielt ebenfalls die Performance deiner PWA. Die Ladegeschwindigkeit und User Experience ist das A und O für den Erfolg.
Kurz zusammengefasst: Ausgehend von einer gemeinsamen Code-Basie, funktionieren PWAs auf allen möglichen Endgeräten in unterschiedlichsten Browsern. [3]
Sowohl die Browser Google Chrome, Firefox und Microsoft Edge, sowie Apples Safari unterstützen, Stand heute (26.07.2020), die Nutzung von Progressive Web Apps. [4]
Twitter – Eine erfolgreiche Progressive Web App
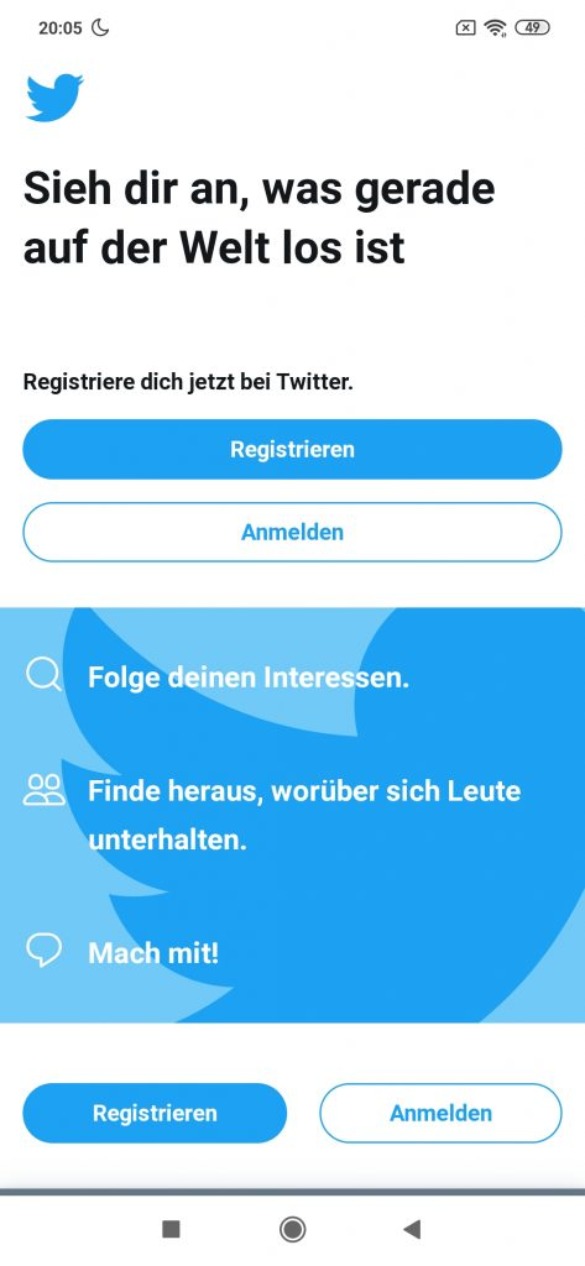
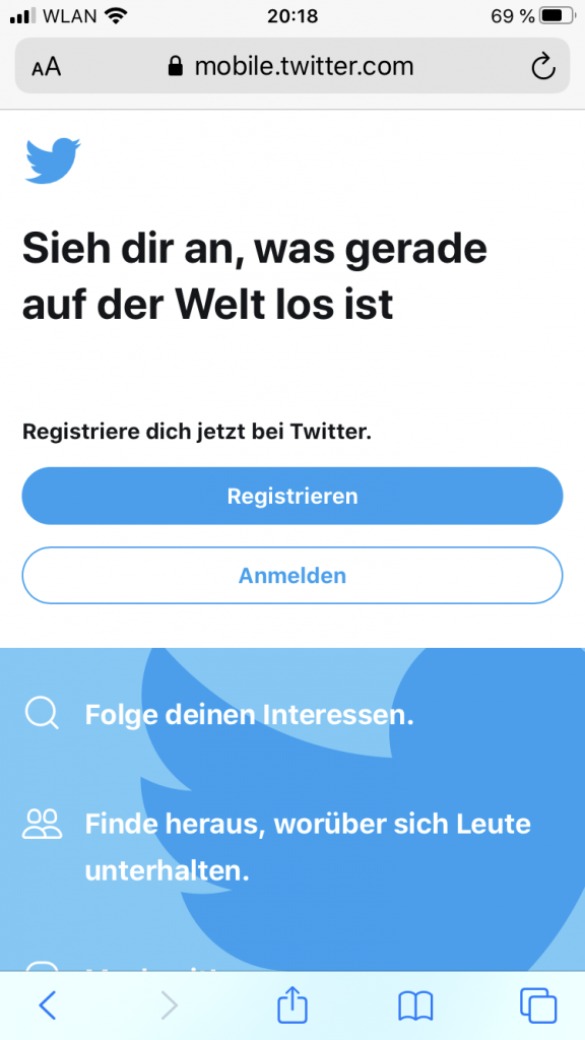
Als prominentes Beispiel für eine erfolgreiche Progressive Web App, kann ich dir die Twitter PWA empfehlen. Anstatt die App über den Google PlayStore oder Apple AppStore zu beziehen, kannst du auch einfach die PWA installieren. Über folgende Schritte bekommst du die schlanke App-Web-Version von Twitter über den Browser Google Chrome installiert:
Twitter PWA auf einem PC oder Laptop
Wenn du dich gerade am PC oder Laptop befindest, dann folge dieser Anleitung:
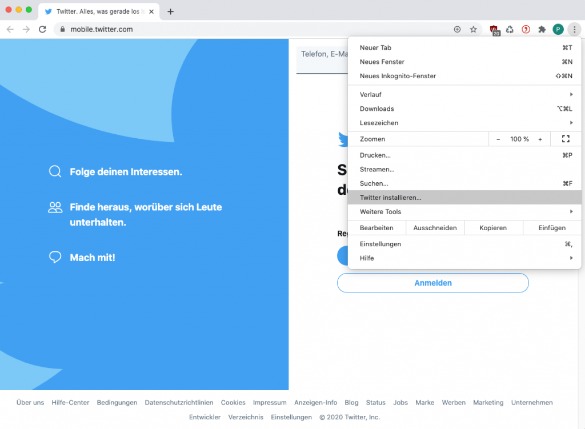
Rufe auf deinem Endgerät die Webseite www.twitter.com auf.
Nachdem du Schritt 1 durchgeführt hast, kannst du oben rechts auf die drei Punkte klicken.
Jetzt wählst du den Punkt: „Twitter installieren“ aus.
Insofern alles korrekt geklappt hat, kannst du die PWA nun über eine Verknüpfung auf dem Desktop/Schreibtisch starten.
Klicke oben rechts auf die drei Punkte und wähle „Twitter installieren“ aus:
Installierte Twitter PWA auf macOS in Google Chrome.
Twitter PWA auf einem Android Endgeräit installieren
Wenn du dich gerade an einem Android Smartphone befindest, dann folge dieser Anleitung:
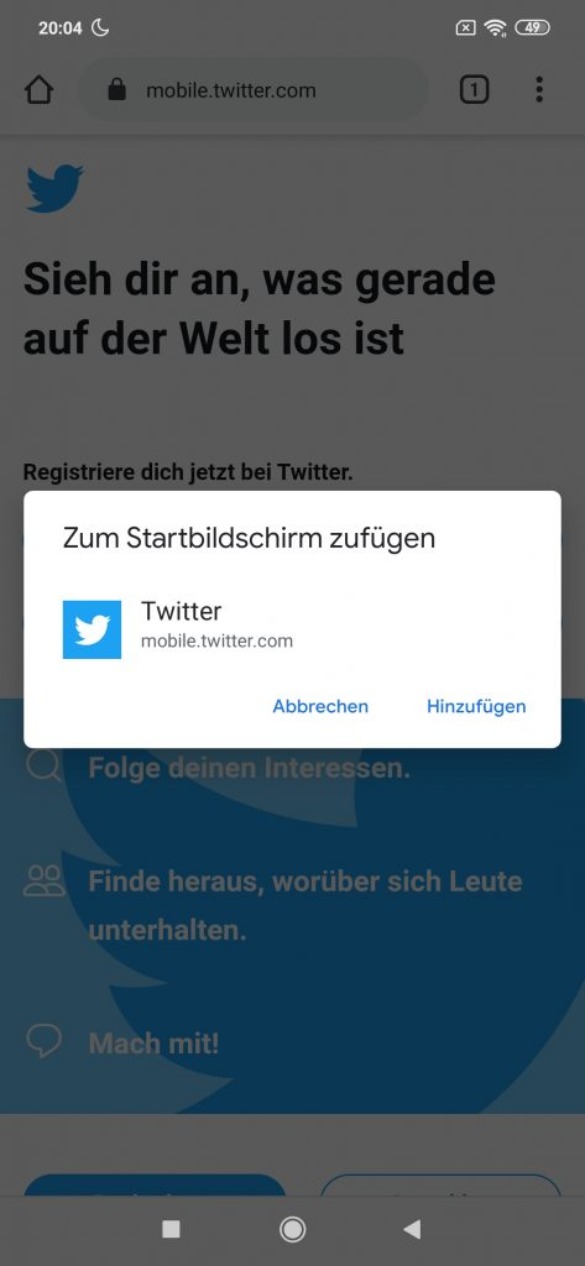
Rufe auf deinem Android-Endgerät die Webseite www.twitter.com auf.
Nachdem du Schritt 1 durchgeführt hast, kannst du oben rechts auf die drei Punkte klicken.
Jetzt wählst du den Punkt: „Zum Startbildschirm hinzufügen“ aus.
Installiere die Twitter PWA, indem du auf „Hinzufügen“ klickst.
Insofern alles korrekt geklappt hat, kannst du die PWA nun über eine Verknüpfung auf dem Homescreen starten.
Klicke auf „Zum Startbildschirm hinzufügen“
Klicke auf „hinzufügen“ und die PWA wird installiert
Die Twitter PWA ist nun installiert:
Installation der Twitter PWA auf einem Android Gerät mit Google Chrome. Bilder: Eigene Screenshots So sieht die geöffnete Twitter PWA auf einem Android aus.
Twitter PWA auf einem Apple Endgerät installieren
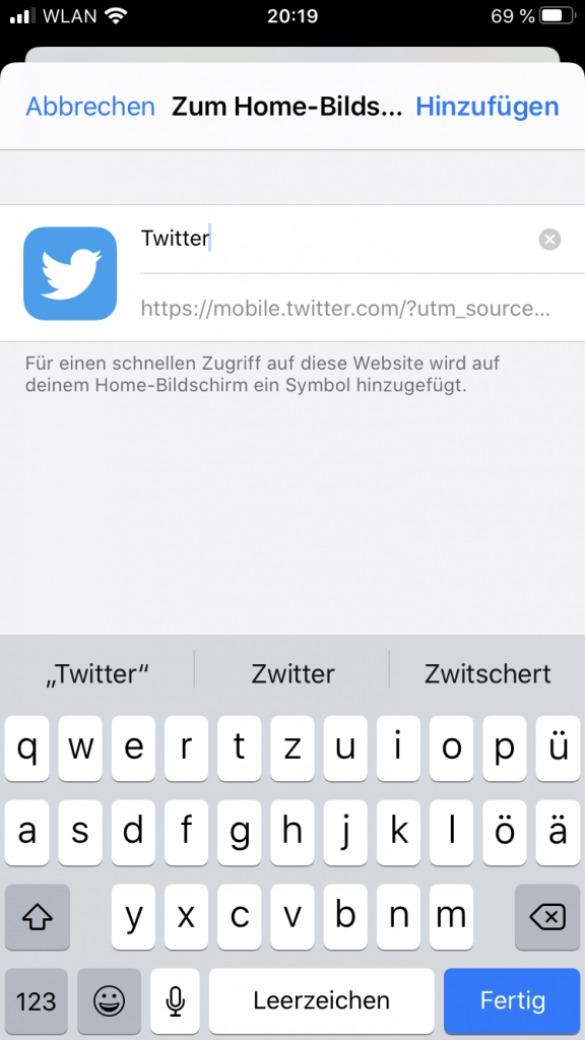
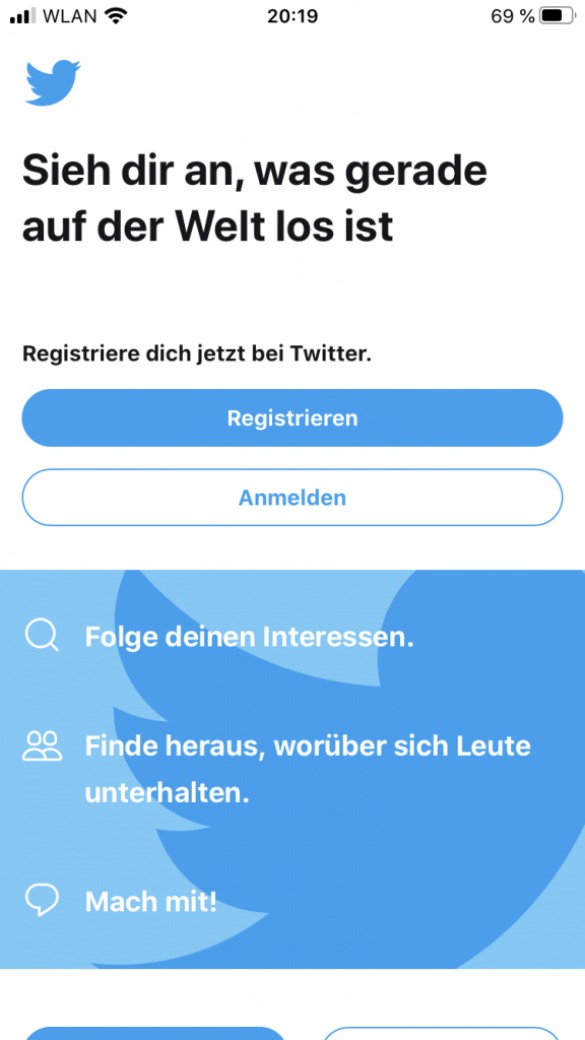
Wenn du dich gerade an einem Apple-Smartphone mit dem Safari Browser befindest, dann folge dieser Anleitung:
Rufe auf deinem Apple-Endgerät die Webseite www.twitter.com auf.
Nachdem du Schritt 1 durchgeführt hast, kannst du unten in der Mitte auf den „Teilen…“-Knopf klicken.
Als nächstes wählst du den Punkt: „Zum Home-Bildschirm“ aus.
Installiere die Twitter PWA, indem du auf „Hinzufügen“ klickst.
Insofern alles korrekt geklappt hat, kannst du die PWA nun über eine Verknüpfung auf dem Homescreen starten.
Klicke unten in der Mitte auf den „Teilen…“-Knopf
Klicke auf „Zum Home-Bildschirm“
Klicke auf „Hinzufügen“
Installation der Twitter PWA auf einem Appe iPhone mit Safari. Bilder: Eigene Screenshots So sieht die geöffnete Twitter PWA auf einem iPhone aus.
Probiere es gerne auf deinem eigenen Gerät aus!
Weitere Progressive Web Apps
Da es für PWAs keine Art AppStore oder PlayStore gibt, haben sich diverse Internetseiten mit der Sammlung von bekannten Progressive Web Apps beschäftigt.
Unter folgenden Links kannst du dir zahlreiche weitere PWAs anschauen:
Ich finde die Idee und die umfangreichen Einsatzzwecke von Progressive Web Apps enorm spannend. Die Möglichkeit seinen Webseitenbesuchern auf einfach Art und Weise eine App-Version seines Internetauftritts zur Verfügung zu stellen, bietet großes Potential.
Gerade die Kosteneinsparung bei der Entwicklung von „nur“ einer Webseite, die dann zusätzlich mit wenig Aufwand als App erscheinen kann, finde ich für Unternehmen sehr interessant. Solche Unternehmen, die PWAs einsetzen können mit einer höheren Verweildauer ihrer Kunden auf ihrer Webseite rechnen. Dies fördert zugleich die Conversion-Rate.
In Zukunft werden sicher mehr und mehr Unternehmen auf den erst kurzen Erfolgszug der Progressive Web Apps aufspringen. Die einzigen benachteiligten dürften hier der Google PlayStore und der Apple Appstore sein, da ihnen wohlmöglich ein gewisser Anteil In-App-Verkäufe weg brechen könnte.
Mich persönlich hat das Konzept einer PWA überzeugt und ich werde es bei einem meiner nächsten privaten Projekte auf jeden Fall in Betracht ziehen.
Literatur und Quellen
[ 1 ] Ruppert, Sven (2019): How-to: Progressive Web Apps praktisch erklärt. Online unter: https://entwickler.de/online/web/progressive-web-apps-tutorial-tipps-579830771.html [Abruf am 26.07.2020]
[ 2 ] wendweb GmbH (2020): Was ist Responsive Webdesign. Online unter: https://www.responsive-webdesign.mobi/was-ist-responsive-webdesign/ [Abruf am 26.07.2020]
[ 3 ] Google LLC (2020): Your First Progressive Web App. Online unter: https://codelabs.developers.google.com/codelabs/your-first-pwapp/#0 [Abruf am 26.07.2020]
[ 4 ] Vaadin Ltd. (2020): Progressive Web App Browser Support. Online unter: https://vaadin.com/pwa/learn/browser-support [Abruf am 26.07.2020]
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Sommersemester 2020, Andre Kreutzmann) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Ihr habt euch für die Webentwicklung entschieden – Glückwunsch. Ein Feld, so überlaufen wie kaum ein anderes. Hinter jeder Ecke wartet ein neues Projekt mit dem die Entwicklung einfacher, effektiver, schneller und sicherer sein soll. In dem Dschungel an Möglichkeiten ist es leicht, sich zu verirren. Deswegen stelle ich euch heute zwei der beliebtesten Frameworkes in Sachen Single-Page-Webanwendungen vor und vergleiche. React oder Angular (nicht zu verwechseln mit der Vorgängerversion AngularJS) – welches Framework passt am besten zu dir?
Der Beitrag in der Übersicht
Du kennst dich bereits aus? Dann spring doch gleich an die Stelle, die dich interessiert!
Single-Page-Applications, kurz SPA unterscheiden sich von herkömmlichen Webanwendungen insbesondere in einem Punkt – es gibt nur eine einzige HTML-Datei. Hierauf können Daten verändert und/oder dynamisch geladen werden. Die Verarbeitung ist somit client-seitig. Soll also beispielsweise etwas durch User-Interaktion geändert werden, wird keine neue HTML-Datei geladen, sondern die Datei client-seitig verändert.
Ablauf einer Webanwendung vs. SPA – Quelle: Selbst erstellt
Veranschaulicht seht ihr den Vorgang in dieser Grafik. Am Anfang arbeiten normale Webanwendungen genau wie SPAs. Die allererste Anfrage wird vom Client an den Server geschickt, welche mit einer HTML-Datei antwortet. Während sich bei der SPA diese niemals ändert, wird bei einer herkömmlichen Webanwendung dieser Vorgang wiederholt (sieht rote Pfeile). Findet eine neue Abfrage mittel POST statt, wird auch eine neue HTML-Datei von dem Server an den Client geschickt – und die Seite lädt neu. Bei SPAs (siehe grüne Pfeile) wird eine Anfrage mittels AJAX gesendet und mittels JSON wird die HTML Datei verändert.
Kein neues Laden, keine langen Wartezeiten. SPAs sind schneller und genau deshalb in der Webentwicklung immer beliebter.1 Nun aber zurück zu unseren SPAs Angular und React.
Angular & React – Was haben sie gemein?
Beide Plattformen sind Vorreiter in der Webentwicklung, genauer gesagt der Frontend-Entwicklung, da sowohl Angular, wie auch React eine Komponentenhierachie verwenden.
Kleiner Exkurs: Komponenten verwalten immer einen Teil einer View und können Unterkomponenten haben. Beide Projekte sind Open Source unter MIT Lizenz. Freier Zugang also. Auch auf die Community hinter beiden Plattformen könnt ihr euch verlassen.2 So glänzt insbesondere React mit inzwischen rund 149.000 Sternen auf Github. So gut wie jede Frage, die während der Entwicklung aufkommen wird, wurde bereits gefragt und beantwortet. Aber was zeichnet Angular und React aus? Und wer steht dahinter?
Wenn ihr einen schnellen Einblick über den Aufbau von Angular und React sucht, dann schaut am besten auf Stackblitz oder einer ähnlichen Seite vorbei. Dort könnt ihr ohne großen Aufwand ein Projekt mittels Angular oder React starten und euch mit den Strukturen vertraut machen, bevor ihr euch entscheidet.
Angular – Googles Framework 2.0
Hello World von Angular – Quelle: eigener Screenshot
So könnte auch euer erstes Projekt in Angular starten. Das Hello World der komplexen Ordnerstruktur von Angular.
Ihr fangt grade erst mit der Webentwicklung an und versteht schon jetzt die Welt nicht mehr? Ihr habt noch nie etwas von Angular gehört? Dann schaut dieses Video, in dem Angular simpel für Beginner erklärt wird und lest danach weiter. Angular ist ein Framework von Google, welches 2016 auf dem Markt erschienen ist, es ist also relativ „frisch“. Allerdings ist Angular kein Neuling, denn schon lange vor Angular gab es AngularJS. Die Vorgängerversion erschien bereits 2010. AngularJS und Angular sind nicht kompatibel, da Angular ein komplett neues Konzept vertritt und auch in einer neuen Sprache geschrieben ist – TypeScript. Diese Sprache wird auch in der Entwicklung mittels Angular verwendet.3
TypeScript? Aber ich kann doch nur JavaScript? Muss ich für Angular eine komplett neue Sprache lernen?
Keine Sorge, Angular ist für jeden verwendbar. Zwar empfiehlt das Team von Angular, TypeScript zu verwenden, aber auch reines JavaScript ist möglich. Die Chancen, die TypeScript bietet, sind aber nicht zu verachten. Und der Unterschied zwischen TypeScript und JavaScript ist gar nicht groß. Der Name sagt schon alles, was ihr Wissen müsst. TypeScript arbeitet mit Typen, erkennt, wenn falsche Typen deklariert werden – und warnt, was JavaScript allein nicht tut.4 Ein schneller Einstieg gelingt euch beispielsweise mit diesem Kurs.
Angular verwendet das Model-View-View Model. Sagt dir nichts? Macht nichts, im nachfolgenden Video wird es schnell und simpel erklärt.
React – Facebooks mächtige Bibliothek
Hello World von React – Quelle: eigener Screenshot
Simple Ordnerstrukturen, verwirrender Code. So beginnt das Hello World von React.
Ein großes Fragezeichen steht über euren Köpfen, wenn Ihr React hört? Dann schaut am besten dieses Video als fixen Einstieg.
React ist genaugenommen gar kein Framework, sondern nur eine JavaScript Bibliothek. Geschaffen 2011, von niemand anderem als Facebook, ist React wohl der beste Indikator dafür, dass eine einfache Bibliothek mächtiger sein kann, als man denkt. Der wichtigste Unterschied zu einem Framework ist, dass React sich einzig auf die View Ebene beschränkt. Zwar ist React relativ simpel aufgebaut, es lassen sich aber viele weitere Bibliotheken sehr einfach integrieren.5
Hinzu bietet React eine JavaScript-Syntax-Erweiterung mittels JSX, was vergleichbar mit XML ist. Aber wieso? Das Ziel von JSX ist es, das komplette User-Interface mittels einzelner Komponenten nachzubauen, um HTML in JavaScript zu integrieren. Richtig gehört, die Realität ist bei React einmal komplett verdreht worden. Standardgemäß wird nämlich JavaScript in HTML integriert. So wird nicht nur der Code übersichtlicher, sondern auch DOM-Manipulation fast unmöglich gemacht.6
Was solltest du wählen?
Viel Input, aber immer noch keine klare Empfehlung. Ich entschuldige mich – auch dafür, dass ihr vielleicht noch immer eine klare Empfehlung erwartet. Denn leider ist es nicht einfach zu sagen, zu wem React und zu wem Angular passt. Ein paar einfache Tipps kann ich euch aber mit auf den Weg geben.
Angular Logo – Quelle: angular.io
Angular gilt im allgemeinen als einsteigerfreundlicher, sowohl für Neulinge in der Web-Entwicklungswelt, als auch für Entwickler, die bereits Erfahrungen mit Java oder C++ gesammelt haben. Aber auch React hat viele Vorteile und ist nicht umsonst das beliebteste Framework, ohne überhaupt ein Framework zu sein.
React Logo – Quelle: reactjs.org
Ein Anreiz für React ist der Virtueller DOM, wodurch alles deutlich schneller wird, Angular kann hier nicht mithalten. Hinzu ist React auch bei kleineren Projekten gut geeignet, Angular wirkt dahingehend schnell überladen. Durch die schnell hinzufügbaren Bibliotheken ist React sehr flexibel und auch bei großer Interaktivität nützlich. Angular ist durch seine vielen vordefinierten Funktionen eher funktionabel als flexibel und bei geringer Interaktivität besser.7
React arbeitet mit JSX, was für Einsteiger abschreckend wirken kann. Oft kommt viel Code in einer Datei zusammen. Angular hingegen arbeitet mit HTML, erweitert mit Direktiven. React arbeitet mit dem One-Way-Binding, wodurch die Applikation schneller und flüssiger wird, aber insbesondere wird das Debuggen erleichtert. Angular arbeitet mit einem Double-Blind-Feature, wird also auf der einen Seite etwas verändert, verändert sich die andere Seite ohne, dass dafür etwas getan werden muss. So wird die Seite sehr schnell und responsiv, ein wichtiger Faktor.8
Angulars größter Anreiz ist wohl das, was viele Neulinge auf den ersten Blick abschreckt – TypeScript. Diese Sprache ist allerdings nicht mehr aufzuhalten und wird immer mehr verwendet. Sie ist relativ schnell zu lernen und öffnet viele neue Möglichkeiten. Wenn nicht jetzt, wann dann?
React oder Angular? And the winner is …
Auf wen fällt meine Wahl? Das wird wohl immer davon abhängen, was ich mit meiner Single-Page-Webanwendung erreichen will und wie. Arbeite ich allein oder im Team? Wie ist die Vorerfahrung von jedem einzelnen und wie die Vorlieben? Was ist das Ziel des Projekts?
5 Österle, Jonas (2017): React — Eine Einführung in fünf Minuten. Online unter https://medium.com/brickmakers/react-eine-einf%C3%BChrung-in-f%C3%BCnf-minuten-515dc38ceb73 [Abruf am 12.05.2020]
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Sommersemester 2020, Andre Kreutzmann) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Die Idee der Animation ist, ein erheiterndes, kleines Visual Graphic Novel zu erstellen, durch das der User mit visuellen Effekten durchgeführt wird.
Das Ziel ist, den User von Anfang bis Ende durch mehrere kleine Animationen zu führen, während er Interaktionen ausführt und Feedback zu den ausgeführten Aktionen erhält. Das Feedback besteht ebenfalls aus visuellen Effekten, sodass der User jederzeit weiß, wo und in welcher Ebene er sich befindet.
Die Führung durch das Visual Graphic Novel erfolgt visuell durch verschieden aufleuchtende Buttons. Durch sich farblich (türkis) abgrenzende Umrandungen der Buttons wird der User zu den gewünschten Aktionen gelotst, da diese am meisten auffallen (über Bewegung und Farbe).
Das Visual Graphic Novel besteht aus zwei Szenen, die der Nutzer frei wählen kann. Die Reihenfolge der Auswahl hat dabei keine Auswirkungen.
Die erste Ebene, der Startbildschirm, dient dem User dazu, das Visual Graphic Novel zu starten.
Auf der zweiten Ebene kann der User eine Szene (Home- oder Outdoor-Szene) auswählen, ohne jedoch das Szenenbild vorher zu sehen. Hier liest er nur den Text der Entscheidungsmöglichkeiten, was auch einen kleinen Überraschungseffekt bei der Auswahl geben soll.
Auf der dritten Ebene kann der User dann zwischen den beiden Szenen hin und her springen, so oft er möchte. Um das ganze unterhaltsamer zu machen, spricht die Figur einen Text. Die Sprechblase wiederholt sich hierbei unendlich oft, sodass der User den Text gut lesen kann, ungeachtete der Lesegeschwindigkeit.
Die vierte Ebene ist der Endbildschirm, wo sich ein „Thanks for playing“ (DE: „Danke für das Spielen“) bei dem User verabschiedet. Auf dieser Ebene hat der User die Möglichkeit, das Visual Graphic Novel erneut zu starten.
Verwendete Programmiersprachen:
Die ganze Animation wurde auf Codepen erstellt. Für die Erstellung der einzelnen Animation/-en wurden verwendet:
Die Besonderheiten bei dem Visual Graphic Novel sind klein, haben jedoch einen großen Effekt und Einfluss.
Zunächst ist das Design schlicht gehalten, bzw. der Hintergrund und die Hauptfarbe der Buttons. Dadurch wird die Aufmerksamkeit des Users auf die Szenen(-bilder) und die einzelnen, visuellen Effekte gelenkt.
Die Effekte der Klasse ‚hint‚
Die Klasse ‚hint‘ hat das Ziel, den User durch das Visual Graphic Novel zu führen. Der visuelle Effekt ist ein türkis-farbenes Pulsieren (in CSS definiert). Beim Startbildschirm (Ebene 1) wird die Aufmerksamkeit des Users somit vor allem auf den Start-Button gelenkt. Danach (Ebene 2) wird der Effekt „verschoben“ und ist nun nur auf der Szenen-Auswahl zu sehen, damit der User weiß, dass er sich nun für eine der beiden Optionen entscheiden soll. Ist nun eine Szene ausgewählt (Ebene 3), wird der pulsierende Farb-Effekt auf die nicht ausgewählte Option verschoben, sowie den Stop-Button. Damit weiß der User zum Einen, dass die andere Option noch ausgewählt werden kann, und zum Anderen, dass jederzeit das Spiel nun beendet werden kann. Wird nun auf den Stop-Button geklickt, wird der Farb-Effekt erneut auf den Start-Button geschoben, damit der User nun die Möglichkeit erkennt, erneut auf Start zu klicken. Die Steuerung, wann der Farb-Effekt, bzw. die Klasse ‚hint‘ wo hin verschoben werden soll, wird mit Hilfe der Buttons in JavaScript festgelegt. Der Effekt selbst wird mit CSS erstellt, mehr dazu unter dem Abschnitt Visuelle Effekte.
Die Figur und Objekte
Die Figur ist nicht nur eine Dekoration, sondern erfüllt auch einen Zweck: Ein Feedback an den User. Das Feedback ist simpel: Wurde sich nun für eine Szene entschieden, taucht eine Sprechblase von der Figur auf. Damit wird dem User gezeigt, dass die Szenen-Auswahl durchgeführt wurde und etwas passiert ist. Dabei wird der gesprochene Text in der Sprechblase unendlich oft wiederholt, damit der User jederzeit den Text erneut und so oft er will lesen kann. Des Weiteren erheitert der gesprochene Text der Figur (hoffentlich!) den User und hinterlässt somit einen positiven Eindruck. Die Figur wird in CSS mit der Klasse ‚figure‘ definiert.
Die anderen Objekte / Graphiken dienen hier der Dekoration und erhöhen den Spaß-Effekt beim Umschalten der Szenen.
Der Wegweiser
Der Wegweiser (eine SVG-Graphik), der einzig allein in Ebene 2 auftaucht, besitzt eine wichtige Funktion: Das Wegweisen. Da Graphiken, bzw. Bilder, meist mehr für sich sprechen als Text, wird dem User vor dem Lesen der Optionen bereits gezeigt, dass nun eine Entscheidung auf ihn zukommt. Ein Wegweiser ist hierbei ein allgemein bekanntes Symbol, dass von dem User nicht falsch verstanden werden kann, und dabei schneller auffällt als der Text in den Optionen. Der Wegweiser wird mit der ID ‚#signpost‘ in CSS definiert und mit Hilfe von JavaScript gesteuert. Mehr dazu unter dem Abschnitt Buttons & Option.
Grundbausteine
Da es in dem Visual Graphic Novel viele verschiedene Elemente gibt, die von JavaScript gesteuert werden und auf verschiedenen Instanzen auftauchen sollen, schließen verschiedene div-Container diese ein.
Im ‚body‘ wird alles Wichtige wie background-size, background-color, sowie die Inhaltsplatzierung innerhalb des ‚bodys‘ und die Schriftart definiert. Die border- und box-shadow-Einstellungen schaffen hierbei eine Abgrenzung von dem restlichen Browserfenster und begrenzen die Darstellungsoberfläche des Visual Graphic Novels.
Der div-Container mit der Klasse ‚main-content‘ ist dafür da, um den gesamten Inhalt (also alle Graphiken) als eine Einheit zu platzieren und sie durch JavaScript und JQuery zu steuern, d.h. einen Start-Bildschirm zu erschaffen. Damit kann der gesamte Inhalt in ‚main-content‚ mit einem Klick aus- und eingeblendet werden, wenn einer der Buttons gedrückt wird. Das geschieht dadurch, dass dieser Klasse eine Id ‚gamestop‘ und ‚gamestart‘ (definiert in CSS) mit der Eigenschaft ‚visibility:hidden‘ zugewiesen und wieder entfernt wird.
<!-- die Id wird in JS genutzt, um einen Startbildschirm zu erschaffen --!>
<div id="gamestart" class="main-content"> <!-- wird genutzt, um den main-content zu steuern und zu positionieren -->
Der div-Container ‚illustration‘ enthält alle Graphiken, bzw. SVG-Graphiken, und fixiert diese. Da nicht alle SVG-Graphiken eine geeignete Proportionalität besitzen, um zusammen dargestellt zu werden, hilft das Fixieren auch dabei, um sie gegenseitig aufeinander abzustimmen.
Person-type: Home-Body & Outdoor-Person
<div class="person-type home-body active"> <!-- hier ist die home-scene mit dazugehörigen Objekten -->
<div class="scenery">
<img src="https://image.freepik.com/free-vector/living-room-interior-with-panoramic-window-night-time_33099-1735.jpg" class="backgroundimg"/>
</div>
<div class="background.items">
<img src="https://image.flaticon.com/icons/svg/214/214283.svg" width="100px" height="400px"/>
</div>
<div class="foreground-items">
>img src="http://image.flatcon.com/icons/svg/198/198916.svg" width="65px" style="margin-left:-10%"/>
<img src="Http://image.flaticon.com/icons/svg/3145/3145435.svg" width="65px" style="padding-left:30%;"/>
</div>
</div>
Mit der Klasse ‚person-type‚ werden in CSS alle Kindelemente dieser Klasse definiert und in JavaScript zwischen den Szenen hin- und hergewechselt, wenn die jeweilige Option ausgewählt wird.
.person-type > div {
transform: scale(0);
opacity:0;
}
.person-type.active > div {
transform: scale(1);
opacity: 1;
Durch ‚person-type > div‘ werden alle Kindelemente der Klasse ‚person-type‚ ausgewählt. Es gibt ‚person-type‚ einmal für die Home-Szene (inklusive der dazugehörigen Graphiken) und dann für die Outdoor-Szene. Wenn eine der Szenen ausgewählt wird, wird diese Szene durch ‚person-type.active‘ (definiert in CSS) nach „vorne geschoben„‚(transform:scale (1))‘ und durch ‚opacity:1‘ sichtbar gemacht. Die andere Szene wird durch ‚person-type > div‘ nach „hinten geschoben„ ‚(transform:scale(0))‘ und mit ‚opacity:0‘ unsichtbar gemacht. Dadurch können beide Szenen an den gleichen Platz im Container geschoben werden, ohne dass sie sich gegenseitig verdrängen. Die Szenenauswahl wird durch den Button mit JavaScript ausgelöst. Darauf wird später in Buttons & Option noch mehr eingegangen.
Container Scenery & Backgroundimg
Der div-Container ’scenery‘ umfasst das Szenenbild (für jeweils die Home- und Outdoor-Szene). Mit dieser Klasse wird der Einblendungseffekt / Übergangseffekt beim Szenenwechsel in CSS mit ‚transition:‘ definiert.
Der div-Container ‚backgroundimg‘ wird in CSS definiert und erfüllt den Zweck, die Hintergrundbilder der Szenen auf die gleiche Größe zu skalieren und dem Bild mit ‚border-radius‘ und ‚box-shadow‘ eine Form und einen visuellen Tiefen-Effekt zu geben.
.scenery 7
transition: all 200ms cubic-bezier(0.68, -0.55, 0.265, 1.55);
z-index: -2;
0/* Styled die Hintergrundbilder der Scenen */
.backgroundimg7
border-radius:50%;
margin-left:-73%;
width:626px;
height: 3356px;
box-shadow: 0px 0px 15px #000000;
Der ‚foreground-items‘ div-Container beinhaltet die Graphiken, die sich in den beiden Szenen jeweils weiter vorne befinden und bei einem Szenenwechsel später eingeblendet werden als die Graphik im Hintergrund und das Hintergrundbild.
Mit ‚transition:‘ wird der Einblendungseffekt / Übergangseffekt dieser Objekte beim Szenenwechsel festgelegt.
Background-items Container
Der div-Container mit der Klasse „background-items“ beinhaltet die eine Graphik (jeweils in beiden Szenen), die zu einem früheren Zeitpunkt als die Graphiken in dem ‚foreground-items container‘ in der ausgewählten Szene auftauchen. Dies ist in CSS mit ‚transition:‘ definiert, wie in der folgenden Abbildung zu sehen ist.
Der div-Container ‚option-wrapper‘ beinhaltet beide Szenen-Optionen und umschließt diese, damit sie zusammen in einem Button erscheinen können. Außerdem wird mit dieser Klasse der div-Container per JavaScript „anvisiert“, bzw. mit einem Leuchteffekt versehen, damit dieser zum geeigneten Augenblick die Aufmerksamkeit des Users bekommt. Zu den Buttons unter Buttons und zu dem Leucht-Effekt unter Visuelle Effekte mehr.
<div class="option-wrapper">
<aclass="option active wobble-vertical-on-hover homeoption hint" data-option="home">
I'm gonna read a nice book and stay in. </a>
<a class="option wobble-vertical-on-hover outdooroption hint" data-option="outdoor">
I'm gonna explore the wide world and beyond! </a>
</div>
Buttons & Option
Die Klasse ‚option‘ ist allen Buttons zugeteilt. Also jeweils dem Start- und Stop-Button sowie beiden Szenen-Optionen. Die Klasse ‚option‘ regelt mit ‚transition:‘ in CSS den Übergang der ausgewählten Option sowie den Style der einzelnen Optionen. Somit grenzen sich z.B. die Outdoor-Szene und Home-Szene innerhalb des ‚Option-Wrappers‘ voneinander ab und erscheinen als zwei eigene Buttons. Mit ‚cursor‘ wird zudem der Cursor über dem Button definiert.
Die Klasse ‚active‘ definiert, wie die ausgewählte Option aussieht. Durch die Klasse ‚active‘ verändert sich die Hintergrundfarbe und Schriftfarbe des Buttons (gelber Hintergrund, schwarze Schrift), wenn dieser angeklickt wird.
Bei der Szenenauswahl wird der ‚person-type‘ der jeweiligen Option angesprochen, der bei beiden Szenen unterschiedlich ist und in der JavaScript-Funktion jeweils definiert ist, bzw. welche Elemente dazugehören. Der Wechsel der Optionen, sowie die Zuweisung der Klasse ‚active‘, geschieht mit folgender Funktion in JavaScript:
$(".option").on("click", function() {
$(".person-type").removeClass(active");
$(".option").removeClass("active");
$(this).addClass("active");
var type = $(this).data("option");
console.log($(type));
Die beiden Person-Types (‚data-option‘ in HTML) der Optionen, also ‚person-type home‘ und ‚person-type outdoor‘ in JavaScript, bestimmen, welche weiteren Grafiken / Objekte dargestellt werden. Dies ist definiert als if und else if (untere Abbildung) in der Funktion „click“, (obere Abbildung). Wird also die ‚option‘ mit dem ‚type == „home“‚ (in HTML data-option) angeklickt, wird der Klasse ‚home-body‘ die Klasse ‚active‘ zugewiesen. Desweiteren werden damit alle benötigten Elemente für diese Szene eingeblendet, sowie nicht benötigte ausgeblendet, mit folgender Funktion:
setTimeout(function() {
if (type === "home") {
$(".home-body").addClass("active");
$("#signpost").css({"visibility": "hidden"});
$("#bubbletoggle1").css({"visibility": "visible"});
// Hier der Wechsel der Sprachblasen
$(".bubble2").hidden();
$(".bubble1").show();
$".stop-button").addClass("hint");
$(".homeoption").removeClass("hint");
}
<div class="option-wrapper ">
<a class="option active wobble-vertical-on-hover homeoption hint" data-option="home">
I'm gonna read a nice book and stay in.</a>
<a class="option wobble-vertical-on-hover outdooroption hint" data-option="outdoor">
I'm gonna explore the wide world and beyond! </a>
</div>
Der ‚Signpost‘ ist eine Grafik, die in Ebene 2 eingeblendet wird, hier jedoch ausgeblendet werden soll. Mit der Klasse ‚hint‘ wird eine farbliche (türkis-farbene) Umrandung um den Stop-Button gesetzt, damit der User darauf aufmerksam gemacht wird, dass er das Visual Graphic Novel ab jetzt beenden kann. Gleichzeitig wird diese Klasse der jetzt ausgewählten Option entzogen, da die Aufmerksamkeit des Users bereits auf diesem Button liegt. Die ID ‚#bubbletoggle1‘ ist in einem anderen Abschnitt erklärt.
Der Start- und Stop-Button
Der Start- und Stop-Button dient dazu, einen Start-Bildschirm und einen End-Bildschirm zu erschaffen, sowie dem User die Möglichkeit zu geben, dass Visual Graphic Novel jederzeit zu verlassen. Dazu wird den beiden Buttons die Klasse ‚active‘ gegeben, damit diese genauso wie die Szenen-Options reagieren (weiter oben beschrieben). Ebenso wird zum Zwecke der User-Lenkung und User-Aufmerksamkeit die Klasse ‚hint‘ vergeben, die farbliche Effekte (türkis-farbene Umrandung) vergibt.
Der Style der beiden Buttons wird in CSS festgelegt. Dafür wird die Klasse ‚buttons‘ vergeben. Der Zweck der Klasse ‚hint‘ wird im Abschnitt ‚Besonderheiten‘ und die CSS-Definition unter Visuelle Effekte mehr erläutert.
.button{
display: flex;
position: center;
margin:0en auto;
background: rgba(255,255,255,0.25);
border-radius: 50px;
padding: 5px;
max-width: 300px;
font-size: 15px;
line-height: 1.2;
} /* Wird genutzt, um per JS zu steuern, wann der Inhalt auftaucht, wenn die buttons gedrückt werden*/
#gamestart{
visibility:hidden;
}
#gamestop{
visibility:hidden;
}/* Danke-Text am Ende des Spiels */
Die ID ‚#gamestart{visibility:hidden;}‘ und ‚#gamestop{visibility:hidden;}‘ werden in JavaScript dafür verwendet, um beim Klicken der Buttons den ‚main-content‘ einzublenden und beim Drücken des Stop-Buttons den ‚main-content‘ auszublenden. Zur Übersichtlichkeit der Steuerung in JavaScript wurden also die beiden ID’s jeweils einzeln in CSS definiert, obwohl sie die gleichen Attributwerte besitzen. Die beiden Funktionen für den Start-Button und den Stop-Button sehen wie folgt aus:
$(".star-button").on("click", function() {
$(".main-content").removeAttr("id", "gamestart");
$(".thanks").css({"visibility": "hidden"});
$("#signpost").css({"visibility": "visible"});
// "hint" gibt dem User Hinweise, wo hingeklickt werde
$(".button").removeClass("hint");
$(".start-button").removeClass("hint");
$(".option-wrapper").addClass("hint");
});
//Funktion und eizelne Aktionen, die ausgeführt werde
$(".stop-button").on("click", function() {
$(".mnain-content").attr("id", "gamestop");
$(".bubble").hide();
$("#signpost").removeAttr("style", "visible");
$(".thanks").css({"visibility": "visible"});
$(".button").addClass("hint");
// wenn der stop-button geklickt wird, muss das lightni
$(".stop-button").removeClass("hint");
//hiermit wird die Klasse "hint" den beiden Scenen-Opt
$(".homeoption").addClass("hint");
$(":outdooroption").addClass("hint");
});
Die beiden Funktionen definieren auch, was beim Drücken des Buttons eingeblendet und ausgeblendet werden soll. Dies geschieht durch die Klassen und ID’s, die in CSS definiert sind (wenige Ausnahmen befinden sich als Attributwert in HTML).
Sprechblase
Die Sprechblase der Figur in beiden Szenen hat jeweils einen verschiedenen Text. Aus diesem Grund wurden einmal die Klassen ‚bubble1‘, ‚bubbletoggle1‘, ‚bubble2‘, ‚bubbletoggle2‘ vergeben und an beide jeweils die Klassen ‚bubble‘ und ‚anim-typewriter‘.
<div id="bubbletoggle1" class="buble1" style="visibility:hidden;">
<a lass="bubble bubble1 anim-typewriter "> Ah! That was a good desicion! Now a nice cup of tea...would you set the kettle on? </a>
</div>
<div id="bubbletoggle2" class="bubble2" style="visibilioty:hidden;">
<a class="bubble bubble2 anim-typewriter">What a lovely day, isn't it? Ans such charming strangeers visiting!</a>
</div>
Die Klasse bubble
Die Klasse ‚bubble‘ ist dafür da, um die Sprechblase per CSS zu stylen. Die CSS-Attributwerte von ‚min-width‘, ‚max-width‘, ‚max-height‘ sind hierbei besonders wichtig, da sie bestimmen, wie groß die Sprechblase werden kann, wenn der Text auftaucht. Je nachdem, wie lang der Text ist, muss natürlich auch die ‚min-width‘, ‚max-width‘ und ‚max-height‘ angepasst werden. Wäre ‚max-height‘ in diesem Fall kleiner als die festgelegten ’50px‘, würde nicht der ganze Text auftauchen können.
Wichtig hierbei ist der Attributwert infinite, der leider etwas schwierig zu handhaben ist. Darauf wird in „bubbletoggle: Der unendliche Text“ weiter eingegangen.
Die Klassen bubble1 und bubble2
Die Klassen ‚bubble1‘ und ‚bubble2‘ werden in JavaScript verwendet, um die jeweilige Sprechblase in der richtigen Szene einzublenden und auszublenden. Die Klasse ‚bubble1‘ ist hierbei für die Home-Szene, ‚bubble2‘ für die Outdoor-Szene. Aus- und eingeblendet wird die Klasse in JavaScript mit ‚$(.bubble1).hide()‘ und ‚$(.bubble1).show()‘. Da beide Szenen auch unterschiedlich helle Hintergründe haben, wird mit dieser Klasse in CSS auch die Farbe der Sprechblasen angepasst.
Eigene Abbildung: Der unendliche Text der Sprechblase
Der Text in den Sprechblasen wird unendlich wiederholt, um dem User das Lesen zu ermöglichen und zu vereinfachen, wann auch immer die Szene ausgewählt wird und unabhängig davon, wie schnell die Lesegeschwindigkeit des Users ist. Die Klassen ‚bubbletoggle1‘ und ‚bubbletoggle2‘ werden dafür verwendet, um den Text der Sprechblasen durch JavaScript (und CSS) in HTML mit ‚visibility:hidden‘ und ‚visibility:visible‘ unsichtbar und sichtbar zu machen. Dies ist sehr ähnlich wie das, was die Klassen ‚bubble‘ und ‚bubble1‘ (oder bubble2) schon machen. Hierbei gibt es aber ein Problem:Unendlich heißt unendlich. Die einzige Möglichkeit in diesem Fall, den sich unendlich wiederholenden Text in der Sprechblase unsichtbar zu machen, ist über eine extra ID und ein dazugehöriger Style-Attributwert in HTML, der in JavaScript gezielt angesprochen wird. Damit wird keine andere Klasse beeinflusst oder verändert, was später zu Komplikationen führen könnte. In JavaScript sieht das dann folgendermaßen aus: $(„bubbletoggle1″).css({visibility:“visible“}); für die Home-Szene und für die Outdoor-Szene $(„#bubbletoggle2“).css({„visibility:“visible“}); . In dem Abschnitt Buttons ist die gesamte Funktion erklärt und zu sehen.
<div id="bubbletoggle1" class="bubble1" style="visibility:hidden;">
<a class="bubble bubble1 anim-typewriter ">Ah! That was a good decision! Now a nice cup of tea...would you set the kettle on?</a>
</div>
<div id="bubbletoggle2" class="bubble2" style="visibility:hidden;">
<a class="bubble bubble2 anim-typewriter">What a lovely day, isn't it? And such charming strangers visiting!</a>
</div>
Visuelle Effekte
Die Klasse hint
Eigene Abbildung: Klasse hint beim Start-Button und Stop-Button
Die User-Lenkung durch die Klasse ‚hint‘ wurde vom Zweck und der Funktion her im Abschnitt Besonderheiten erläutert. Der Licht-Pulse-Effekt wird in CSS erstellt und definiert.
Die Dauer der Animation ist mit ‚-webkit-animation-duration:2s;‘ festgelegt. Der Farbwechsel (oder auch die Intensität) im Verlauf der Animation ist durch die ‚@-webkit-keyframes hintpulse‘ definiert. Dabei wurden verschiedene Abstufungen des original Farbtons für die Intensität verwendet.
Der Wobble-Effekt
Der Wobble-Effekt wird durch die Klasse ‚wobble-vertical-on-hover‘ in CSS definiert. Beim Hovern über ein Element mit dieser Klasse „wobbelt“ jenes. Damit weiß der User, dass mit diesem Element interagiert werden kann. Die Definition und Animation ist in CSS festgelegt.
Mit der Klasse ‚wobble-vertical-on-hover‘ und zusätzlich ‚:hover‘, ‚:focus‘, ‚:active‘ wird festgelegt, dass sowohl beim hover, als auch so lange die Maus darauf ist der Effekt gilt. Mit ‚animation-iteration-count:infinite‘ wird dieser Effekt so lange wiederholt, bis weder ‚hover‘,’active‘ noch ‚focus‘ für dieses Element gilt, bzw. es dadurch nicht mehr ausgelöst wird. Mit ‚@keyframes wobble-vertical-on-hover‘ wird die Bewegung nach oben und unten definiert/ festgelegt; also die Vektoren, wo sich das Element mit dieser Klasse an einem bestimmten Prozent(-punkt) der Bewegung befinden muss.
Und nun sind alle wichtigen Code-Abschnitte erklärt. Falls das Interesse an dem Quellcode (inklusive Kommentare darin!) vorhanden ist, muss nur wieder nach zum Seitenanfang gesprungen, die ZIP-Datei heruntergeladen und entpackt werden!
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Entwicklung von Multimediasystemen (Sommersemester 2020, Amy Linh Hoang, Prof. Dr.-Ing. Steinberg) entstanden. Verwendete Techniken sind HTML5, CSS3 und JavaScript.
Die besten Tutorials stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Die Nutzerverfolgung im Internet durch die Verwendung von Browsercookies ist gängige Praxis, doch haben diverse datenschutzrechtliche Entwicklungen der letzten Jahre zugunsten der Verbraucher diese Form des Trackings in vielerlei Hinsicht eingeschränkt und auch die Usability von Websites maßgeblich beeinträchtigt. Um weiterhin eine Personalisierung von Werbung und anderen Inhalten unter Wahrung der Nutzbarkeit und Rechte der Nutzer zu gewährleisten, ist es unausweichlich, eine neue Methode zur Identifizierung von Besuchern zu etablieren. Das Ziel dieser Arbeit ist, verschiedene Trackingtechnologien unter Berücksichtigung gegebener Rahmenbedingungen im Rechtsraum der Europäischen Union in ihrer Funktionsweise zu vergleichen und die nach derzeitigem Stand realistische Nachfolgetechnologie zum Tracking via Cookies zu benennen – Fingerprinting. Dieses überzeugt in Bezug auf seine Langlebigkeit und rechtliche Vereinbarkeit, den Implementierungsaufwand sowie den Umfang der sammelbaren Daten. Darauf aufbauend ist eine statistische Untersuchung zur Verbreitung von Methoden aus dem Feld des Fingerprintings auf den meistgenutzten Internetseiten durchgeführt worden. Dabei ergibt sich, dass Informationen, die zur Erstellung eines Fingerprints genutzt werden können, von fast allen Websites abgefragt werden, jedoch durchschnittlich nur wenige verschiedene Arten von Fingerprints genutzt werden. Auf einigen Websites werden durch größere dritte Unternehmen Fingerprints erfasst, der Opt-in-Status hingegen hat in den meisten Fällen für die Praktizierung von Fingerprinting keine Relevanz. Da Fingerprinting auch für schädliche Zwecke, zum Beispiel das Verteilen von potenterer Schadsoftware, verwendet werden kann, ist die Reaktion von Browserentwicklern und -nutzern auf die Entwicklung von derzeitigen und zukünftigen Fingerprintingkonzepten ungewiss, und auch die rechtliche Lage der nächste Jahre hängt von angekündigten Verordnungen ab, die in ihrem Inhalt noch nicht bekannt sind.
Die Bachelorarbeit von Valentin wurde vorbildlich über SerWisS veröffentlicht und ist als Volltext zu finden unter:
SEO. Vielleicht bist auch du über diesen Begriff gestolpert, aber wusstest nie was er bedeutet. In diesem Beitrag versuche ich es dir mal zu erklären. Stell dir vor du würdest nach Informationen für deine Präsentation im Internet suchen. Wahrscheinlich suchst du dafür in Google so wie es die Mehrheit tut. Dazu gibst du deine Suchanfrage in die Suchmaschine ein und erhältst innerhalb weniger Sekunden eine Überflutung an Webseiten. Die Ergebnisse sind dann auf mehreren Seiten verteilt. Bestimmt ergeht es dir wie den meisten und du klickst die ersten Ergebnisse an. Doch wie schaffen es genau diese Webseiten auf den ersten Seiten einer Suchmaschine zu erscheinen? Dafür ist SEO verantwortlich. Aber was ist denn nun SEO? Und wie funktioniert es? Das erfährst du hier.
SEO ist die Abkürzung für Search Engine Optimization, zu Deutsch Suchmaschinenoptimierung. Es ist ein Teil des Suchmaschinenmarketings und wird für das Online Marketing angewendet. Dabei stehen das Erzielen von Umsatz, Steigerung der Popularität und der Besucherzahl sowie die Erhöhung der Reichweite im Fokus. Bei SEO werden Maßnahmen ergriffen, damit Webseiten und deren Inhalte in Suchmaschinen besser aufgefunden und als eine der ersten Treffer (Ranking) platziert werden. Dies gilt nicht nur für Webseiten, sondern auch für Bilder und Videos [4]. Hierfür werden verschiedene Rankingfaktoren beachtet und nach denen optimiert.
Steigerung der Reichweite
SEO wird in zwei Bereiche unterteilt: In die Onpage Optimierung und in die Offpage Optimierung. Im Folgenden wird zunächst auf die Onpage Optimierung und danach auf die Offpage Optimierung näher eingegangen
Onpage Optimierung
Unter Onpage Optimierung versteht man Maßnahmen der Suchmaschinenoptimierung, die auf der eigenen Webseite vorgenommen werden. Hierbei sollen die Faktoren Technik, Inhalt und Strukturder Webseite nach Suchmaschinenkriterien verbessert werden. In der Regel sind das Faktoren für Google [2]. „Ziel der Onpage Optimierung ist es vor allem, ein möglichst gutes Ranking in Suchmaschinen zu erreichen“ [8].
Rankingfaktoren der Onpage Optimierung
In diesem Abschnitt werden ein paar Beispiele für Rankingfaktoren aufgelistet.
Rankingfaktor Inhalt
„Einzigartige, aktuelle und hochwertige Inhalte beeinflussen diverse Rankingfaktoren und sind der Schlüssel zu einer hohen Kundenzufriedenheit“ [8]. Sie steigern die Verweildauer und senken die Absprungsrate [8]. Um guten Inhalt zu verfassen, muss man sich in die Sicht des Nutzers hineinversetzen. Daher müssen folgende Fragen beantwortet werden: Löst der Inhalt ein Problem? Ist er individuell gestaltet und geschrieben? Unterscheidet er sich zu anderen Webseiten? Wird überhaupt nach dem Problem gesucht?
Zu dem Inhalt zählt ebenfalls wie dieser strukturiert ist. Die Verwendung aussagekräftiger Überschriftenspielt hierbei eine große Rolle. Als Hauptüberschrift der Webseite muss eine H1 Überschrift verwendet werden. Für Überschriften der zweiten Ordnung die H2 Überschrift und so weiter. Ebenfalls sollte der Text gut lesbar sein. Komplizierte Satzstruktur und Rechtschreibfehler sollten vermieden werden. Ebenfalls erleichtern Absätzedem Nutzer das Lesen. Des Weiteren muss auf die Formatierunggeachtet werden. Wenn sie nötig ist, sollte sie eingesetzt werden wie z.B. bei Aufzählungen oder Tabellen. Ebenfalls ist für die Orientierung ein Inhaltsverzeichnis von Vorteil. Als positiv gewertet wird auch das Einbinden einer Interaktionsmöglichkeit. Das weckt das Interesse des Nutzers und bindet ihn in den Inhalt ein. Dies kann dazu führen, dass der Text somit verständlicher ist. Beispiele für Interaktionsmöglichkeiten sind ein Quiz am Ende des Textes oder freie Felder für Kommentare [9].
Für das Auffinden der Webseite müssen Keywords eingesetzt werden, die man bei der Suchanfrage verwenden würde. Diese müssen möglichst häufig im Text vorkommen. Dies gilt ebenfalls für die URL, bei der der Besucher sofort weiß, auf welcher Webseite er sich befindet und wovon diese handelt.
Damit sich die Verweildauer der Besucher erhöht, ist es gut Multimedia Elemente, wie Bilder oder Videos, auf deine Webseite zu platzieren [2]. Bei Bildern müssen einige Kriterien beachtet werden. Bilder müssen komprimiert und auf die richtige Größe zugeschnitten werden. Bei der Bildbenennung sollten Keywords sowohl im Titel als auch im Dateinamen enthalten sein. Hinzu kommt das Nutzen von Titel und ALT-Attributen, um das Bild zusätzlich zu beschreiben [9].
Rankingfaktor Technik
Die Inhalte deiner Webseite müssen gut lesbar sein. Dies bedeutet, dass die Webseite an mobile Endgeräte angepasst werdenmuss. Dazu zählen z.B. Handys und Tablets. Ebenso muss der Zugang zur Webseite gewährleistet sein (Barrierefreiheit). Weiterhin ist eine hohe Ladegeschwindigkeit wichtig, damit der Besucher auf der Webseite verweilt [2].
Studien haben gezeigt, dass die durchschnittliche Wartezeit beim Laden einer Webseite 3 Sekunden beträgt [1]. Also immer daran denken!Ebenfalls muss man an die Nutzerfreundlichkeit der Webseite denken. Das bedeutet jeder muss sich auf der Webseite gut zurechtfinden. Eine gute Navigation muss gegeben sein.
Des Weiteren helfen Interne Verlinkungen innerhalb einer Webseite nicht nur bei dem Zurechtfinden, sondern auch zur Nachverfolgung, wo man sich aktuell befindet. Dies kann man durch eine verlinkte Menüführung, Links zu Unterseiten oder Breadcrumbs erreichen. Breadcrumbs ist eine Unternavigation, die zur Orientierung dient. Dabei wird ein Pfad von Seiten angezeigt, die man durchklicken muss, um auf die aktuelle Seite zu gelangen. Solche Breadcrumbs wirken sich im Suchmaschinenranking bei Google positiv aus.
Je schneller ein Besucher die benötigte Seite auf einer Webseite erreicht, desto besser. Dies bedeutet, wenn der Benutzer durch wenig Durchklicken an sein Ziel kommt, wirkt es sich positiv auf das Ranking aus. Das heißt durch wenig Deep Links gelangt der User an sein Ziel [2].
⇒ „Richtwert: von der Homepage zur Zielseite in drei Klicks“[2].
Rankingfaktor Struktur
HTML Kenntnisse sind hier von Vorteil. Das Nutzen von Tagsund Überschriften sowie die Strukturierung des Textes fließen in das Ranking mit ein [2]. Ebenso ist das Einsetzen von Meta-Tags wichtig. Hierzu ein paar Beispiele:
Verwendung von Keywords im Title Tag, das als Seitenbenennung und Überschrift in Suchergebnissen dient, vermittelt dem Nutzer den Inhalt der Seite
Zum Ranking zählt ebenfalls die Beschreibung des Inhalts durch das Einsetzen von Meta-Description Tags
Ein weiteres Beispiel ist die Benennung von Bildern durch das (IMG)Title Tag. Dies erleichtert Google das Verstehen des Bildinhalts
Der Tag kann auch für Verlinkungen verwendet werden [8].
Bisher war die Rede nur von Onpage Optimierung. Dabei gibt es einen zweiten Bereich von SEO: Die Offpage Optimierung. Was ist denn nun der Unterschied zwischen den beiden Bereichen? Der Unterschied liegt bei den Maßnahmen der Optimierung. Hierbei werden Maßnahmen ergriffen, die außerhalb der eigenen Webseite stattfinden. Ein weiterer Unterschied ist, dass im Gegensatz zu der Onpage Optimierung, die Offpage Optimierung nicht aktiv beeinflussbar ist.
Wird eine Webseite mehrmals verlinkt und von anderen Webseiten empfohlen, signalisiert das der Suchmaschine, dass der Inhalt einer Webseite gut sein muss. Die mehrfachen Verlinkungen sind so genannte Backlinks. Wenn eine Webseite mehrere Backlinks erhält, entsteht eine externe Verlinkungsstruktur. Aus diesem Grund steigt die Reichweite und der Bekanntheitsgrad. Dies ist das Hauptziel von Offpage Optimierung. Doch wie veranlasst man nun am besten die Bildung von Backlinks?
Methoden der Offpage Optimierung
Persönliche Kontakte
Wenn man Kontakte hat, die selber Webseitenbetreiber sind oder Webseitenbetreiber im Bekanntenkreis haben, kann man sie fragen, ob sie die Webseite verlinken [2].
Linkbuilding
Beim Linkbuilding soll eine Website so viele Backlinks wie möglich erhalten. Vor allem gut für das Ranking ist es, wenn die Website organisch die Backlinks aufbaut. Das signalisiert der Suchmaschine, dass die Nutzer gerne und von selbst die Seite aufgrund ihres Inhalts verlinken. Gekaufte Backlinks werden von Google erkannt und können abgestraft werden. Ebenso wirken sich der Linktext, die Linkposition und die Anzahl der Links von einer Quelle auf die Stärke der Verknüpfung aus. Nach diesen Faktoren wertet Google die Stärke der Verknüpfung aus [11]. Ein guter Trick für die Erzeugung von Backlinks ist, wenn man selbst Verlinkungen von anderen Webseiten auf seiner eigenen Webseite setzt. Die Webseitenbetreiber können das sehen und einen auf der eigenen Webseite zurück verlinken [2]. Hier ein paar Beispiele für gute Backlink-Quellen: Social Media, Artikeltexte, Verzeichnisse, Kommentare und Foren [10].
Soziale Netzwerke
Verlinkungen in Kommentaren oder Posts auf verschiedenen sozialen Netzwerken, wie Instagram, Twitter, YouTube, können gute Backlinks einbringen [2]. Nutzer können mit den Inhalten interagieren und sorgen durch den viralen Effektdafür, dass sich dieser verbreitet und dadurch viele weitere Nutzer auf die Website aufmerksam werden [10]. „Ein hohes Suchvolumen nach einem Markennamen oder die häufige Erwähnung eines Unternehmens im Netz könnten darauf hindeuten, dass eine Marke über hohe Brand Awareness verfügt und bekannt ist. Zudem lassen sich viele Backlinks und eine hohe Aktivität sowie hohe Followerzahlen in Social Media als deutliche Hinweise auf eine erfolgreiche Marke anführen“ [11]. Diese „Social Signals“werden von Google positiv bewertet und fördern das Ranking der Website [10].
Social Media trägt einen großen Teil zu Verlinkungen bei. Um den oben genannten Punkt zu verdeutlichen zeigt diese Tabelle einen Ausschnitt der Anzahl der Nutzer von den meist genutzten sozialen Netzwerken (Stand: Januar 2019)[3].
Soziales Netzwerk
Userzahl
Facebook
2,27 Milliarden
YouTube
1,900 Milliarden
Instagram
1,000 Milliarden
Twitter
360 Millionen
Branchenbücher
Durch das Eintragen einer Webseite in Branchenbücher, wird dem Nutzer verholfen die Webseite online über die Branche zu finden. Somit können ebenfalls Backlinks erzeugt werden [2].
Eine kurze Zusammenfassung in Form einerInfografik verschafft dir einen besseren Überblick über die SEO Maßnahmen [5].
SEO und UX
SEO und die User Experience hängen miteinander zusammen und auch voneinander ab. Google kann mittlerweile die Inhalte der Webseiten semantisch erfassen und zuordnen. Ebenso kann die Suchmaschine die Bedienbarkeit einer Webseite bewerten. Dazu zählen z.B. versteckte Inhalte hinter Tabs, die man auf den ersten Blick nicht sieht. Jedoch erkennt Google solche Inhalte und kann sie dementsprechend positiv oder negativ bewerten. In Bezug auf die Rankingfaktoren von Google, zeigt sich ein Zusammenhang zwischen SEO und UX. Setzt man bestimmte Rankingfaktoren um, steigt die UX. Hier einige Beispiele:
Durch den Einsatz von HTTPS wird die Sicherheit der Seitenbesucher erhöht
Kurze Ladezeiten machen das Abrufen von Webseiten leichter
Durch Anpassung an mobile Endgeräte wird ein Abruf von Webseiten auf Smartphones und anderen Geräten ermöglicht
Webseiten, die wenig Werbung und viele hilfreichen Inhalten enthalten, helfen dem Nutzer das zu finden, wonach er sucht
Durch eine Einteilung der Webseite in Kategorien wird das Auffinden der Webseite erleichtert.
Je einfacher Google es hat, wie ein Nutzer die Webseite zu bedienen, desto besser ist die User Experience sowie die ergriffenen Maßnahmen von SEO. In Folge dessen steigt die Webseite im Ranking [12].
Fazit
Die Onpage- und Offpage Optimierung sind ein wichtiger Teil der Suchmaschinenoptimierung. Bei Onpage Optimierung dreht sich alles um das Auffinden einer Webseite in einer Suchmaschine (meistens Google), indem man die Webseite nach verschiedenen Rankingfaktoren optimiert. Das kann aktiv beeinflusst werden und passiert gezielt auf der Webseite. Technische, strukturelle und inhaltliche Aspekte zählen zu diesen Rankingfaktoren. Ein wesentlicher Vorteil der Onpage Optimierung ist die Erhöhung des Traffic der eigenen Webseite. Zudem dreht sich dabei alles um die Usability [8].
Zusätzlich zu der Onpage Optimierung hilft die Offpage Optimierung die Webseite und die eventuell damit verbundene Marke bekannt zu machen und die Reichweite zu steigern. Hierfür sind Backlinks für Google ein wichtiges Rankingkriterium. Insbesondere die Verlinkungen auf den sozialen Medien wirken sich auf das Ranking aus. Im Gegensatz zu der Onpage Optimierung ist die Offpage Optimierung nicht aktiv beeinflussbar ist. Hierfür spielen die Nutzer eine große Rolle. Sie interagieren mit den Inhalten und verbreiten diese viral. Dadurch werden weitere Nutzer auf die Webseite aufmerksam. Infolgedessen entscheiden und bewerten sie den Inhalt der Webseite und teilen diese. Entscheidend für das Verbreiten und somit das Erzeugen von Backlinks sind guter Content, Nutzerfreundlichkeit und starke Interaktion mit den Kunden/Nutzern. All dies sorgt für bessere SEO-Ergebnisse [11].
Quellenverzeichnis
1: Quietsch, Phillip (o. J.): Google Report: verschenktes Conversion-Potenzial durch lange mobile Ladezeiten. Online unter [Abruf am 04.12.2019]