Wie erleben sie die Corona-Auswirkungen im Studium? Wie funktioniert die Lehre? Und wie kommen beide persönlich damit zurecht? Antworten findet ihr im folgenden Videopodcast:
”Signals always point to something. In this sense, a signal is not a thing but a relationship. Data becomes useful knowledge of something that matters when it builds a bridge between a question and an answer. This connection is the signal.”
― Stephen Few, Signal: Understanding What Matters in a World of Noise[5]
Unter Data Mining versteht man einen Prozess, bei dem man mithilfe anspruchsvoller mathematischer und statistischer Algorithmen in großen Datenmengen nach Mustern, Trends und Zusammenhängen sucht.[1] Die Besonderheit des Data Mining ist die automatische Generierung der neuen Hypothesen aus den Datenmengen.[4] So kann man beispielsweise anhand der Verkaufsdaten untersuchen, ob und wann Kunden, die Produkt A gekauft haben, auch Produkt B kaufen.
Ziele der Untersuchung einer Datenmenge können unterschiedlich sein. Je nach Ziel gibt es im Data Mining dafür passende Aufgabenstellungen beziehungsweise -typen und dazugehörige Methoden. Typische Aufgabentypen sind Klassifikation, Regressionsanalyse, Assoziationsanalyse, Ausreißererkennung und Clusteranalyse. Darüber hinaus werden die Aufgabentypen des Data Mining oftmals nur in zwei Gruppen eingeteilt. Diese sind Beobachtungsprobleme (Clusteranalyse, Ausreißererkennung) und Prognoseprobleme (Klassifikation, Regressionsanalyse). [6]
Klassifikation
Die Objekte der vorhandenen Daten werden anhand ihrer Merkmale in Klassen zusammengefasst. Die dadurch gebildeten Klassenmengen dienen als Grundlage für die Entwicklung eines Klassifikationsmodells. Mit dem Klassifikationsmodell lässt sich nun die Klassenzugehörigkeit eines neuen Objekts automatisch vorhersagen.[2]
Regressionsanalyse
Die Regressionsanalyse basiert auf den Konzepten der Varianz und Kovarianz. Dies bedeutet, es wird nach Zusammenhängen beziehungsweise Abhängigkeiten zwischen Variablen gesucht. Meistens setzt man eine Regressionsanalyse bei Prognosen und Vorhersagen ein.[3]
So ist es möglich, aus den historischen Daten der Umsätze eines Kunden und seinem Wohnort eine Kennzahl zu ermitteln. Diese Kennzahl kann beispielsweise der zu erwartende Umsatz, den der Kunde in Zukunft einbringen wird, sein.[8]
Assoziationsanalyse
Bei der Assoziationsanalyse untersucht man die einzelnen Datensätze eines Datenbestandes auf Zusammenhänge, bei denen auf ein Ereignis konsequent ein anderes folgt. [8] Diese Zusammenhänge werden über Wenn-dann-Regeln beschrieben. Typischer Anwendungsbereich der Assoziationsanalyse ist die Untersuchung des Warenkorbes. Ein Beispiel dafür ist folgendes: Wenn ein Kunde Mehl kauft, dann kauft er wahrscheinlich auch die Butter. Die Assoziationsanalyse kann aber auch für die Untersuchung komplexerer Zusammenhänge benutzt werden. Etwa, in welchem Zeitabstand nach dem Kauf des Produktes A, der Kauf des Produktes B erfolgt. [1]
Ausreißererkennung
Ausreißer sind die Werte, die deutlich von den erwarteten Werten abweichen und gar nicht in die Messreihe passen. Sie können die Datenergebnisse stark verzerren und ungültig machen. Aus diesem Grund muss ein Datenbestand von den Ausreißern bereinigt werden. [3] Die Verfahren zur Analyse von Ausreißern sollen mithilfe der historischen Daten die Wahrscheinlichkeit ermitteln, mit der ein neuer Datensatz ein Ausreißer ist. Dieser soll dann entweder automatisch gelöscht oder zur manuellen Analyse gesammelt werden. [8]
Clusteranalyse
Die zentrale Aufgabe einer Clusteranalyse ist es, neue Kategorien bzw. Gruppen zu identifizieren. Denn im Gegensatz zu Klassenanalyse sind bei dieser Methode die Klassen nicht vorgegeben. Bei der Clusteranalyse werden große Datenmengen in kleinere Gruppen eingeteilt (siehe Abbildung 1). Die Mitglieder eines Clusters sollen möglichst ähnliche (homogen) Eigenschaften aufweisen. Die einzelnen Clusterkategorien sollen sich wiederum möglichst stark unterscheiden (heterogen).[7]
Da die Cluster ohne Vorwissen generiert werden, ist es nicht immer eindeutig, was die Cluster ähnlich macht und ob sie auch inhaltlich relevant sind. Für eine Aufklärung sind zusätzliche Analysen zuständig.[7]
Im folgenden Video sind weitere Informationen zum Thema Methoden beziehungsweise Aufgabentypen des Data Mining mit dazugehörigen Beispielen zu finden:
Fazit
Das Anwendungspotenzial des Data Mining ist vielfältig, da es in unterschiedlichen Bereichen verwendet werden kann. Aber vor allem in der Wirtschaft spielt es eine große Rolle. Mit dem Einsatz der Datenanalyse durch Data Mining können sich Händler besser auf das Kaufverhalten der Kunden anpassen und ihnen ein besseres Einkaufsserlebnis sowohl online als auch im Laden anbieten. Ferner können Banken und Versicherungen die Bonität ihrer Kunden schneller beurteilen.
Nichtsdestotrotz sollte man immer bedenken, dass die Daten nicht immer vollständig oder zum Teil fehlerhaft sein können, was zu verfälschten Resultaten führt. Somit ist die Qualität der Daten ausschlaggebend für aussagekräftige Ergebnisse.
Dieser Beitrag ist im Rahmen der Lehrveranstaltung Content Management im Wintersemester 2019/20 bei Andre Kreutzmann (und Monika Steinberg) entstanden.
In seiner Bachelorarbeit mit dem Titel “Analyse und Klassifikation der hannoverschen IT Kompetenzen in einer variablen Datenbasis“ schreibt Matthias Olbrisch (2019) in seinem Abstrakt:
„Die allgemeine Digitalisierung und besonders die IT-Branche in Hannover, stellen Arbeitgeber*innen vor große Herausforderungen. Berufsbezeichnungen im IT-Sektor zeichnen sich im Gegensatz zu klassischen Berufsfeldern nicht dadurch aus, dass sie vereinheitlicht sind. Unterschiedlichste Berufsbezeichnungen verlangen oftmals identische Kompetenzen. Die Kompetenzen und Fähigkeiten der Arbeitnehmer*innen stehen ebenso immer mehr im Fokus der Arbeitgeber*innen, wie die Bereitschaft der permanenten Weiterbildung.
Zielgebend der vorliegenden Abschlussarbeit ist eine Datenbasis zu liefern, die den Anspruch hat, die bereits beschriebenen Herausforderungen zu analysieren und zu klassifizieren. Zunächst ist daher eine Klassifikation, der auf dem hannoverschen Jobmarkt gesuchten IT-Kompetenzen, zu erstellen. Vorbereitend wird eine Marktanalyse angefertigt, die sowohl Jobsuchmaschinen auf ihre Kompetenzorientierung als auch IT-Kompetenzklassifikationen untersucht.
Die erstellte Klassifikation bildet anschließend die Grundlage für das Kompetenzmatching zwischen Klassifikation und den Kompetenzen, die hannoversche IT-Studierende erlernen, um zu verdeutlichen, in welchen Kompetenzen Weiterbildungsbedarf besteht. Die entstandene Datenbasis wird in einer MySQL Datenbank präsentiert, um eine möglichst flexible Verwendung und Weiterentwicklung des Datenbestands zu ermöglichen.“
Das Vermitteln von agilen Arbeitsmethoden ist für viele Menschen zwar interessant, jedoch sind Vorträge über solche Themen oftmals monoton und reizlos. Die Agile Kitchen GmbH hat sich einen individuellen Weg ausgedacht, um diese agilen Methoden auf unterhaltsame Weise zu vermitteln. Sie haben einen Kochkurs entwickelt, der nach dem Scrum-Prinzip funktioniert. Durch die metaphorische und praktische Anwendung lernt der Nutzer nach dem Learning-by-Doing-Prinzip.
Sowohl die Mitarbeiter eines Unternehmens, als auch Einzelpersonen, die sich privat weiterbilden möchten, können diesen Kurs als Fortbildungsmaßnahme besuchen.
Das Learning-by-Doing-Prinzip ist eine effektive Art zu lernen. Diese Methode setzt darauf, dass direkt Erfahrungen gesammelt werden können und bewusst aus Fehlern gelernt werden kann.
Das Angebot des agilen Kochens ist individuell anpassbar. Es werden vier verschiedene Kurse offeriert, welche je nach Zielgruppe gebucht werden können.
Alle Schritte von Scrum werden hierbei erklärt und anhand einer Metapher dargestellt. Nach dem Start werden die Teilnehmer in Kochteams aufgeteilt. Kurz darauf beginnt der Prozess bei dem bspw. einWarenkorb den Product Backlog bildet.
In der Bachelorarbeit von Sarah Büchting (2019) mit dem Titel „Webbasierte Programmierplattformen für Kinder im Vergleich“ wird thematisiert, wie Coding zu Zwecken der sich im Umbruch befindenden MINT-Bildung eingesetzt werden kann und welche Kompetenzen durch das Erlernen von Programmierfähigkeiten gefördert werden.
Darüber hinaus wird ein Bezug zur Informatik als Herkunftswissenschaft des Coding hergestellt und die Relevanz einer frühzeitigen Aneignung von Programmierfähigkeiten in einer digitalen Gesellschaft beleuchtet.
Eine Analyse der webbasierten Programmierplattformen Open Roberta Lab, Scratch, Sprite Lab von Code.org und TurtleCoder, die zur Vermittlung von Programmierfähigkeiten bei Kindern genutzt werden können, gibt Aufschluss darüber, ob sich die benannten Programmierplattformen auch für den Einsatz in außerschulischen Bildungseinrichtungen, wie etwa öffentlichen Bibliotheken, eignen.
Die Bachelorarbeit von Sarah wurde vorbildlich über SerWisS veröffentlicht und ist als Volltext zu finden unter:
Unsere PWA soll einige allgemeine Informationen über unseren Studiengang vorstellen. Dabei haben wir uns die Texte von der offiziellen Webseite des Studiengangs genommen: https://im.f3.hs-hannover.de/studium/
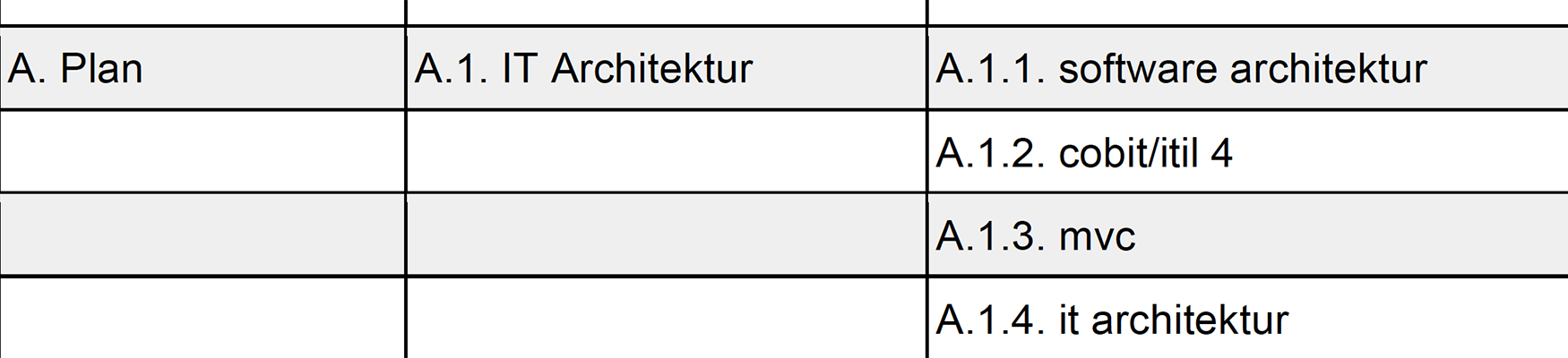
Anforderungen
Die Progressive Web App soll folgende Anforderungen (Use-Cases) erfüllen:
Navigation:
Anforderung: Navigation
Beschreibung: Dem Nutzer soll es möglich sein, durch die Applikation zu navigieren. Dabei sollen Links für die einzelnen Ansichten zur Verfügung stehen.
Detailbeschreibung: Die Navigation soll alle Ansichten der Webseite erreichbar machen. Vor allem soll dem Nutzer klar sein, welche Funktion die Links der Navigation haben.
Mockup:
2. Progressive Web App
Anforderung: Progressive Web App
Beschreibung: Die Applikation soll eine Progressive Web App sein und demnach alle üblichen Anforderungen dafür erfüllen.
Detailbeschreibung: Die Seite soll nur einmal geladen werden vom Browser. Daraufhin soll der komplette Content ohne neuladen der Seite erreichbar sein. Klickt man auf die Navigation, wird im Content Bereich der Seiteninhalt angezeigt, ohne das die komplette Seite neu lädt.
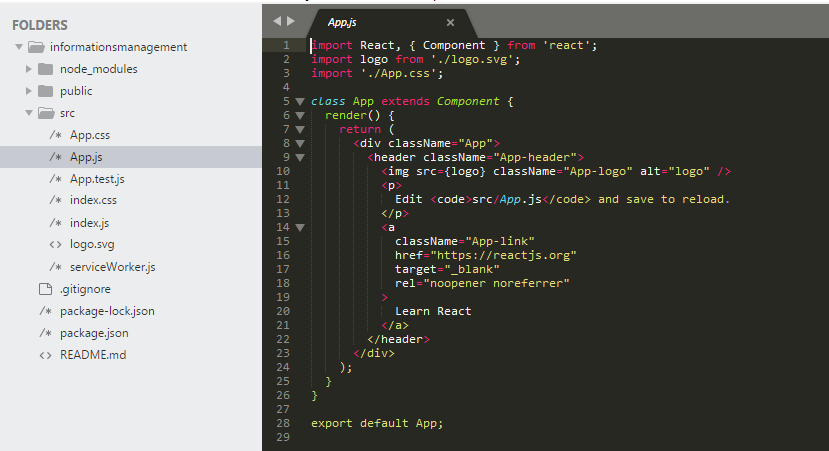
Der react-router-dom bietet eine Vielzahl an Möglichkeiten an die Navigation so umzusetzen, dass der Code sauber bleibt und die Applikation eine Single-Page-Applikation bleibt. (Beim Aufruf der Unterseiten wird nicht die komplette Seite neu geladen.) Nach Implementation der Navigation mit Hilfe des Tools ergibt sich folgende index.js:
3. Seiteninhalte/Komponenten erstellen
Wir wollen die Unterseiten Inhalt, Struktur, Zeitplan und Praxisphasen von https://im.f3.hs-hannover.de/studium/ in der PWA darstellen. Dafür haben wir jeweils eine JavaScript Datei erstellt. Daraufhin wurden sie in die index.js importiert und in die Navigation eingebunden (siehe Punkt 2 screenshot). Hier als Beispiel die inhalt.js:
Dies wurde analog für die anderen drei Seiten ebenfalls umgesetzt.
4. Aus der React App eine PWA generieren
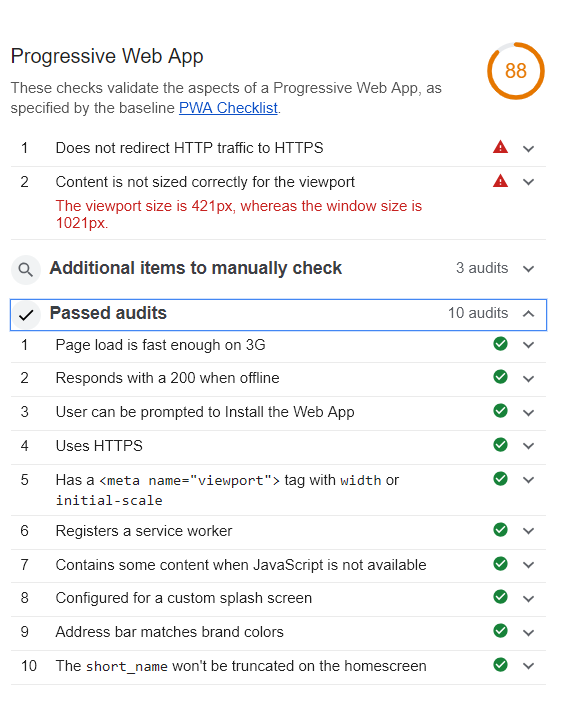
Als wir die React Applikation soweit fertig hatten, galt es als nächstes daraus auch eine PWA zu generieren. Dafür nutzen wir das Chrome Tool Lighthous – Audits (https://developers.google.com/web/tools/lighthouse/)
Das Tool kann Webseiten darauf prüfen, ob diese PWA geeignet sind. Die Ergebnisse unseres ersten Tests waren wie folgt:
Als wir online recherchiert haben, sind wir auf folgende Anleitung gestoßen:
Die Anleitung beschreibt Schritt für Schritt, wie man aus einer react Applikation eine PWA erstellt.
Damit die Seite auch funktionieren kann, wenn der Nutzer offline ist (welches eine Voraussetzung für PWA’s ist), mussten wir einen ServiceWorker registrieren. Dafür haben wir eine worker.js Datei erstellt:
Und die index.html angepasst, sodass die App prüft, ob der genutzte Browser einen ServiceWorker unterstützt:
Natürlich muss auch der ServiceWorker noch in der index.js registriert werden:
Als nächstes haben wir die Splash-Icons hinzugefügt und Anpassung an der manifest.json durchgeführt. Dadurch kann der Nutzer die Webseite als App herunterladen und offline nutzen. Die gesetzten Icons werden dann als Verknüpfungssymbol genutzt:
Nach den Anpassungen gab uns der Test von Lighthouse Audits folgendes Ergebnis:
5. Deployment
Da unsere PWA nun startklar war, mussten wir diese nur noch deployen. Dafür reichte ein einzelner Befehl in der Kommandokonsole:
Damit wurde der Ordner “build” generiert, welcher auf den Produktionsserver (unser webspace) hochgeladen werden konnte.
Seit Januar 2019 ist das WebLab Teil des QpLuS-IM-Projekts im Studiengang Informationsmanagement. Auch QpLuS-IM widmet sich dem Ausbau von Blended-Learning-Szenarien sowie mehr Selbststeuerungskompetenz durch digitales Lernen und führt so den WebLab-Ansatz wunderbar weiter, wie im Detail auf der QpLuS-IM-Projekt-Website zu lesen ist.
Neues WebLab-Team
Da sich Einige des ursprünglichen 2017er WebLab-Teams inzwischen leider (und auch nicht „leider„, weil ja genau richtig so) im Studiums-Endspurt mit Praktika und Bachelorarbeit befinden, haben wir inzwischen tolle Unterstützung durch fünf neue studentische Hilfskräfte bei QpLuS-IM und im WebLab. Wer das genau ist und was sie so machen, finden Sie unter WebLab-Team und auf der QpLuS-IM-Website.
Kommentare werden geladen …
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.