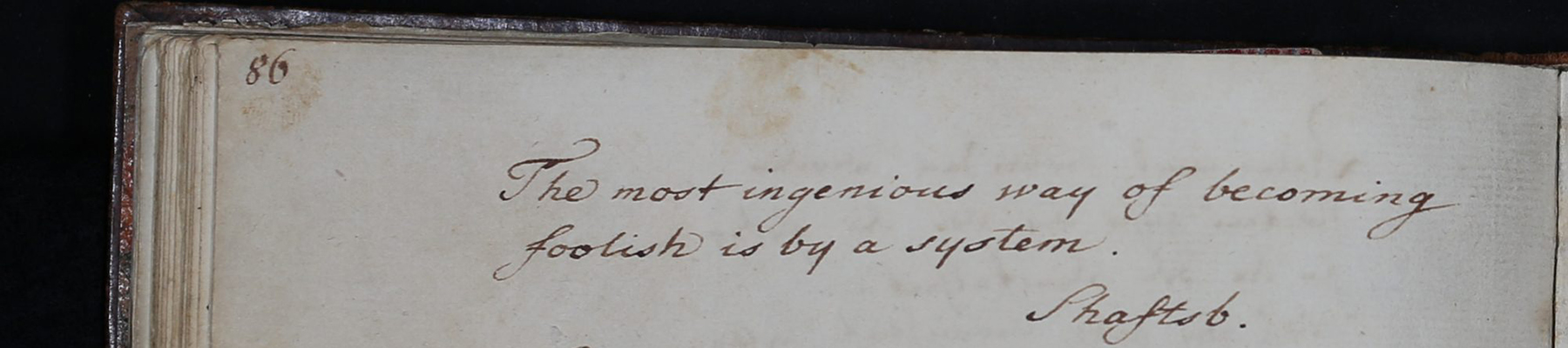Wie kodiere ich einen Stammbucheintrag mit XML-TEI und welchen Nutzen hat die Anwendung dieser Mark-Up-Language bei der Erschließung des Eintrags für die Forschung? Mit diesen Fragen befasst sich dieser Beitrag.
Zum Abschied bekam ich ein Album Amicorum – in Holland, Deutschland und in den skandinavischen Ländern ist das eine beliebte Sitte. Man geh mit diesem Buch zu einem Freund, der etwas Selbsterfundenes hereinschreibt oder einen Ausspruch irgendeines Autors, und seinen Namen daruntersetzt; wenn er kann, zeichnet er noch etwas hinzu. So hat man etwas mit dessen Hilfe man sich an seine Freunde erinnern kann. Keine schlechte Idee, aber auch ein bisschen skurril.1
James Boswell
Den meisten von Ihnen dürfte der von James Boswell 1764 in seinem Journal beschriebene Brauch aus Kindheitstagen bekannt sein, denn beim hier erwähnten Album Amicorum – auch Stammbuch genannt -, handelt es sich um ein frühes Poesiealbum. Im Gegensatz zu heute waren jedoch meist Erwachsene, die als Stammbuchhalter bezeichnet werden, die Besitzer dieser Alben, die sie auch auf Reisen mit sich trugen.
Entstanden ist diese Tradition Mitte des 16. Jahrhundert in Wittenberg, als es Mode wurde, die Autographen der Reformatoren um Luther zu sammeln. Anfangs vor allem unter Studenten Anklang findend, waren die Stammbücher später in fast allen Gesellschaftsschichten beliebt und erfreuten sich im Besonderen in Deutschland bis Mitte des 20 Jahrhunderts gesellschaftlicher Wertschätzung. 2
Stammbücher können in verschiedenen Disziplinen als wertvolle Quelle dienen. So geben sie Auskunft über die Studienorte und Reiserouten sowie die sozialen Netzwerke ihrer Eigentümer. 3
Ferner lassen sich Rückschlüsse über die Alltagskultur ziehen und sie fungieren als Zeugnisse der Wissenschaftsgeschichte und Literaturhistorie. Für Sprachwissenschaftler sind die Alben inbesondere wegen der Vielfalt der Sprachen, in denen die Beiträge verfasst sind, von Interesse.4
Viele Bibliotheken und Archive sind heute im Besitz von Stammbüchern. Die weltweit größte Sammlung stellt die der Herzogin Anna Amalia Bibliothek mit über 1900 dieser Freundschaftsbücher dar.
Zentral für die Einrichtungen ist es dabei, die Erforschung ihrer Sammlungen zu ermöglichen. Doch wie soll das realisiert werden? Neben der zunehmenden Digitalisierung rückt auch eine tiefergehende Erschließung der Alben in den Fokus. So kann beispielsweise im Katalog der Herzogin Anna Amalia Bibliothek seit einiger Zeit nach Einträgen, Einträgern, Erscheinungsorten und Erscheinungsjahren der Stammbücher recherchiert werden. Die UB Tübingen wiederum stellt Transkriptionen ihrer Freundschaftsbücher zur Verfügung, die mit TEI kodiert wurden.
2. Was ist TEI?
TEI, kurz für „Text Encoding Initiative“, ist ein Dokumentenformat, das auf der Markup-Language XML basiert und der Auszeichnung von Texten dient. Beschrieben wird es in den TEI Guidelines. Neben dem Markup von textgestalterischen bzw. strukturellen Elementen, wie beispielsweise Absätzen, Zeilenumbrüchen oder der Position einer Illustration, können auch semantische Auszeichnungen vorgenommen werden. Hierzu zählt etwa die Kennzeichnung von Personennamen oder Orts- und Datumsangaben. TEI stellt heute den De-facto-Standard bei der Textkodierung dar und kommt daher bei der Erstellung von Digitalen Editionen regelmäßig zum Einsatz.5
Während jedoch beispielsweise mit TEI erstellte Briefeditionen häufiger vorkommen, sind – mit Ausnahme des Tübinger Projekts – mittels TEI kodierte Stammbucheinträge bislang sehr rar gesät.
3. Kodierung des „Werther-Stammbuchs“ mit TEI
Welche Vorzüge die Kodierung von Stammbucheinträgen mit TEI für die Forschung mit sich bringt und wie bei der Auszeichnung vorgegangen werden kann, soll daher nachfolgend exemplarisch anhand TEI-kodierter Eintragungen aus dem auch als „Werther-Stammbuch“ bezeichneten Album von Ludwig Schneider (1750-1826), einem Juristen, veranschaulicht werden.
Den inoffiziellen Titel „Werther-Stammbuch“ trägt es, da es einen deutlichen Bezug zu Goethes Aufenthalt in Wetzlar im Sommer 1772 aufweist, als dieser die Bekanntschaft mit Charlotte Buff, dem Vorbild für Werthers Lotte sowie deren Verlobten Johann Christian Kestner machte. Von allen drei Personen finden sich Einträge im Stammbuch.6
Kodierung des Stammbucheintrags von Christian Albrecht von Kielmannsegg
Wie auch anhand der von Christian Albrecht von Kielmannsegg, ebenfalls Jurist und Jugendfreund Goethes, gestalteten Seite (Abbildung 2) deutlich wird, weisen Stammbucheinträge, die als Inskriptionen bezeichnet werden, typischerweise eine Zweiteilung auf. Auf eine im weiteren Sinn poetische Textpassage folgt in der Regel eine Widmungspassage, die aus immer wiederkehrenden Strukturelementen besteht.
Auszeichnung der Widmungspassage
Unter „Adressierung“ fallen alle Elemente, die Informationen über den Stammbuchhalter enthalten. Je nach Charakter der Beziehung kann hier die namentliche Nennung variieren. Des Weiteren kann sie durch Statusangaben angereichert werden.7
Die Elemente der „Motivierung“ und „Charakterisierung“ sind oftmals nur schwer voneinander abzugrenzen, da sie häufig fließend ineinander übergehen. Während die Komponente der Motivierung den Fokus auf den Schreibanlass legt, definiert sich die Charakterisierung dadurch, dass auf die vorangegangene Textpasssage zurückverwiesen wird. Der Stellenwert des Textteils wird hervorgehoben und Aussagen über seine Funktion getroffen.8
Den Abschluss der Passage bildet in der Regel eine sogenannte Sprachhandlungsformel, die das Verfassen des Stammbucheintrags meist als „schenken“, „widmen“, „sich empfehlen“, näher definiert.9
Dieser charakteristische Aufbau lässt sich durch TEI nachbilden. Wie das Codebeispiel zum Eintrag von Kielmannsegg zeigt, wurde der eigentliche Text als <div> (Textabschnitt) getaggt, während die Widmungspassage mit dem Element <closer> ausgezeichnet wurde, das aus der Briefedierung stammt.
[C]loser> fasst Grußformeln, Datumszeilen und ähnliche Phrasen zusammen, die am Ende eines Abschnitts stehen.10
</teiHeader>
<text type="Stammbucheintrag">
<body>
<div type="Dramenverse">
<cit>
<quote xml:id="Fußnote1">
<l>Am beſten iſt, und wahrſten der mein Freund,</l>
<l>Der warm, nicht heiß das Gute, das ich habe;</l>
<l>Der ſtreng nicht, doch genau den Fehl auch ſieht.</l>
<l>Hat dieſer Freund ein Herz der Redlichen,</l>
<l>So liebt er mich, wie ich geliebt mag ſayn.</l>
</quote>
<bibl>
<author ref="http://d-nb.info/gnd/118563386" rend="underlined"
>Klopstock</author>.</bibl>
</cit>
</div>
<closer>
<salute rend="right"><seg type="Adressierung">dem Herrn Beſitzer dieſes
Buchs</seg>
<seg type="Schreibhandlungsformel">em-<lb/>pfiehlt ſein Andenken beſtens
und gehorſamſt.</seg></salute>
<signed rend="right">
<persName ref="http://d-nb.info/gnd/116157372"><forename><choice>
<abbr>C.</abbr>
<expan>Christian</expan>
</choice></forename><surname> Kielmannsegg</surname></persName> aus <placeName
ref="http://d-nb.info/gnd/4038197-3">Meklenburg</placeName></signed>
<dateline rend="left"><placeName ref="http://d-nb.info/gnd/4065878-8"
>Wetzlar</placeName>, den <date when="1773-05-16">16ten May 1773</date></dateline>
</closer>
</body>
<note type="editorial" target="#Fußnote1">Die Verse wurden dem Trauerspiel <name type="work"
>David.Ein Trauerspiel</name> von <persName ref="http://d-nb.info/gnd/118563386"
><forename>Friedrich Gottlieb</forename><surname> Kloppstock</surname></persName>
entnommen.</note>
</text>
</TEI>
Innerhalb dieses Abschnitts wiederum wurden die Adressierung und Sprachhandlungsformel näher spezifiziert. Zunächst wurden sie durch das Element <salute> als Bestandteil der Grußformel ausgewiesen und anschließend anhand des <seg>-Elements (Segment) in Verbindung mit dem type-Attribut eindeutig als Addressierung (<seg type=“Adressierung“) bzw. Schreibhandlungsformel (<seg type=“Schreibhandlungsformel“) gekennzeichnet.
Als problematisch kann sich in diesem Zusammenhang die Tatsache erweisen, dass XML keine Überlappungen zulässt. So ist es grundsätzlich möglich, dass Textteile sowohl Bestandteil der Motivierung als auch der Charakterisierung sind und sich darüber hinaus gleichzeitig der Sprachhandlungsformel zuordnen lassen. Als pragmatische Lösung hierfür bietet sich jedoch an, nur die jeweils charakteristischen Worte den entsprechenden Bestandteilen der Widmung zuzuordnen.
Der Name bzw. die Unterschrift des Einträgers wird als <signed> (Unterschrift) getaggt und als <persName> – unterteilt in <fore- und surname> – erfasst, während Orts- und Datumsangabe zunächst unter <dateline> zusammengefasst und dann durch <placeName> bzw. <date> gekennzeichnet werden. Durch die Verwendung des when-Attributs in Verbindung mit <date> wird das Datum zusätzlich noch in maschinenlesbarer und normierter Form aufgenommen. Das <signed>-Element dient dazu, dass der Name des Einträgers später eindeutig maschinell herausgefiltert werden kann, da an mehreren Stellen im Stammbucheintrag Personennamen in unterschiedlichen Funktionen vorkommen können. Eine Besonderheit stellt hier die Auszeichnung des Namens dar. Kielmannsegg hat seinen Vornamen mit C. abgekürzt, was durch das Element <abbr>, Abbrevation kodiert wird. TEI lässt es jedoch zu, durch das Element <expan> (Expansion) gleichzeitig den ermittelten, vollen Namen anzugeben.
Auch ein weiterer großer Vorteil der Verwendung von TEI wird in diesem Zusammenhang deutlich. So ist es durch das ref-Attribut möglich auf Normdaten zu referenzieren. Konkret wurde hier mittels des Attributs bei <persName> der GND-Eintrag des Verfassers Christian Kielmansegg verlinkt. Auch bei den Entitäten Eintragungsort und Herkunftsort des Verfassers, ebenfalls durch <placeName> ausgezeichnet, wurde ein Link zum GND-Eintrag aufgenommen.
Neben der eindeutigen Identifizierung kann diese Erfassung der Normdaten der Erforschung und Visualisierung von Personennetzwerken oder der Sichtbarmachung der Wege und Aufenthaltsorte des Stammbuchhalters sowie der Einträger dienen.
Dazu ein Beispiel aus der Goethe-Forschung: Lange ging man davon aus, dass Johann Caspar Goethe, der Vater des berühmten Dichters, zu einem bestimmten Zeitpunkt Berufspraxis in Wien sammelte, da er dies in einem Bittgesuch an Kaiser Karl zu Protokoll gegeben hatte. Anhand von zwei Stammbucheinträgen konnte man jedoch nachweisen, dass er tatsächlich aber -mutmaßlich im Rahmen einer Bildungsreise – in Augsburg weilte und auch, dass er nicht alleine reiste, da sich eine weitere Person, Johann Georg Cocceji, jeweils am selben Tag wie Goethe in beide Stammbücher eintrug. 11
Die Position der Grußformel und Datumszeile auf der Seite, die sich in vielen Stammbucheinträgen wiederfindet, lässt sich durch das Attribut rend=“right“ oder rend=“left“ ausdrücken, z. B. <dateline rend=“left“>.
Auszeichnung der Textpassage
Werfen wir nun einen Blick auf die der Widmung vorangestellte Textpassage. Typischerweise besteht diese aus wenigen Gedichtversen oder knappen Prosatexten, die zum Nachdenken angeregen, Einsichten vermitteln oder an das Befolgen bestimmter Maxime appellieren.12 Im Regelfall handelt es sich dabei um bereits bestehende Texte, die wortgenau oder leicht verändert, mit oder ohne Angabe des Urhebers, zitiert werden.13
Auch Kielmansegg bedient sich eines bereits vorhandenen Textes. So zitiert er ein Werk Friedrich Gottfried Kloppstocks. Der Zitatcharakter des Elements wurde durch das Element <quote> deutlich gemacht.
Da der Einschreiber außerdem Kloppstock als geistigen Schöpfer angegeben hatte, wurden diese Quellenangabe und das Zitat zusätzlich durch das Elternelement <cit> (cited quotation) ausgezeichnet. So heißt es in den TEI:
Dabei wird der gesamte Zitatblock, inklusive Zitat und Quelle, mit dem dafür vorgesehenen <cit>-Element umschlossen. Die Quellenangabe wird mit dem <bibl>-Element kodiert, das […] unstrukturierte bibliografische Angaben repräsentiert.14
Innerhalb der Quellenangabe wurde Kloppstock mit <author> getaggt und der GND-Normdatensatz verknüpft. In einem editorischen Stellenkommentar <note>, der über eine xml:ID und das Attribut target mit der referenzierten Passage verknüpft ist, können zusätzliche Informationen zum Text festgehalten werden. In diesem Fall wurde darauf hingewiesen, dass die Verse dem Trauerspiel „David“ von Kloppstock entnommen sind.
Das Zitat wiederum wurde zusätzlich mit dem Element <div> ausgezeichnet , was erst einmal recht allgemein für Textabschnitt steht. Durch die Verwendung des Attributs type, konnte jedoch eine Aussage über die Gattungszurordnung, hier type=“Dramenverse“ getroffen werden.
An dieser Stelle wird deutlich, dass die TEI-Kodierung nicht nur in Bezug auf die personengeschichtliche Forschung, sondern auch im Hinblick auf die in den letzten Jahren stärker werdende Beschäftigung mit der literarischen Gestaltung der Stammbucheinträge Potential bietet. So werden intertextuelle Verweise sichtbar und eine Auswertung der Kodierung lässt beispielsweise Aussagen über die Häufigkeit der Zitierung bestimmter Autoren oder die Verwendung von Textgattungen zu. Angesichts der wachsenden Zahl an Werknormdaten in der Gemeinsamen Normdatei wäre es in diesem Zusammenhang zukünftig wünschenswert, auch auf diese zu verweisen. Im Fall des Kloppstockschen Trauerspiels war leider kein Normdatensatz vorhanden.
Auch Besonderheiten bei der textlichen Gestaltung können ausgezeichnet werden. So wird die Unterstreichung des Namen Kloppstock durch das Attribut rend=“underlined“ ausgedrückt und die verwandten langen s („ſ“) der Kurrentschrift werden durch Unicode dargestellt.
Neben den Texten finden sich auch immer wieder Illlustrationen in den Stammbüchern. Bei der Erstellung bediente sich der Einschreiber den unterschiedlichsten künstlerischen Techniken, die von Bleistift- Buntstift-, Kohle- und Tuschezeichnungen über Aquarellmalereien und Gouache zu Druckgrafiken reichen. Ebenso vielfältig ist auch die Wahl der Motive. So finden sich darunter zum Beispiel Wappenzeichnungen oder Porträts, aber auch Bildgegenstände, die sich auf den Text, den Eigentümer des Stammbuchs oder sein Verhältnis zum Einträger beziehen.15
Auszeichnung der Bildbeigabe
Auch diese bildlichen Elemente können durch TEI ausgezeichnet werden. So wurde die Vogel-Zeichnung (Abbildung 3) in dem hier in Auszügen vorgestellten kodierten Eintrag von Dietz Kayß zunächst mittels <div type=“Bildbeigabe“> getaggt und zusätzlich mit dem Element <figure> als Abbildung ausgezeichnet. Durch das type-Attribut wurde sie näher als Tuschezeichnung klassifiziert. Mittels des Elements <graphic> in Kombination mit dem Attribut url kann die Quelle angegeben werden. <FigDesc> (description of figure) ermöglicht eine detailllierte Beschreibung des Bildinhalts.
Die Kodierung der graphischen Bestandteile des Eintrags erlaubt es auch hier, die Daten später gezielt maschinell auszulesen, um beispielsweise Aussagen über die Verwendungshäufigkeit von Techniken oder Motiven zu treffen.
</teiHeader>
<text type="Stammbucheintrag">
<body>
<pb n="60"/>
<div type="Bildbeigabe">
<figure type="Tuschzeichnung">
<graphic url="bildconcordia.jpeg"/>
<figDesc>Bei der Abbildung handelt es sich um die Zeichung eines Vogels im Flug,
mutmaßlich einer Taube, der ein Spruchband mit der Aufschrift "Concordia" im
Schnabel hält. In der rechten oberen Ecke des Bildes ist eine strahlende Sonne mit
grimmigen Gesichtsausdruck zu sehen. Augenscheinlich wurde die Zeichnung mit
brauner Tinte angefertigt.</figDesc>
</figure>
</div>
Die Auszeichnung der Textkomponente dieser Inskription (Abbildung 4) wiederum zeigt, dass TEI auch der Erforschung, in welchen Sprachen die Stammbucheinträge verfasst wurden, Rechnung trägt. So wurde das erste Zitat, bei dem es sich um eine Gnome – also einen Sinnspruch – handelt, mit dem Attribut xml:lang und dem Sprachcode „la“ ausgezeichnet, um auszudrücken, dass es, abweichend vom restlichen Text, in lateinischer Sprache vorliegt. In diesem Zusammenhang wurde auch durch @rend=“latintyp“ die Verwendung der lateinischen Schrift gekennzeichnet.
Bei den darunter befindlichen Versen konnte durch das <rhyme>-Element zunächst deutlich gemacht werden, dass es sich um einen Reim handelt und mittels des Attributs label wurde zusätzlich das hier verwendete Reimschema getaggt.
Als problematisch erwies sich die Kodierung des Studentenordens im Beispiel. Eigentlich eher ein Schriftsymbol – und damit textuelles Element – wurde er dennoch in Ermangelung einer spezifischeren Auszeichnungsmöglichkeit als Abbildung getaggt.
<pb n="61"/>
<div type="Gnome">
<p><quote xml:lang="la" rend="latintyp" xml:id="Fußnote1">Amicus certus in re incerta
cernitur</quote></p>
</div>
<div type="Gnome">
<quote>
<lg type="rhyming_couplet">
<l>Gute Freunde in der <rhyme label="a">Noth</rhyme></l>
<l>gehen tausend auf ein <rhyme label="a">Loth</rhyme></l>
</lg>
</quote>
</div>
<closer>
<salute rend="right">
<seg type="Adressierung">
<choice>
<abbr>HochEdelgebℓ</abbr>
<expan>Hochedelgeborener</expan>
</choice> Herr und <choice>
<abbr>Br.</abbr>
<expan>Bruder</expan>
</choice></seg>
</salute>
<salute rend="right">
<seg type="Motivierung">Habe die Gewogenheit, und erinnere<lb/> Dich öfters Deines<lb/>
<choice>
<abbr>gehorſℓ</abbr>
<expan>gehorſamen</expan>
</choice>
<choice>
<abbr>Dr.</abbr>
<expan>Dieners</expan>
</choice> und Freunds</seg></salute>
<signed rend="right">
<abbr>K.A.F.</abbr>
<unclear reason="illegible" cert="medium"><persName><forename>Dietz</forename>
<surname>Kayß</surname></persName></unclear>. <abbr>Not.</abbr></signed>
<dateline rend="left"><placeName ref="http://d-nb.info/gnd/4020989-1">Giesen</placeName><lb/>
<date when="1771-03-28">28.3.1771</date>
</dateline>
</closer>
<figure type="Zeichen_eines_Studentenordens" rend="left">
<figDesc>Zeichen eines Studentenordens, enthält augenscheinlich die Zahl 1770 und ein
C</figDesc>
</figure>
</body>
<note type="editorial" target="#Fußnote1">Gnome wird <persName
ref="http://d-nb.info/gnd/118520814"><forename>Marcus Tullius</forename>
<surname>Cicero</surname></persName>zugeschrieben.</note>
</text>
</TEI>
4. Ausblick
Generell stellen neben den Illustrationen auch die vielfältigen anderen Beigaben eine Herausforderung bei der Kodierung von Stammbucheinträgen mit TEI dar. Mitunter findet man Papierschnitte, Stickarbeiten, getrocknete Blumen, Siegelabdrücke, Musiknoten, aber auch Haarlocken sind keine Seltenheit.16
Während für die Kodierung von Siegeln mit <seal> ein spezifisches Element zur Verfügung steht und auch Musiknoten innerhalb eines Textes sich über <notatedMusic> taggen lassen bzw. für Musiknoten mit den MEI sogar eigene Codierungsrichtlinien existieren, sind die TEI für die Auszeichnung der anderen (dinglichen) Objekte (zumindest bislang) nicht ausgelegt.
Auch im Hinblick darauf, dass diese Beigaben sich ebenso bei Briefen finden lassen, wäre eine Weiterentwicklung der TEI in dieser Hinsicht wünschenswert. Festzuhalten bleibt aber auch, dass diese Mark-Up-Language bereits jetzt durch die inhaltlich, formal und strukturell tiefgehende Erschließung der Einträge neue Perspektiven für die Stammbuchforschung eröffnen kann.
[metaslider id=“16967″]
Zum Download als PDF-Datei stehen nachfolgend die vollständigen Kodierungen der im Text erwähnten Beispiele sowie weitere exemplarisch kodierte Stammbucheinträge bereit:
Die dazugehörigen Digitalisate sind in der Slideshow (Abbildung 5-8) zu finden.
Falls Sie noch nicht mit TEI vertraut sein sollten, diese Mark-Up-Sprache jedoch Ihr Interesse geweckt hat, finden Sie beispielsweise im Internetauftritt der Universität Bern einen ausführlichen Crashkurs und Workshop.
Quellen
1Boswell, James: Journal, hrsg. von Helmut Winter. Stuttgart 1986. Zitiert nach Linhart, Eva: Vom Stammbuch zum Souvenir d’Amité. Deutscher Schicksalsfaden. In: Schmidt, Volker [Hrsg.]: Der Souvenir : Erinnerung in Dingen von der Reliquie zum Andenken. Köln 2006, S. 202-232 ↩
4Vgl. Eberhards Karls Universität Tübingen [Hrsg.]: Stammbücher der UB Tübingen. Stand 25.01.2021. http://www.dh-profil.uni-tuebingen.de/tuebinger-stammbuecher/index.html, Zugriff 23.01.2022↩
5Vgl. Universität Graz. Zentrum für Informationsmodellierung in den Geisteswissenschaften [Hrsg.]: Text Enconding Initiative. 2006-2008. , Zugriff 23.01.2022 ↩
6Vgl. Heumann, Konrad: Bedeutendes Stammbuch der Wertherzeit. (Unveröffentlichtes Typoskript) ↩
7Vgl. Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 22↩
8Vgl. Schnabel, Werner Wilhelm: Das Album Amicorum. Ein gemischtmediales Sammelmedium und einige seiner Variationsformen. In: Kramer, Anke [Hrsg.]: Album : Organisationsform narrativer Kohärenz. Göttingen 2013, S. 213-239, hier S. 215; Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 22↩
9Vgl. Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 22↩
10Text Encoding Initiative. P5: Richtlinien für die Auszeichnung und den Austausch elektronischer Texte. Version 4.3.0. Last updated on 31st August 2021. https://tei-c.org/release/doc/tei-p5-doc/de/html/ref-closer.html, Zugriff 23.01.2022↩
11Vgl. Heumann, Konrad: Unterwegs nach Italien. Johann Caspar Goethes Reise nach Nürnberg und Augsburg im Jahr 1739. In: Hopp, Doris: »Goethe Pater». Johann Caspar Goethe (1710–1782). Frankfurt 2010, S. 52-61↩
12Vgl. Schnabel, Werner Wilhelm: Das Album Amicorum. Ein gemischtmediales Sammelmedium und einige seiner Variationsformen. In: Kramerm Anke [Hrsg.]: Album : Organisationsform narrativer Kohärenz. Göttingen 2013, S. 213-239, hier S. 215↩
13Vgl. Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 20↩
14Karl-Franzens-Universität Graz [Hrsg.]: Elektronische Repräsentation mit dem Standard der TEI↩
15Vgl. Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 21; Schnabel, Werner Wilhelm: Das Stammbuch : Konstitution und Geschichte einer textsortenbezogenen Sammelform bis ins erste Drittel des 18. Jahrhunderts. Tübingen 2003. S. 104↩
16Vgl. Bastian, Julia: «Des Menschen Herz faßt so unendlich viel» Das Stammbuch des Volrat Graf zu Solms-Rödelheim und Assenheim. Frankfurt 2013, S. 21; Schnabel, Werner Wilhelm: Das Album Amicorum. Ein gemischtmediales Sammelmedium und einige seiner Variationsformen. In: Kramer, Anke [Hrsg.]: Album : Organisationsform narrativer Kohärenz. Göttingen 2013, S. 213-239, hier S. 218↩
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2021/22, Dr. Stefanie Elbeshausen) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Bibliotheken haben den Auftrag, Medien und Informationen für Nutzerinnen und Nutzer aufzuarbeiten und bereitzustellen. Doch jedes Jahr werden mehrere Millionen Publikationen veröffentlicht. Die DNB allein verzeichnete den Zugang 2.352.693 neuer Einheiten im Jahre 2020[1]. Wer soll da den Überblick behalten? Text und Data Mining kann hier Abhilfe schaffen.
Text Mining, Data Mining, Text Data Mining, Textual Data Mining, Text Knowledge Engineering, Web Mining, Web Content Mining, Web Structure Mining, Web Usage Mining, Content Mining, Literature Mining und sogar Bibliomining[2] – viele Begriffe, die alle das selbe Konzept – teilweise mit unterschiedlichen Schwerpunkten – bezeichnen, welches im Folgenden Text und Data Mining, kurz TDM, genannt werden soll. Grob gesagt ist damit die algorithmusbasierte automatische Analyse digitaler Daten jeglicher Form gemeint.
TDM beinhaltet dabei explizit sowohl die Verarbeitung natürlichsprachiger Texte, sogenannter unstrukturierter Daten, als auch beispielsweise Tabellen und anderer strukturierter Daten, welche unterschiedliche Anwendungsfälle und Herausforderungen mit sich bringen. Dabei gibt es zwei große Aspekte: das Auffinden bereits bekannter Informationen und die Schaffung neuen Wissens durch die Verknüpfung oder Neuinterpretation von Bekanntem.[3]
Ganz allgemein lassen sich Verfahren des TDM in drei große Bereiche aufteilen:
Musterextraktion (Programm analysiert, welche Daten oft gemeinsam auftreten)
Es lässt sich natürlich noch feiner unterteilen in Regressionsanalysen, Abhängigkeits- oder Abweichungsanalyse, Beschreibung, Zusammenfassung, Prognose, Assoziation etc., was die große Bandbreite an Nutzungsmöglichkeiten des TDM aufzeigt[4], für uns aber gerade zu weit geht, da wir nur den Bereich der Bibliotheken betrachten wollen.
Anwendungsmöglichkeiten für Bibliotheken
Empfehlungssysteme
Eine Möglichkeit der Kataloganreicherung ist die Implementierung eines Empfehlungsdienstes. Dieser analysiert Recherche- und/oder Ausleihdaten, um Nutzenden während ihrer Recherche weitere Medien vorzuschlagen, die relevant für sie sein könnten[5]. Ein solcher Dienst ist BibTip, welcher an der Universität Karlsruhe entwickelt wurde und mittlerweile von vielen wissenschaftlichen und öffentlichen Bibliotheken in Deutschland verwendet wird.
Maschinelle Indexierung
Die inhaltliche Erschließung bietet einen großen Mehrwert bei der Recherche, ist jedoch ein zeit- und personalaufwendiger Aspekt der bibliothekarischen Arbeit. Schon 2009 begann die Deutsche Nationalbibliothek, diese Arbeit mit maschineller Unterstützung durchzuführen. Dabei wurden die in der GND hinterlegten Schlagwörter als Grundlage für die automatische Verschlagwortung mithilfe des Averbis-Programms verwendet.[6]
Herausforderungen
Urheberrecht
TDM war viele Jahre eine rechtliche Grauzone. Unklarheiten bezogen sich unter anderem darauf, ob maschinelle Verarbeitung durch die bestehenden Lizenzverträge abgedeckt war, ob temporäre für die Auswertung erstellte Kopien unerlaubte Vervielfältigung bedeuteten, inwieweit die Ergebnisse Dritten zugänglich gemacht werden durften und vieles mehr.[7] Die Urheberrechtsnovelle 2018 sorgte für mehr Klarheit, indem durch § 60d UrhG explizit die Nutzung von TDM für die wissenschaftliche Forschung erlaubt wurde.
Datenschutz
Datenschutz ist vor allem bei der Verarbeitung personenbezogener Daten wie der Analyse von Ausleih- oder Recherchevorgängen relevant. Im Sinne der Datensparsamkeit dürfen nur so viele Daten erhoben werden, wie erforderlich sind und diese auch nur so lange wie nötig gespeichert werden. Aus Datenschutzgründen werden die Daten deshalb anonymisiert gespeichert und verarbeitet. Dies schränkt beispielsweise die Empfehlungsdienste ein, da so nur die aufgerufenen oder ausgeliehenen Medien während eines einzelnen Vorgangs analysiert werden, diese jedoch nicht mit früheren Vorgängen der selben Person verknüpft werden können.
Formatvielfalt
TDM kann nur funktionieren, wenn die auszuwertenden Daten in geeigneter Form vorliegen. Dabei kann es verschiedene Hürden geben, sowohl rechtlicher Natur, wenn Daten im Besitz von Personen oder Institutionen sind, sowie technischer Natur, wenn Daten nicht in maschinenlesbarer Form vorliegen, oder zu viele verschiedene (inkompatible) Dateiformate genutzt werden.[8]
Ausblick
Schon heute profitieren Bibliotheken von TDM-Anwendungen, besonders Empfehlungsdienste sind verbreitet. Maschinelle Indexierung wird zumindest vereinzelt eingesetzt, bleibt in der Qualität aber noch weit hinter der intellektuellen Erschließung durch Menschen zurück.[9] Aufgrund des technischen Fortschritts und dem immer zuverlässiger werdenden natural language processing darf man hier jedoch hoffnungsvoll in die Zukunft blicken.
Doch Bibliotheken sind nicht nur Anwenderinnen, sondern können und sollten ebenfalls Sorge dafür tragen, dass ihre eigenen Bestände für TDM nutzbar sind. Dies wird erleichtert durch § 60d UrhG, aber sollte auch bei der Aushandlung von Lizenzverträgen, bei der Auswahl der anzubietenden Formate von elektronischen Medien wie auch bei der Retrodigitalisierung beachtet werden.
Quellen
[1] Deutsche Nationalbibliothek (2021): Jahresbericht 2020. S.45. Online unter urn:nbn:de:101-2021051859
[2] Mehler, Alexander; Wolff, Christian (2005): Einleitung: Perspektiven und Positionen des Text Mining. In: LDV-Forum, Jg. 20, Nr. 1, S. 1–18. Online unter urn:nbn:de:0070-bipr-1688
[3] Saffer, Jeffrey; Burnett, Vicki. (2014). Introduction to Biomedical Literature Text Mining: Context and Objectives. In Kumar, Vinod; & Tipney, Hannah (Hg.): Biomedical Literature Mining. New York: HumanaPress, Springer. S. 1–7. Online unter doi.org/10.1007/978-1-4939-0709-0_1
[4] Drees, Bastian (2016): Text und Data Mining: Herausforderungen und Möglichkeiten für Bibliotheken. In: Perspektive Bibliothek, Jg. 5, Nr. 1, S. 49-73. Online unter doi.org/10.11588/pb.2016.1.33691
[5] Mönnich, Michael; Spiering, Marcus (2008): Erschließung. Einsatz von BibTip als Recommendersystem im Bibliothekskatalog. In: Bibliotheksdienst, Jg. 42, Nr. 1, 54–59. Online unter doi.org/10.1515/bd.2008.42.1.54
[6] Uhlmann, Sandro (2013): Automatische Beschlagwortung von deutschsprachigen Netzpublikationen mit dem Vokabular der Gemeinsamen Normdatei (GND). In: Dialog mit Bibliotheken, Jg. 25, Nr. 2, S.26-36. Online unter urn:nbn:de:101-20161103148
[7] Okerson, Ann (2013): Text & Data Mining – A Librarian Overview [Konferenzbeitrag]. Herausgegeben von IFLA. Online unter http://library.ifla.org/252/1/165-okerson-en.pdf (Abruf am 29.01.2022)
[8] Brettschneider, Peter (2021): Text und Data-Mining – juristische Fallstricke und bibliotheksarische Handlungsfelder. In: Bibliotheksdienst, Jg. 55, Nr. 2, S. 104-126. Online unter doi.org/10.1515/bd-2021-0020
[9] Wiesenmüller, Heidrun (2018): Maschinelle Indexierung am Beispiel der DNB. Analyse und Entwicklungmöglichkeiten. In: O-Bib, Jg. 5, Nr. 4, S. 141-153. Online unter doi.org/10.5282/o-bib/2018H4S141-153
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2021/22, Dr. Stefanie Elbeshausen) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Wie sich die Fan-Fiction-Kultur professionalisiert und was aus dieser Entwicklung erwächst
Abschnitt 1 – Der ReichenbaChfall
Altes Konzept – modernes Phänomen
„Handschrift“ by Rob van Hilten is licensed under CC BY-NC-SA 2.0
Das Weitererzählen, Verändern oder Umformen bestehender Erzählungen hat eine lange Historie und Tradition.
Im Mittelalter wurden antike Stoffe aufgegriffen und für die bestehende höfische Gesellschaft neu interpretiert und arrangiert. Auch die Artus-Sage wurde vielfach aufgegriffen und in Versform gegossen. Für die eigene Erzählung griff man dabei fast immer auf bereits bestehendes Material zurück. Alles war miteinander verwoben.
Auch Bertold Brechts berühmte Dreigroschenoper ist eine Bearbeitung eines bestehenden Werkes. Der Dramatiker ließ sich von der Beggar’s Opera aus dem Jahr 1728 inspirieren. Einige Lieder, die Brecht in seinem Stück verwendet, stammen zudem von dem spätmittelalterlichen Dichter François Villon. Brecht übernahm sie wortgetreu. Ohne Quellenangabe.[1]
Ein weiteres modernes Beispiel ist der Kosmos von H. P. Lovecraft, der noch zu seinen Lebzeiten durch Erzählungen von befreundeten Autoren, mit denen er rege korrespondierte, angereichert und erweitert wurde.
Fan Fictions und schriftbasierte Roleplaying-Games, die an ein beliebtes Buch, eine Serie oder einen Film anknüpfen, reihen sich also in eine lange Tradition der Stoffadaption ein. Was sie machen ist somit keineswegs neu. Doch aufgrund ihrer Form und der veränderten Bedingungen sind sie doch etwas vollkommen Neuartiges – ein modernes Phänomen. Ein Phänomen, das von Beginn an ein Spannungsfeld erzeugte.
Denn nach wie vor sind die meisten Fan Fictions und RPGs eigentlich illegal.
Wie sich die Fan-Fiction-Kultur entwickelte
Im Jahr 1893 stürzen zwei Männer in den Tod. Die tragische Szene ereignet sich in der Schweiz, aber sie wird vor allem in Großbritannien für große Bestürzung sorgen. Aber auch für Empörung und Unverständnis. Dabei sind die beiden zu Tode gekommenen Männer nicht einmal real. Es sind fiktive Figuren. Der eine ist der »Napoleon des Verbrechens«, der andere der vermutlich schon damals berühmteste Detektiv der Welt – Sherlock Holmes.
„‚The Death of Sherlock Holmes‘ (frontispiece from The Memoirs of Sherlock Holmes, 1894)“ by Toronto Public Library Special Collections. Licensed with CC BY-SA 2.0.
Arthus Conan Doyle tötet den Protagonisten seiner Detektivgeschichten und die Tat treibt seine Leser auf die Straße. Öffentlich wird der Tod der literarischen Figur betrauert. Weil Doyle erst 1903 ein Einsehen hat und Holmes von den Toten auferstehen lässt, vernetzen sich die Leser miteinander, um das Gedenken an den Detektiv lebendig zu halten.[2] Damit legen sie den Grundstein für das erste organisierte Fandom. In verlagsunabhängig publizierten Magazinen und Essays werden Figuren und Handlung besprochen, Lücken gefüllt und kontradiktorische Angaben in den Geschichten diskutiert.[3]
Die Begrifflichkeit Fan Fiction etabliert sich in den 1960ern, als das Star-Trek-Universum immer mehr Menschen in seinen Bann zieht und mit Spockanalia das erste Fanzine entsteht, in dem Fans Bilder, Kommentare und eigene Geschichten publizieren.[4]
Seitdem entstanden unzählige weitere Fandoms, basierend auf Filmen, Serien, Büchern oder Comics und sie alle fanden in den 90ern im Internet eine neue Heimat, das mit seinen Möglichkeiten der weltweiten Vernetzung, Interaktion und Publikation optimale Bedingungen für die kreative Fankultur bot.
Verbreitung im Internet
»Heute ist Fan Fiction ohne die zugrunde liegenden digitalen Praktiken der Vernetzung von Dokumenten und Akteuren kaum mehr denkbar.«
Reißmann, Klaas, Hoffmann: Fan Fiction, Urheberrecht und Empirical Legal Studies
Fan Fictions fanden zunächst über fandom-spezifische Foren und Mailinglisten Verbreitung[5], waren aber auch bald schon auf eigenständigen Plattformen zu finden. Dadurch konnten sie mitunter eine große Leserschaft gewinnen. Die größten Plattformen und Archive diese Art, wie die englischsprachigen Seiten ‚Archiv of your own‘ (AO3) und ‚FanFiction.net‘, haben heute Nutzerzahlen in Millionenhöhe.[3]
Durch die Vernetzung der Community entstehen ständig neue Projekte. Es kommt zu Kooperation oder inhaltlichen Crossovers, bei denen Charaktere aus verschiedenen Vorlagen aufeinandertreffen.
Fan Fictions sind aber nicht die einzige Ausdrucksform literarischer Kreativität von Fans im Internet. In forengestützten Role-Playling Games (RPGs) werden Geschichten aus Sicht einzelner Figuren kollaborativ erzählt. Als Grundlage dient dabei meist ein spezifisches Universum, das durch die verschiedenen Handlungsstränge stetig erweitert, verändert oder neu ausgestaltet wird. Durch den kollektiven Schreibprozess kommt es zu einer Verschmelzung von Autor und Leser und oft auch zu einer starken Identifizierung mit der eigenen Figur.
Die Urheberrechtsproblematik
Durch das Internet wurden Fan Fictions immer mehr zu einem Massenphänomen. Die bereits bestehende Frage, in welchem Rahmen die Nutzung von urheberrechtlich geschütztem Material in einem nicht-kommerziellen Kontext praktiziert werden kann, gewann durch diese Entwicklung neue Brisanz. Denn was im Privaten problemlos möglich ist, erhält im Internet eine ganz andere Dimension.
Sobald ein Text der Allgemeinheit zugänglich gemacht wird, und dazu zählt auch das Publizieren in Foren oder Online-Archiven, fällt er unter geltendes Recht. Und dieses besagt:
»Bearbeitungen oder andere Umgestaltungen des Werkes dürfen nur mit Einwilligung des Urhebers des bearbeiteten oder umgestalteten Werkes veröffentlicht oder verwertet werden.«
§ 23 UrHG
Dieser Schutz gilt bei literarischen Werken nicht nur für die Gesamtdarstellungen, sondern auch für einzelne Figuren, sofern deren Darstellung charakteristisch für das Werk ist. Gemeint sind damit handelnde Figuren mit Wiedererkennungswert, wie bpsw. Harry Potter oder Bella Swan, aber auch Nebenfiguren, wie Severus Snape oder Charlie Swan, Bellas Vater.
»Der Gestaltenschutz der Rechtsprechung honoriert somit die individuelle Konzeption einer fiktiven Figur.«
Claudia Summerer: „Illegale Fans“
Allerdings gibts es unter Juristen eine differenzierte Debatte darüber, wie eng oder weit der Gestaltenschutz gefasst werden kann und sollte.[6] Für Fan-Fiction-Autoren und RPG-Autoren ist diese Uneindeutigkeit ein Unsicherheitsfaktor, da im Zweifelsfall unklar bleibt, ob bspw. bereits die Zuschreibung bestimmter Charakteristiken für eine bestimmte Figur den Gestaltenschutz berührt oder nicht.
Mit dieser Problematik befasst sich auch Rechtsanwalt Christian Solmecke in seinem Video zum Thema Urheberrecht und Fan Fiction.
In der Fan-Fiction-Community (RPGs mit eingeschlossen) herrschte lange die Annahme vor, sich in einer rechtlichen Grauzone zu bewegen. Mitunter wird auch heute noch vereinzelt davon ausgegangen.
Gründe für diese Annahme waren und sind zum einen Differenzen zwischen verschiedenen nationalen Rechtsnormen, wie dem deutschen Urheberrecht und dem amerikanischen Copyright Law, aber auch einzelne Aspekte der jeweiligen Gesetze.
Das Urheberrecht unterscheidet bspw. zwischen freier Benutzung und unfreier Bearbeitung.[7] Die freie Benutzung greift immer dann, wenn ein urheberrechtlich geschütztes Werk lediglich als Inspirationsquelle verwendet wird und das neu entstandene Werk selbst urheberrechtlich schutzfähig ist. Dafür müssen beide Werke jedoch ausreichend unterschiedlich sein. Trifft dies zu, dann gilt:
»Ein selbständiges Werk, das in freier Benutzung des Werkes eines anderen geschaffen worden ist, darf ohne Zustimmung des Urhebers des benutzten Werkes veröffentlicht und verwertet werden.«
§ 24 UrhG
Ab wann sich zwei Werke ausreichend voneinander unterscheiden, ist allerdings nicht näher bestimmt. Es sollte daher nicht verwundern, dass die freie Benutzung von Fan-Fiction- und RPG-Autoren im Zweifelsfall weiter gefasst wurde und wird als von Urheberrechtsinhabern.
Es muss jedoch davon ausgegangen werden, dass bereits die Erwähnung charakteristischer Handlungsorte oder Nebenfiguren, selbst wenn der Rest des Werkes eindeutig eine kreative Eigenleistung darstellt, dazu führen kann, dass das gesamte Werk nicht mehr im Einklang mit dem Recht auf freie Benutzung steht.
E. L. James, Autorin von Fifty Shades of Grey, änderte aus einem ähnlichen Grund, noch bevor ihre Geschichte als Buch publiziert wurde, die Namen ihrer Protagonisten, die an Edward Cullen und Bella Swan angelegt waren, ab.
Dem Gestaltenschutz, der nicht näher definierten Trennlinie zwischen freier Bearbeitung und unfreier Benutzung, sowie weiteren rechtlichen Unsicherheiten wird durch die gängige Praxis Tribut gezollt, in einem Disclaimer auf die Rechteinhaber des Ausgangsmaterials zu verweisen und sich von allen Eigentumsansprüchen an den verwendeten Figuren und übernommenen Inhalten freizusprechen.
Diese Disclaimer, egal welcher Art, haben jedoch keine rechtliche Gültigkeit und schützen im Zweifelsfall nicht vor einer Abmahnung oder Anklage. Diese Tatsache ist auch bereits seit langem in der Community bekannt, dennoch werden Disclaimer standardmäßig verwendet, weil sie a) zum guten Ton gehören b) den Schöpfer des zugrundeliegenden Werks würdigen und c) nach außen signalisieren, dass sich die Autoren bewusst sind, dass sie ein urheberrechtlich geschütztes Werk als Grundlage für ihre eigenen Texte verwenden und es sich somit nicht heimlich „aneignen“.
Die Urheberrechtsreform
Auch die Urheberrechtsreform, die 2018 vom EU-Ministerrat auf den Weg gebracht und im März 2019 vom EU-Parlament beschlossen wurde und bis zum 07. Juni 2021 in nationales Recht umgesetzt werden muss, half nicht dabei, die bereits bestehenden Unsicherheiten auszuräumen. Zwar waren Fan-Fiction- und RPG-Autoren von der Reform allenfalls indirekt betroffen, bedingt durch den allgemeinen Aufschrei im Internet und den massiven Protest, der sich sowohl im Digitalen als auch auf der Straße formierte, wurde allerdings ein neues Bewusstsein für geltende Rechtsnormen und bestehende Probleme geschaffen.
Aber auch außerhalb der Community geriet durch die Urheberrechtsreform einiges in Bewegung. Fan Fictions wurden bspw. im Kontext der Grundsatzdiskussion über das Urheberrecht in Bezug auf Mashups und Remixes thematisiert[8] oder zum Gegenstand wissenschaftlicher Forschung.
An der Universität Siegen befasste sich eine Projektgruppe im Rahmen des Sonderforschungsbereichs „Medien der Kooperation“ am Beispiel von Fan Fiction mit den sozialen und juristischen Rahmenbedingungen kooperativen und derivativen Werkschaffens im Netz. Die Projektleiterin Dr. Dagmar Hoffmann (Professorin für Medien und Kommunikation) kommt zusammen mit Dr. Wolfgang Reißmann dabei zu folgender Einschätzung:
»Zwar suggeriert die derzeitige Situation – zumindest im Bereich Fan Fiction – eine Koexistenz der kreativen Fans, die gewisse rote Linien nicht überschreiten, und der Medienindustrie, die von weitgehender Verfolgung absieht. Dieses fragile Nebeneinander kann letztlich jedoch nicht darüber hinwegtäuschen, dass für die Fans Rechtsunsicherheit besteht und sie im Zweifelsfall, wenn ihr Handeln nicht in die Verwertungs- und Marketingstrategien der großen Medienunternehmen passt, rechtlich am „kürzeren Hebel“ sitzen.«
Selbstbestimmung in Fan-Fiction-Kulturen. In: M&K, Jahrgang 66 (2018), Heft 4.
Die beiden Forscher äußern im Weiteren ihre Hoffnung, dass die wissenschaftliche Betrachtung eine produktive Grundlage für die bestehende Auseinandersetzung bieten wird.
Derzeit zeigen sich die meisten Autoren und Verlage aufgeschlossen gegenüber dem kreativen Schaffen der Fans. Ohne eine Sicherheiten schaffende Reformierung des geltenden Urheberrechts auf nationaler Ebene bleibt die Fan-Fiction-Kultur damit aber abhängig vom guten Willen und der Duldung der Urheberrechtsinhaber.
Dass eine solche Toleranz keinesfalls selbstverständlich ist, hat die Vergangenheit gezeigt.
Abschnitt 3 – Trends und Herausforderungen
Wie Autoren die Fan-Fiction-Kultur bewerten
Zu Beginn des neuen Jahrtausends spitzte sich der Konflikt zwischen Rechteinhabern und Fan-Autoren zu. Es wurde mit Abmahnungen gedroht und vereinzelt kam es auch zu juristischen Auseinandersetzungen.[9] Einzelne Autoren ging es darum, die alleinige Deutungshoheit über ihr Schaffenswerk zu behalten, andere fürchteten Plagiate und Umsatzeinbußen durch Fan Fictions.
Die kommerzielle Verwertung von Fan Fictions und RPG-Inhalten spielte allerdings weder zum damaligen Zeitpunkt noch danach eine relevante Rolle. Auch Plagiate blieben eine absolute Seltenheit. Stattdessen erkannten große Verlage und Markeninhaber, dass die Fan-Fiction-Kultur vor allem positive Effekte hervorruft, bspw. indem sie zur Bekanntheit eines Werkes beiträgt oder für eine langfristige Kundenbindung sorgt.[9]
Das veränderte die Wahrnehmung der Fan-Fiction-Kultur, die nun weitaus positiver bewertet und auch von einigen äußerst populären Autoren, wie J. K. Rowling, Stephanie Meyer oder Terry Pratchett, als Würdigung ihrer eigenen Werke verstanden wurde. Das führte im Allgemeinen zu einem weniger konfrontative Umgang mit Fan-Fiction- und RPG-Autoren.
Trotzdem befassen sich auch aufgeschlossene Schriftsteller meistens nicht direkt mit den Texten ihrer Fans, zum einen weil sie mögliche Rechtsstreitigkeiten von vorneherein vermeiden wollen, aber auch, um nicht in einen Interessenskonflikt zu geraten. Im Regelfall bleiben Fan Fictions daher bewusst unbeachtet. Die meisten erfolgreichen Autoren sind sich allerdings ihrer schreibenden Fans bewusst.
Fortschreitende Professionalisierung
Inzwischen ist aber nicht nur die Außenwahrnehmung von Fan Fictions eine andere, auch die Fan-Fiction-Kultur hat sich stetig verändert und weiterentwickelt. Durch neue Plattformen, wie Wattpad, aber auch ein gewandeltes Selbstverständnis der Autoren befindet sich die Community in einem Prozess der Professionalisierung.
Hinter großen Online-Archiven und Plattformen aber auch kleineren RPG-Foren stehen Administratoren- und Support-Teams, die sich um den technischen Unterbau kümmern. Moderatoren betreuen die Community, kontrollieren den Einhalt der Regeln und schlichten Streitigkeiten. Archive of Our Own bietet seinen Mitgliedern im Einzelfall sogar Unterstützung bei Rechtsstreitigkeiten.
»We are committed to defending fanworks against legal challenges. Our position on transformative fanworks is detailed in the OTW FAQ. We have legal resources and alliances on which we can draw. However, that is not a guarantee that the organization can or will fight each battle. The Board will take into account a variety of factors, both legal and otherwise, in responding to a legal challenge.«
AO3 – Terms of Service – What we believe
„Spend“ by 401(K) 2013. Licensed with CC BY-SA 2.0.
Diese Arbeit wird entweder durch Spenden finanziert (z. B. bei AO3) oder durch Werbeeinnahmen (z. B. bei Wattpad). Generell ausgeschlossen ist jedoch weiterhin, dass die Autoren mit ihren Geschichten Geld verdienen. An diesem Grundsatz, der aufgrund der urheberrechtlichen Bestimmung eigentlich nicht verhandelbar ist, wird derzeit jedoch gerüttelt. Auf Patreon suchen inzwischen auch vermehrt Fan-Fiction-Autoren nach monetärer Unterstützung, was in der Community recht kritisch gesehen wird, weil befürchtet wird, dass, sollten immer mehr Autoren diesem Beispiel folgen, die Duldung von Fan Fiction durch die Rechteinhaber auf’s Spiel gesetzt wird.
Für die großen Plattformen ist dies ebenfalls ein Problem. Bei AO3 ist die Verbreitung von kommerziellen Produkten und Aktivitäten bspw. generell untersagt. Bereits die Verlinkung auf Patreon ist in diesem Kontext hochproblematisch, weshalb es immer wieder zur Sperrung von Accounts kommt. Letztlich können aber auch die Plattformbetreiber die Nutzung von Patreon nicht unterbinden.
Im Bereich der RPGs ist diese Entwicklung eher irrelevant, da an den kollaborativ erzählten Geschichten kein einzelner Autor die Rechte daran für sich allein beanspruchen und auf diesem Wege monetarisieren könnte.
Ob die Nutzung von Patreon und ähnlicher Angebote daher zu einem Problem für die Fan-Fiction-Kultur an sich wird, ist zumindest im Moment noch nicht klar. Zweifelsohne wird diese Entwicklung aber zu neuerlichen Debatten über die derzeit geltenden rechtlichen Bestimmungen führen und gegebenenfalls sogar eine juristische Nachjustierung erzwingen.
Die Urheberrechtsreform ist zwar erst vor 2 Jahren beschlossen worden und wird erst in diesem Jahr in nationales Recht umgesetzt, das bedeutet aber noch lange nicht, dass sie auch auf der Höhe der Zeit ist.
[9] Reißmann, Wolfgang; Hoffmann, Dagmar: Selbstbestimmungen in Fan Fiction Kulturen. In: M&K, Jahrgang 66, Heft 4, S. 470 (2018)
Beitragsbild
„Urheberrecht“ by Skley. Licensed with CC BY-ND 2.0.
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2020/21, Prof. Dr.-Ing. Steinberg) entstanden. Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Beschäftigt man sich mit der Erstellung von Webseiten, begegnen einem früher oder später auch die Begriffe User Experience (UX) und Search Engine Optimization (SEO). Wenn Du diese Begriffe noch für komplettes Neuland hältst, bist Du hier genau richtig. Beleuchten wollen wir dabei die Kombination von User Experience und SEO. Nach einer kurzen Einführung in das Thema werden wir anhand einiger entscheidender Hintergründe nachvollziehen, weshalb User Experience und SEO immer stärker im Zusammenhang betrachtet werden.
Aufgrund der beobachteten Annäherung von SEO und User Experience gewinnt auch Search Experience Optimization (SXO) an Bedeutung. Denn diese Bezeichnung vereint beide Disziplinen. Dabei eröffnet sich ein spannender Themenkomplex, der hoffentlich auch einige Mitstudierende des Informationsmanagements motiviert, sich (noch) näher mit User Experience und SEO zu beschäftigen.
Anschließend an diesen Beitrag kannst Du in einem kleinen Quiz Dein neues Wissen über SEO und UX testen!
User Experience und SEO, was ist das überhaupt? Zunächst schauen wir uns die Definition beider Begriffe an. Anschließend wollen wir mit diesem Hintergrundwissen in das zentrale Thema, der Kombination von User Experience und SEO, einsteigen.
User Experience (UX)
User Experience einerseits, abgekürzt auch einfach UX, betrachtet die Nutzererfahrung auf allen Ebenen. Das bedeutet, alle Empfindungen und Reaktionen vor, während und nach der Nutzung eines beliebigen Produkts beeinflussen die User Experience.[1] In Verbindung mit SEO stehen in diesem Beitrag Webseiten und deren Gestaltung im Mittelpunkt. Das Ziel von UX-Expertinnen und UX-Experten ist, die Produktnutzung so angenehm und unterhaltsam wie möglich zu gestalten.
Ein weiterer, häufig gebrauchter Begriff im Zusammenhang mit Web Design ist Usability. Um User Experience zu verstehen ist es hilfreich, Usability erst einmal getrennt davon zu betrachten. Gemeint ist damit die Gebrauchstauglichkeit und somit Nutzerfreundlichkeit einer Webseite aus technischer Sicht. Demnach wird untersucht, ob alle Elemente ohne Komplikationen funktionieren und zu finden sind. Häufig fällt allerdings nur eine negative Usability auf, wie einigen Beiträgen zu diesem Thema zu entnehmen ist. Gute Gebrauchstauglichkeit hingegen bleibt eher unauffällig. Folglich sind keine Beschwerden bezüglich der Nutzbarkeit schon beinahe positiv zu bewerten.[2]
Im Gegensatz dazu ist für die Nutzererfahrung eine ganzheitliche Betrachtung von Bedeutung. Technische Aspekte wie die Gebrauchstauglichkeit spielen zwar auch eine Rolle, jedoch niemals die alleinige. Werden demzufolge ästhetische Gesichtspunkte und Emotionen im Einklang mit der technischen Nutzbarkeit gesehen, geht es um User Experience.[1]
SEO
SEO andererseits steht für Search Engine Optimization, auf Deutsch Suchmaschinenoptimierung. Dabei beschäftigt man sich mit der Verbesserung der Auffindbarkeit von Webseiten in Suchmaschinen. Darüber hinaus steht diese Abkürzung gelegentlich auch als Synonym für die Person eines Suchmaschinenoptimierers (SEO Manager).
Vereinfacht ausgedrückt beschreibt der Begriff User Experience die Menschensichtund SEO die Maschinensicht auf Web-Inhalte. Doch welche Gemeinsamkeiten gibt es zwischen diesen beiden Gestaltungseinflüssen?
Entwicklung von SEO
Das Ziel dieses Beitrags ist, wie zuvor erwähnt, Berührungspunkte von SEO und UX herauszustellen. Dafür schauen wir uns zunächst die Entwicklungsgeschichte von SEO an. Als Beispiel wollen wir uns im Folgenden auf Google beziehen. Wie unten abgebildeter Karte zu entnehmen ist, ist Google unangefochtener weltweiter Marktführer. Eine Ausnahme stellt China dar, mit seiner eigenen Suchmaschine Baidu.
Der weltweite Marktanteil von Google betrug im Januar 2021 91.86 % (s. o.). In Deutschland erreichte Google einen Anteil von 91.56 %. Als zweitgrößte Suchmaschine wird in Deutschland Bing genutzt (5.23 %). Weitere Suchmaschinen mit geringeren Anteilen sind Ecosia, DuckDuckGo oder Yahoo.[3]
SEO – Black Hat-Methoden
Die Reihenfolge (Ranking) in den Suchmaschinen-Trefferseiten (SERPs) wird anfangs in erster Linie von technischen und inhaltlichen Merkmalen beeinflusst. Markus Hübener hat diese beispielsweise in einem „9-Punkte-Optimierungsplan“ im Jahr 2009 beschrieben.[4] Auffälligerweise sind darin aber noch keine eindeutigen Kriterien für User Experience mit einbezogen.
Ursprünglich wurden also die Technik, der Inhalt (Content) und auch Verlinkungen als Basiskriterien für das Ranking herangezogen. Aus technischer Sicht sind dabei etwa die Ladegeschwindigkeit und Indexierbarkeit durch Webcrawler zu beachten. Als inhaltliche Aspekte sind dafür vor allem die Semantik und Suchwörter (Keywords) heranzuziehen. Bei den Links sind dann Rückverweise auf die eigene Webseite (Backlinks) von besonderem Interesse.[5] Die Kenntnis darüber führt jedoch auch zu bewussten Manipulationen von Webseiten, um ein hohes Ranking in der Ergebnisliste zu erzielen. Unerlaubte Optimierungsarten dabei werden auch Black Hat genannt. Im Gegensatz dazu werden erlaubte Taktiken als White Hat bezeichnet.
Folgende Verfahren können wir zu den Black Hat-Methoden zählen:
Reaktionen von Google auf unerwünschte SEO
Um betrügerisches Verhalten aufzudecken entwickelt Google seine Algorithmen stets weiter. Infolgedessen werden überoptimierte Webseiten durch Verbannung von den hohen Rankingplätzen abgestraft. Zu den dazu gehörigen Meilensteinen zählt das sogenannte „Panda-Update“ im Jahr 2011. In Bezug auf die Content Farmen war es anfangs auch als „Farmer Update“ bekannt. Darauf folgte ein besonders wichtiges Update aus dem Jahr 2015, genannt „RankBrain“. Seitdem beeinflusst es vor allem die Sprachsuche unter erstmaligem Einsatz von Machine Learning. Nicht zuletzt verbesserte Google mit dem „Fred-Update“ im Jahr 2017 den Bewertungsalgorithmus für die Inhaltsqualität von Webseiten erneut.[6], [7]
Das Thema im Rat der Europäischen Union Ende 2020 war „Verschlüsselung von online Kommunikation“. Der Rat der EU diskutiert, wie z. B. E-Mails, WhatsApp Nachrichten oder Snaps von einem internetfähigen Gerät zum anderen gelangen. Eine Geschichte über die Crypto Wars.
„Da gibts doch nichts großes zu diskutieren“, würde jetzt manch einer sagen. „Ja, irgendwie werden diese Bilder und Texte in Einsen und Nullen umgewandelt und dann äähm… einfach zum Empfänger geschickt“. Meist schließt die Person den Satz mit einem selbstsicheren Gesichtsausdruck. Dieser Gesichtsausdruck geht dann zu einem Altklugen über, sobald die Leute drum herum murmelnd ihre Zustimmung bekunden.
Bei dieser schwammigen Aussage wurde auch nichts Falsches behauptet. Nur ein falsches Bild von online Kommunikation und deren Komplexität wird vermittelt.
Das falsche Bild ensteht bei den Worten „einfach zum Empfänger geschickt“. Darunter kann man sich vorstellen, dass Nachrichten auf einer direkten Linie zwischen den zwei Smartphones gesendet werden. So ist es dann auch selbstverständlich, dass der Rest der Welt nichts von der Kommunikation mitbekommt.
Dieses Bild ist aber komplett irreführend. Die Nachricht, die dann auf dem Gerät des Empfängers aufploppt, ist nur die Ziellinie einer langen Strecke die in Sekunden zurück gelegt wird.
Wenn wir Alice zum Beispiel eine WhatsApp Nachricht an Bob verschicken lassen, könnte es sein, dass die Nachricht zu einem Server in Grönland oder in den USA weitergeleitet wird. Und das alles in Sekunden. Auf all den Zwichenstationen, die auf dem Weg liegen (z.B. Routern und Switches) kann die Nachricht abgegriffen werden. (vgl. Snowden 2019)
Eine Modell einer online Kommunikation am Beispiel WhatsApp.
Das ist dann so als ob der private WhatsApp Chat von Alice und Bob noch einen weiteres Mitglied hätte namens Eve. Und dabei wissen Alice und Bob nichts von Eve. Gegen das Abgreifen von Daten kann man sich bei so einem komplexen Sytem nur schwer wehren. Aber man kann dafür sorgen, dass die Informationen in den falschen Händen wie Kauderwelsch aussehen. Mithilfe von Verschlüsselung.
Um unrechtmäßigen Zugriff auf private Kommunikation zu verhindern, gibt es Kryptographie. Kryptographie kommt aus dem Altgriechischen und bedeutet so viel wie „Geheimschrift“ bzw. „Verschlüsselung“. Obwohl sie in der modernen IT-Welt nicht mehr weg zu denken ist, sind Geheimschriften nichts Neues. Selbst Leonardo da Vinci dokumentierte mithilfe einer Geheimschrift (Spiegelschrift) seine Forschungen. (vgl. Wikipedia 2020)
Eine Doppelseite aus Leonardo da Vinci’s Büchern. Geschrieben in Spiegelschrift (vgl. Wikipedia 2020)
Nach dem römischen Schriftsteller Sueton nutzte der Feldherr Gaius Julius Cäser eine Geheimschrift für militärische Korrespondenzen. Diese Geheimschrift ist heute als Cäsar Chiffre bekannt. Aus dem Namen „Gaius“ wird dann „Hbjvt“. Der Algorithmus dahinter ist einfach, wenn man ihn kennt. Jeder Buchstabe wird um eine Stelle verschoben. Aus „a“ wird „b“ aus „b“ wird „c“, … aus „z“ wird wieder „a“. Somit konnte kein Aussenstehender, der den Brief abfing, etwas damit anfangen. (vgl. Wikipedia 2021) Mit der Außnahme, er kennt den Algorythmus und den Schlüssel. Der Algorythmus ist bei der Cäsar Chiffre die Verschiebung von den Buchstaben. Und der Schlüssel ist im obigen Beispiel, mit dem Namen „Gaius“ -> 1.
#https://gist.github.com/nchitalov/2f2b03e5cf1e19da1525
def caesar_encrypt(klartext, schluessel):
outText = []
cryptText = []
lowercase = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
#Durch jeden Buchstaben durchlooben und um n Schritte Verschieben
for eachLetter in klartext:
index = lowercase.index(eachLetter)
crypting = (index + schluessel) % 26
cryptText.append(crypting)
newLetter = lowercase[crypting]
outText.append(newLetter)
return outText
#Vordefinierte Funktion ausführen
#Mit dem Klartext 'Gaius' und dem Schlüssel 2
geheimtext = caesar_encrypt('Gaius', 2)
#Ergebnis der Funktion ausgeben
print(geheimtext)
Vielleicht erscheint einem der Algorythmus anspruchsvoller als der Schlüssel. Der Schlüssel ist aber viel wichtiger und entscheidet darüber, wie sicher eine Verschlüsselung ist.
Bei der Cäsar Chiffre werden die Buchstaben um je x Stellen verschoben. Das deutsche Alphabet besteht ohne Umlaute und Sonderzeichen (z. B. ß) aus 26 Buchstaben. So kann der Schlüssel 26 verschiedene Werte annehmen. All diese 26 Möglichkeiten kann ein Computer in Sekunden ausprobieren. Und so die Verschlüsselung in Sekunden knacken. Das nennt man dann „Brute Force“. (vgl. heise online 2021)
Wenn wir einen „Brute Force“ bei aktuellen Verschlüsselungs-Algorythmen anwenden, z.B. RSA mit einem 512-Bit Schlüssel, dann müsste der Computer dann 2512 Möglichkeiten durchprobieren.
Schon bei einer 256-bit Verschlüsselung gibt es 115,792,089,237,316,195,423,570,985,008,687,907,853,269,984,665,640,564,039,457,584,007,913,129,639,935 bzw. 2256 mögliche Schlüssel
Wenn wir davon ausgehen, dass jedes Atom im Universum ein Computer ist und jeder in einer Millisekunde einen möglichen Schlüssel ausprobiert, dann benötigt man mit der „Brute Force“ Methode mehr als 10211 Jahre. Das ensptricht ein vielfaches der Lebenszeit des Universums (13,75*109 Jahre). (vgl. Stack Exchange Inc. 2015)
Das Entschlüsseln entwickelt sich aber auch stetig weiter. Das kryptographische Verfahren RSA verwendet teilweise noch 1024-bit Schlüssellängen. Aber solche Schlüssel sind mittlerweile mit spezieller Software zu knacken. Dafür benutzt die Software statistische Verfahren und muss nicht wie beim „Brute Force“ 21024 Möglichkeiten ausprobieren. Deswegen gelten momentan 2048-Bit Schlüssel und 4096-Bit Schlüssel als sicher. Diese Schlüssel werden zum Beispiel bei vielen Webseiten, die https (Hyper Text Transfer Protocol Secure) benutzen, verwendet. (vgl. PC-Welt 2014)
Das sind die Basics zum Thema Verschlüsselung. Bei modernen Verschlüsselungverfahren werden weitere Hürden aufgestellt um das Entschlüsseln zu erschweren.
Eine Entschließung vom Rat der EU ist eine Art Stellungnahme von den aktuellen Regierungen der EU-Mitgliedsstaaten. Der Titel des vierseitigen Dokuments lautet „Sicherheit durch Verschlüsselung und Sicherheit trotz Verschlüsselung“. Diese Gegensätzlichkeit im Titel zieht sich mehr oder weniger im ganzen Dokument durch. In sieben Kapiteln fordert der Rat der EU einen „Regelungsrahmen zu entwickeln“. Der einerseits den Behörden ermöglichen soll „ihre operativen Aufgaben wirksam zu erfüllen und andererseits die Privatsphäre, die Grundrechte und die Sicherheit der Kommunikation zu schützen“. Der Rat pocht auf Innovation mithilfe der Technologiebranche, Forschung und Wissenschaft. (vgl. Rat der EU 2020)
Diese Debatte zieht sich jetzt schon seit Jahren hin. Crypto War 1.0, Crypto War 2.0 u.s.w. Der sogenannte „Crypto War“ begann in den 1990er-Jahren. In dieser Zeit wurde nach Möglichkeiten gesucht, den Zugang zu verschlüsselter Kommunikation für Strafverfolgungsbehörden zu vereinfachen. (vgl. heise Online 2020a)
Begonnen hat der „War“ in den USA. Dort wurde dem Senat ein Gesetzesentwurf vorgelegt, um den Strafverfolgungsbehörden Zugriff auf die verschlüsselte Kommuikation von Nutzern zu verschaffen. Zusätzlich machte die NSA (National Security Agency) den Vorschlag, dass alle Hersteller von Telefonanlagen den von der NSA selbst entwickelten Clipper Chip zur Verschlüsselung einsetzen müssen. (vgl. Tresorit Team 2016)
Bei diesem Chip handelt es sich um ein im Jahre 1993 entwickeltes symmetrisches Verschlüsselungssystem. Der sogenannte Escrowed Encryption Standard (EES) ermöglicht den Zugriff auf verschlüsselte Kommunikation mithilfe von zwei Schlüsseln. Einer ist bei den Behörden hinterlegt. Und der Andere wird nur auf richterliche Anordnung freigegeben. Nach nur drei Jahren wurde das Projekt aufgrund von zahlreichen Protesten eingestellt. (vgl. Tresorit Team 2016)
Als Backdoor wird eine absichtlich eingebaute Verschlüsselungs-Hintertür bezeichnet. Praktisch wäre es dann ein Schlüssel, mit dem man eine bestimmte Verschlüsselung immer knacken kann. Momentan sind diese Backdoors eine Möglichkeit das Ziel „Sicherheit durch Verschlüsselung und Sicherheit trotz Verschlüsselung“ zu erreichen. Diese Methode sorgt aber für heftige Kritik. Die Bitkom, der Digitalverband Deutschlands, kritisiert die Hintertüren. Backdoors seien nicht dauerhaft kontrollierbar und eine Einladung für Kriminelle und ausländische Nachrichtendienste. (vgl. bitkom 2020)
Juniper bietet Internetinfrastruktur für Unternehmen an. Von Produkten wie WiFi-Router bis hin zu Cloud Diensten. (vgl. Juniper Networks Inc. 2021) Ende 2015 began der Skandal rund um den US-Konzern Juniper. Der Netzausrüster hatte auf Verlangen der NSA eine Hintertür in seinem Betriebssystem ScreenOS eingebaut. Ende Oktober 2020 gab Juniper dann gegenüber dem US-Kongress zu, dass die Hintertür von einem anderen Staat übernommen wurde und so die NSA ausperrte. Ermittler gehen davon aus, dass es sich um China handelt. Das ist ein perfektes Beispiel dafür, wie Hintertüren nach hinten los gehen können. 😀 (vgl. heise Online 2020b)
Am 11. Januar 2021 antwortete die EU-Innenkommissarin Ylvy Johansson auf einen Brief von drei liberalen EU-Abgeordneten. Thema des Briefes waren Backdoors. In der Antwort der EU-Innenkommissarin schließt sie Hintertüren, um Zugriff auf verschlüsselte Daten zu erlangen, aus. (vgl. STANDARD Verlagsgesellschaft m.b.H. 2021)
Sinnbildliche Darstellung einer Backdoor, dessen Zugang geheim ist.
Bis jetzt existieren noch keine ausgeglichenen Technologien, um online Kommunikation für Dritte zu verschlüsseln, aber für Strafverfolgungsbehörden doch wieder zu entschlüsseln. Bei diesem Diskurs, der nun schon über 20 Jahre andauert, werden nur langsam Meilensteine erreicht.
Die EU-Mitgliedsstaaten haben sich dafür entschieden, dass Verschlüsselung wieder mehr Aufmerksamkeit gewidmet werden soll. Der richtige Weg dafür soll Innovation sein. Eine Innovation, die auf dem Wissen und den Interessen von Wirtschaft, Wissenschaft und Politik entsteht.
Am Ende betrifft eine solche Innovation aber jeden Einzelnen und jede WhatsApp Nachricht eines jeden Einzelnen. Und auch wenn es „Nerds“ sind, die diese Algorythmen entwickeln, sollte jedem bewusst sein wieprivat seine online Kommunikation sein soll und ist.
PC-Welt (2014): Verschlüsselung – Was ist noch unknackbar?. RSA. Zuletzt aktualisiert am 06.08.2014. Online unter Was_ist_noch_unknackbar-Sicherheits-Check-8845011.html [Abruf am 30.01.2021]
Tresorit Team (2016): Crypto Wars: Seit 40 Jahren das alte Lied. Zuletzt aktualisiert am 30.11.2016. Online unter https://tresorit.com/blog/de/40-jahre-crypto-wars/ [Abruf am 25.01.2021]
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2020/21, Prof. Dr.-Ing. Steinberg) entstanden. Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Flask ist ein WSGI Micro-Framework für Webapplikationen. Ursprünglich wurde Flask als Aprilscherz von Armin Ronacher im Jahr 2010 entwickelt. Auf Grund steigender Beliebtheit unter den Usern, gründete Armin Ronacher die „The Pallets Project“-Sammlung von Open Source Code Bibliotheken. Diese Sammlung dient nun als Organisation hinter Flask und weiteren Bibliotheken wie Werkzeug und Jinja, um die Flask aufgebaut ist. Dabei stützt sich Flask nur auf die nötigsten Komponenten die für die Webentwicklung benötigt werden ( routing, request handling, session). Alle anderen Komponenten müssen dementsprechende entweder selbst entwickelt oder über zusätzliche Pakete hinzugefügt werden.[1]
Was Flask so außergewöhnlich macht ist der simple Einstieg und die Effizienz im Zusammenspiel mit anderen Python Bibliotheken. Was dem Entwickler erlaubt Web-Applikationen mit Flask im größeren Stil zu entwickeln und auszubauen, ohne dem Entwickler etwas aufzuzwingen. Da die „The Pallets Project“-Sammlung sich einer großen Unterstützer Community erfreut, gibt es viele Erweiterungsmöglichkeiten welche die Funktionalität erhöhen und Flask äußerst flexibel werden lässt.[2]
Wie das Micro-Framwork Flask funktioniert soll in den folgenden Teilen dieses Beitrags deutlich werden. Sei es die simple installation, oder die einfach Handhabung.
Installation
Wie einfach es ist mit Flask eine Web-Applikation mit Flask zu erstellen soll in den folgenden Abschnitten deutlich werden.
Des Weiteren bietet es sich an beim Entwickeln einer Flask Web-Applikation eine virtuelle Entwicklungsumgebung wie Pythons hauseigene virtualenv zu verwenden um Projektabhängigkeiten und Bibliotheken für jedes Projekt entsprechend zu verwalten. Außerdem ermöglicht die virtualenv eine schnelle und einfach Portierung bzw. ein schnelles unkompliziertes Deployment einer Applikation.
Wie Pythons virtuelle Entwicklungsumgebung funktioniert ist hier näher beschrieben „virtualenv“.
Um Flask zu installieren kann man einfach „pip“ benutzen. Dies ist der Package Installer für Python:
$ pip install Flask
So einfach lässt sich Flask installieren mit seinen benötigten Paketen installieren.[3]
Hello World!
Wie einfach das erstellen einer Web Applikation mit Python und Flask ist soll an einem simplen „Hello World“ Beispiel verdeutlicht werden. Dazu wird die Datei „app.py“ angelegt. Diese lässt sich einfach mit einem Texteditor öffnen und bearbeiten (z.B. PyCharm oder VS Code).
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return "Hello World!"
if __name__ == '__main___':
app.run()
Zur Erklärung: In Zeile 1 importieren wir Flask und in initieren in Zeile 3 eine neue Instanz der Flask-Klasse und weisen sie der Variable „app“ zu. In Zeile 5 wird ein „Decorator“ benutzt um die Route/View „/“ der View-Funktion „index()“ zuzuweisen. Also einfach gesagt: Wird die Seite „/“ des Servers im Browser angefragt, so führt dieser die View-Funktion aus die den Content „Hello World!“ bereitstellt.[4]
Der letzt Abschnitt des Codes startet den Server sobald die Datei für den Interpreter aufgerufen wird. Wenn alles richtig installiert ist sollte nun folgender output zu sehen sein:
(webapp) $ py app.py
* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
Die im Code erstellte Seite „/“ mit der „index()“-Funktion lässt sich einfach über den Webbrowser öffnen. Dazu lediglich in der Adresszeile des Browser auf „http://localhost:5000/“ oder „http://127.0.0.1:5000/“ aufrufen. Die aufgerufene Seite sollte nun „Hello World!“ in der linken oberen Ecke zeigen.
Routing and Views
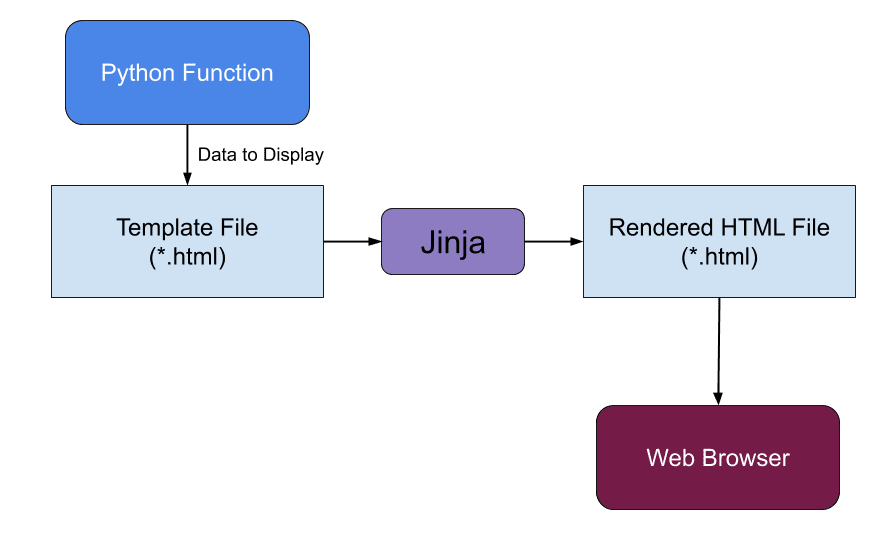
Routing bezeichnet das auflösen und händeln von URLs. Dabei soll beim aufrufen einer URL der korrekte Inhalt im Browser dargestellt werden. Bei Flask wird dies mit dem Route- „Decorator“ eine Funktion an eine URL gebunden um ihren Content nach dem Aufrufen der URL bereitzustellen. Das folgende Bild soll den Ablauf der URL Auflösung und dem damit verbunden bereitstellen von Content verdeutlichen.[5]
Im vorangegangenen Hello World Beispiel wird dies in Zeile 5 und 6 gemacht. Nach dem aufrufen der URL „http://localhost:5000/“ sollte in der Konsole/der Shell folgendes zu sehen sein:
(webapp) $ py app.py
* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
127.0.0.1 - - [29/Jan/2021 11:56:33] "GET / HTTP/1.1" 200 –
Es ist zu sehen das der Browser eine Anfrage für die „/“-Route an den Server stellt. Dieser verarbeitet die Anfrage entsprechend der mit der Route verbundenen View-Funktion „index()“. Im Anschluss sendet der Server http-status: 200 (OK) und rendert „Hello World!“.
In der Konsole stehen sämtliche Anfragen und http-status codes die vom Flask-Server verarbeitet werden.
Routen und http-Methoden:
Der „Decorator“ kann ein weiteres Argument annehmen. Dieses Argument ist eine Liste mit den für den „Decorator“ erlaubten http-Methoden.
Somit lassen sich Routen in der Nutzung bestimmter http-Methoden einschränken. Ist jedoch keine Liste angegeben so ist die „GET“-Methode als Standard festgelegt.
Mithilfe der „Decorator“ lassen sich auch dynamische und variable Regeln für Routen festlegen, da statische Routen eine Website stark einschränken können. So lässt sich im folgenden Beispiel eine Profilseite für registrierte User anlegen oder gepostete Artikel/Beiträge bekommen eine eigene URL basierend auf dem Datum an dem sie Online gestellt worden und ihrem Titel.
Dabei geben die „<>“ an ob es sich um eine Variable handelt. So lassen sich Routen dynamisch generieren. Zusätzlich lässt sich der Variablen-Typ angeben der verarbeitet werden soll „<datatype:variablename>“. Folgende Variablentypen sind für Routen vorgesehen und möglich:
string: Akzeptiert Text ohne „/“.
int: Akzeptiert ganze Zahlen (integers).
float: akzeptiert numerische Werte die einen Dezimalpunkt enthalten.
path: Akzeptiert Text mit „/“ (Pfadangaben)
Dynamische Routen können dementsprechend im Gegensatz zu statischen Routen Parameter entgegennehmen und verarbeiten. Somit ließe sich auch eine API mit Flask umsetzen um Daten für User zugänglicher und nutzbarer zu machen oder einen erhöhten Automatisierungsgrad für Datenabfragen zu ermöglichen. Um dies deutlich zu machen dienen die folgenden Beispiele:[6]
So einfach diese Beispiele sind, so geben sie doch einen deutlichen Ausblick auf die Möglichkeiten, welche sich mit Flask bieten. Welche Unternehmen Flask in ihrer Entwicklung benutzen kann hier eingesehen werden.
Die Template Engine
Wie werden jetzt aus statischen HTML-Dateien dynamische Websiten mit Flask? Ganz einfach, mit Hilfe der eingebauten Template Engine Jinja. Jinja ist eine vielseitige und einfache Templete Engine mit der sich unter anderem auch dynamische HTML-Inhalte erstellen lassen. Sie basiert dabei auf der „Django“ Template Engine bietet jedoch viel mehr Möglichkeiten wie volle „unicode“ Unterstützung und „automatic escaping“ für mehr Sicherheit in Webanwendungen. Zusätzlich lassen sich die gängisten verwendeten Codeblöcke der html-templates immer wieder verwenden und vielseitig einsetzen. Dabei verwendet die Template Engine Variablen, Ablauflogiken und Anweisungen um im Template verwendete Ausdrücke mit Inhalt zu füllen.[7]
Funktionsweise Template Engine Jinja
Um das ganze noch mehr zu veranschaulichen dient der folgende Beispiel Code mit der angegeben Projektstruktur:
from flask import Flask, escape, render_template
app = Flask(__name__)
# Routes and Views:
@app.route("/")
def home():
return render_template('index.html')
@app.route("/about/")
def about():
return render_template('about.html')
@app.route("/page1/")
def page1():
return render_template('page1.html')
# run flask server:
if __name__ == '__main__':
app.run()
Wird der Server nun gestartet und im Browser die einzelnen Seiten der Applikation aufgerufen werden die html-templates für die entsprechende Seite gerendert.
Die Möglichkeiten zum nutzen von Templates sind schier endlos für Flask und bieten viel Raum für eigene Ideen und Umsetzungsmöglichkeiten in der Webentwicklung.
Fazit
Flask ist eine tolle Möglichkeit zum Einstieg in die Webentwicklung und bietet vielseitige Umsetzungsmöglichkeiten für Applikation, Websites oder APIs. Zudem ist es einfach zu lernen. Die dahinter stehende Community, die Umfangreiche Dokumentation, die Möglichkeit jedes Python Package miteinzubeziehen und die Masse an Tutorials bieten viel Raum um sich, Flask und die eigene App zu entwickeln/weiterzuentwickeln. Ohne das Flask dabei den Entwickelnden Rahmenbedingungen aufzwingt. Zusätzlich ist Lernkurve recht klein und der Entwickler wächst schnell in die Anforderungen und Möglichkeiten hinein.
Stender, Daniel (2017): Tropfen um Tropfen. In: Entwickler Magazin, Jg. 2017, H. 6. Online unter: https://kiosk.entwickler.de/entwickler-magazin/entwickler-magazin-6-2017/tropfen-um-tropfen/ [Abruf am 10.01.2021]
Stender, Daniel (2017): Tropfen um Tropfen. In: Entwickler Magazin, Jg. 2017, H. 6. Online unter: https://kiosk.entwickler.de/entwickler-magazin/entwickler-magazin-6-2017/tropfen-um-tropfen/ [Abruf am 10.01.2021]
The Pallets Project (2020): Installation. Online unter https://flask.palletsprojects.com/en/1.1.x/installation/ [Abruf am 04.01.2021]
The Pallets Project (2020): A minimal application. Online unter https://flask.palletsprojects.com/en/1.1.x/quickstart/#a-minimal-application [Abruf am 04.01.2021]
The Pallets Project (2020): Routing. Online unter https://flask.palletsprojects.com/en/1.1.x/quickstart/#routing [Abruf am 04.01.2021]
The Pallets Project (2020): Variable Rules. Online unter: https://flask.palletsprojects.com/en/1.1.x/quickstart/#variable-rules [Abruf am 04.01.2021]
The Pallets Project (2020): Templating. Online unter: https://flask.palletsprojects.com/en/1.1.x/templating/ [Abruf am 04.01.2021]
Alle Codebeispiele sind selbst erarbeitet und getestet.
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2020/21, Prof. Dr.-Ing. Steinberg) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Cloudbasierte Bibliothekssysteme gelten als die neue Generation von Bibliotheksverwaltungssystemen. Sie bieten eine innovative Möglichkeit, wie Bibliotheken ihre zahlreichen Daten verwalten und täglichen Geschäftsgänge möglichst einfach abwickeln können. Mittlerweile werden sie auch in Deutschland immer häufiger eingesetzt. So arbeiten die Berliner Universitätsbibliotheken bereits seit 2015 mit einer solchen Software.1 Auch in Nordrhein-Westfalen läuft aktuell ein Projekt mit dem Ziel, alle Hochschulbibliotheken auf ein cloudbasiertes Bibliothekssystem umzustellen.2 Aber sind sie tatsächlich besser als bereits existierende Bibliotheksverwaltungsprogramme? Dieser Beitrag versucht der Frage nachzugehen, indem einige Vor- und Nachteile cloudbasierter Systeme erläutert und gegenübergestellt werden.
Traditionell ist die Arbeit mit einem Computer auf Hardware, wie zum Beispiel Monitor und Tastatur, angewiesen. Dazu gehören auch Festplatten und Speicherkarten, auf denen Software gespeichert und ausgeführt wird. Das bedeutet, dass sowohl Hard- als auch Software für den Betrieb der herkömmlichen Bibliothekssysteme vor Ort benötigt werden. Um die Daten für alle zugänglich zu machen, werden außerdem lokale Server als Speicherort benötigt. 3
Eine Cloud ist mehr als nur ein Speicherort für Daten
Bislang ist eine Cloud meist in ihrer Funktion als Speicherort für Medien, wie beispielsweise Fotos, bekannt. Doch eine cloudbasierte Software bietet noch mehr: nicht nur die Speicherung der Daten, sondern alle Arbeiten finden darüber statt. Ein Anbieter stellt einen Server, und die Software zur Verfügung. Der Zugriff erfolgt über einen Webbrowser. Somit reicht im Grunde ein Smartphone mit Internetzugang, um eine ganze Bibliothek zu verwalten. Damit wird viel Hardware überflüssig, vor allem lokale Server können eingespart werden. Dieses Konzept wird auch als „Software-as-a-service“ bezeichnet.4
Computer waren früher ernsthafte Geräte für ernsthafte Arbeit und demnach auch nicht sehr einfach zu bedienen oder zugänglich.6 Der 1981 erschienen IBM 5150 startete bei einem umgerechneten Preis von ca. 4.400$ und kam dabei nicht mal mit einem Diskettenlaufwerk. Laden und Speichern von Programmen und Daten war so nur über Audiokassetten möglich. Eine sehr langsame und schmerzhafte Erfahrung. Warum man also als Privatperson einen Computer kaufen sollte war fragwürdig. Die rein Textbasierte Interaktion mit dem Gerät schreckte ebenfalls ab und nur technisch versierte Menschen könnten mit einem solchen Gerät etwas anfangen.11
Was ist also mit dem Rest der Menschen?
Ein neuer Weg
1984 kam eine andere Idee des Computers auf dem Markt. Es sollte ein freundliches Haushaltsgerät sein. Leicht zu bedienen und günstig. Dabei aber leistungsfähiger als andere Rechner. Ein Computer der Informationen ausspuckt wie ein Toaster geröstetes Brot.4 Die Rede ist von dem Macintosh von Apple. Der erste erschwingliche Heimcomputer mit grafischer Benutzeroberfläche und einem Zeigegerät namens Maus.
Anstatt Textbefehle einzugeben, konnte man nun einfach auf Ordner und Dateien zeigen, um sie zu öffnen oder zu verschieben. Textdokumente sahen auf dem Bildschirm so aus wie aus dem Ausdruck. Jalousie-Menüs machten die Arbeit einfacher.12 Alles Dinge die man heute von allen Computern kennt. Sie wurden auf dem PC allerdings erst ein Jahrzehnt später zum Standard.7 Der erste Mac war allerdings kein Erfolg. Schlicht zu teuer war er und nicht genug Software war auf dem Markt. 499$ war der Preis den Steve Jobs angedacht hatte. Daraus wurden dann aber 2.495$.12
Besser als ein Notebook, besser als ein Smartphone?
Was ist also aus der Idee des Informationstoasters geworden? Die Welt brauchte wohl noch ein bisschen. Apple probierte es 2010 nochmal mit einer ähnlichen Idee und diesmal mit einem Preis von 499$. Die Rede ist vom iPad. Ein Gerät, das bei seiner Vorstellung im Publikum für Verwirrung gesorgt hat. Die doch sehr zurückhalten Reaktion sind den Zuschauern deutlich anzuhören.2
Von der Presse wird die Daseinsberechtigung eines solchen Gerätes in Frage gestellt. Es sei doch nur ein großes iPhone ohne Telefon und ohne Computer kann man das Ding ja auch nicht einrichten.8 Für wen soll das also gut sein? Das iPad entspricht den ursprünglichen Ambitionen des Macintoshs besser als dieser es jemals konnte. „If you know how to point, you already know how to use it. “, so hieß es in einem Werbespot für den Mac von damals.5 Beim iPad kann man jetzt direkt auf den Bildschirm zeigen und braucht keine Maus mehr.
Das iPad von vornUnd einmal von hinten. Ganz schön wuchtig aus heutiger Sicht.
Die Idee Tablet Computer existierten schon lange als Idee in den Köpfen von Sci-Fi Autoren. Eines der ersten Auftritte im Kino hatte das Tablet in Stanly Kubriks 2001: Odyssee im Weltraum aus dem Jahr 1968. Hier wurde ein Tablet verwendet, um einen Videoanruf vom Raumschiff Odyssee zur Erde herzustellen.14 Das iPad hat den Tablet PC nicht erfunden und es gab eine mannigfaltige Auswahl solcher gerate in den 90ern und 2000ern. So auch den Dauphin DTR-1 von 1993. DTR steht hierbei für Desktop-Replacement. Ausgestattet mit Windows 3.1 for Pen Computing und einem Intel 386 Prozessor im inneren stand der Arbeit nichts im Wege. Bis auch das häufig schmelzende Netzteil vielleicht. Das hat mich jedenfalls bisher abgehalten.13 Desktop Arbeitsumgebungen in Tablet Form zu pressen ist wohl ein anderer Grund. Es bedarf einer grundlegen neuen Bedienung, um eine Vernünftige Nutzererfahrung zu schaffen. Und das Internet fehlte damals auch noch.
Meine Erfahrung
Mein Vater kaufte das iPad direkt als es in Deutschland auf den Markt kam. Es übte eine eigenartige Faszination auf mich aus. Das iPad träumte großer als der Macintosh es sich jemals vorstellen konnte. Alles wollte alles sein und das zeigte sich auch. Ein Webbrowser, eine E-Mail-Maschine und Unterhaltungsgerät, aber auch so einige etwas absurdere Einsatzwecke waren angedacht. So kann man vom Sperrbildschirm aus eine Diashow starten und das Gerät zusammen mit dem Dock als digitalen Bilderrahmen verwenden. Mit dem eingebauten Line-Out im Dock kann man sein iPad mit der Stereoanlage verbinden und es so als Musikspieler verwenden. Mit dem AV-Kabel lässt sich das iPad auch an den Fernseher anschließen, um seine Verwandten mit Urlaubsfotos zu langweilen. Importieren kann man die Fotos mithilfe des 30-Pin-Dockconnenctor auf USB oder SD-Karten Adapters. Und wer längere Texte schreiben will, kann einfach eine Bluetooth Tastatur koppeln.
Der Digitale Bilderrahmen Modus. Wer braucht da noch echte Fotos…
All dieses Zubehör war in üblicher Apple Manier natürlich nicht mitenthalten, aber mein Vater hat sich alles gleich dazu bestellt. Es sollte sein neuer Heimcomputer sein und auch sein einziger. Das ist etwas was sich bis heute nicht geändert hat. Das iPad ist nicht mehr das gleiche, er ist jetzt bei seinem dritten, aber er hat traditionellen Computern den Rücken gekehrt. Größtenteils weil sie teurer und klobiger sind, aber vor allem weil sie schwieriger zu bedienen sind. Das ist etwas was mir schon so manches Mal aufgefallen ist. Wenn ich meine Eltern meinen Laptop vorsetze, um Ihnen etwas zu zeigen, kommt es häufig vor, dass sie den Finger heben und versuchen auf dem Display zu tippen. Das bringt nur Fingerabdrücke auf den Bildschirm, zeigt aber wie natürlich Touch-Bedienung geworden ist.
Der Computer ist tot, lange lebe der Computer!
Mobile Endgeräte machen den größten Teil des Internetverkehres aus. Klassische Computerumgebungen werden mehr und mehr zu einem Nischenmarkt für Entwickler und Professionelle.3, 10 Man hört selten am Esstisch jemanden davon reden, wie er seinen Arbeitsspeicher erweitert hat und nun endlich das neue Betriebssystem installieren kann. Oder wie man die Wärmeleitpaste seiner CPU erneuert hat, um die Temperatur im Betrieb zu senken. Die meisten wollen ein Gerät, das einfach funktioniert und das tut was es soll. Ohne irgendwelche Erweiterungen oder Instandhaltung. Und das ist genau das was Tablets bieten. Man kann und muss sich um nichts kümmern. Das Gerät an sich steht im Hintergrund und der Content im Vordergrund. Das beeinflusst dann auch unseren Umgang mit den Inhalten.
Ein prominentes Beispiel dafür ist der Tod des Flash Players von Adobe. Lange Zeit ein unverzichtbares Werkzeug bei der Erstellung von Webinhalten, ist dieses Jahr endgültig von Adobe eingestellt worden. Ab den 01.02.2021 ist sogar das reine Ausführen des Programms von seitens Adobe blockiert, wenn es noch auf dem Rechner installiert ist.1 Ein Grund für den Untergang von Flash war zu keinem kleinen Teil die sture Verweigerung Flash auf iOS Geräte zu bringen. Steve Jobs hatte seine Gründe damals in einem offenen Brief geäußert.9 Wenn Websites heutzutage keine mobile Version aufweisen, können sie als kaputt und nutzlos betrachtet werden. Ob es einem gefällt oder nicht, wir leben in der Zeit nach dem Computer.
4 Dernbach, Christoph (o.J.): The History of the Apple Macintosh. Online unter [Abruf am 29.01.2021]
5 epicyoutubevideos (2015): Old macintosh ads (1984-85). Video publiziert am 11.08.2015 auf YouTube. Online unter https://youtu.be/JkU3WCSGSw4 [Abruf am 29.01.2021]
7 Long, Tony (2011): Aug. 24, 1995: Say Hello to Windows 95. Zuletzt aktualisiert am 24.08.2014. Online unter https://www.wired.com/2011/08/0824windows-95/ [Abruf am 29.01.2021]
9 Shankland, Stephen (2010): Steve Jobs‘ letter explaining Apple’s Flash distaste. Apple’s CEO doesn’t like Flash. Here’s the full memo explaining why the company is keeping Adobe Systems‘ software off the iPhone and iPad. Zuletzt aktualisiert am 29.04.2010. Online unter https://www.cnet.com/news/steve-jobs-letter-explaining-apples-flash-distaste/ [Abruf am 29.01.2021]
11 Steve’s Old Computer Museum (2020a): IBM Personal Computer (PC). Zuletzt aktualisiert am 08.05.2016. Online unter http://oldcomputers.net/ibm5150.html [Abruf am 28.01.2021]
12 Steve’s Old Computer Museum (2020b): Apple Macintosh. Zuletzt aktualisiert am 08.05.2016. Online unter http://oldcomputers.net/macintosh.html [Abruf am 28.01.2021]
13 Steve’s Old Computer Museum (2020a): Dauphin DTR-1. Zuletzt aktualisiert am 08.05.2016. Online unter http://oldcomputers.net/dauphin-dtr-1.html [Abruf am 29.01.2021]
14 Wigley, Samuel (2019): Did Stanley Kubrick invent the iPad?. Zuletzt aktualisiert am 12.05.2019. Online unter [Abruf am 29.01.2021]
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2020/21, Prof. Dr.-Ing. Steinberg) entstanden.
Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Bibliotheken sind weit mehr als reine Aufbewahrungsorte für Medien aller Art. In diesem Beitrag zeigen wir, inwieweit sich Bibliotheken im Sinne von Smart Libraries weiterentwickelt haben und welchen Nutzen Kund*innen davon haben.
Der deutsche Duden führt für das Wort „Smart“ die Begriffe gewitzt und clever.[4] So wird das Wort “Smart” derzeit viel im Zusammenhang mit intelligenten und computergesteuerten Systemen benutzt. Es bestehen bereits sowohl Wörter wie Smarte Technologien als auch Smartphones, Smart Homes und Smart Cities. Doch unter Smart Libraries kann sich kaum jemand etwas vorstellen.
Um eine Vorstellung von einer Smart Library zu bekommen, schauen wir uns zuerst ein Modell von einer Smart City an:
Smart City Wheel
Boyd Cohen beschäftigt sich mit den Themen nachhaltige und intelligente Entwicklung von Städten und ist der Begründer des Smart City Wheel. Laut Cohen gliedert sich eine smarte Stadt in sechs Themenfelder: Mobilität, Bevölkerung, Umwelt, Regierung, Wirtschaft und Lebensraum.
Eine intelligente, smarte Mobilität legt den Schwerpunkt darauf, den Verkehr in den Städten billiger, schneller und umweltfreundlicher zu machen. Die Ziele sind zum einen die Steigerung der Effizienz und eine Verbesserung des Verkehres, der durch die Stadt führt und zum anderen wird gezielt in eine innovative Verkehrspolitik investiert. Folglich müssen neue Verkehrsträger gewonnen werden. Desweiteren muss der Personen- und Warentransport gefördert und die Belastung der Umwelt reduziert werden.
Für eine smarte Bevölkerung stehen die Auswahl des Berufes, die Chancen auf dem Arbeitsmarkt, die Berufsausbildung und auch lebenslanges Lernen für alle Altersgruppen im Vordergrund. Abgesehen davon sind sind wichtige Punkte die Integration, die persönliche Weiterentwicklung, die Steigerung des Wohlstands und die Stärkung der Gemeinschaft.
Das Thema smarte Umwelt beschäftigt sich mit einer grünen und umweltbewussten Stadt. Wichtige Punkte sind hierbei die Reduzierung der CO2-Emissionen, die Reduzierung von Müll und die Verwendung von erneuerbaren Energien. Die Regierung in einer smarten City setzt sich für die Zusammenarbeit und Interaktionen zwischen den Bürgern, den Unternehmen und der Verwaltung ein.
Das Ziel einer smarten Wirtschaft ist das innovative und nachhaltige Wachstum der Wirtschaft in einer Stadt. Die Attraktivität einer Stadt muss gesteigert werden, um neue Unternehmen, Geschäfte und Investoren dazu zu gewinnen und dadurch wiederum neue Arbeitsplätze zu schaffen. Ein smarter Lebensraum bietet den Menschen ein gut ausgebautes Gesundheitssystem und die Einbindung von allen Alters- und Bevölkerungsgruppen. Neue Technologien ermöglichen Sicherheit. Ein weiterer Aspekt ist ein breites Freizeit- und Kulturangebot zur Selbstverwirklichung und Stärkung der sozialen Kontakte.[1]
Wie finden Bibliotheken nun ihren Platz in einer Smart City und werden Smart Libraries? In ihrem Buch „Smart Libraries. Konzepte, Methoden und Strategien“ stellen die beiden Herausgeberinnen Linda Freyberg und Sabine Wolf eine Smart Map für Bibliotheken vor und geben Bibliotheken, die smarter werden möchten, neue Ideen mit auf den Weg. [8]
Smart Libraries – Wie sieht’s in der Praxis aus?
Die Umsetzungen von neuen, smarten Ideen sind von Bibliothek zu Bibliothek unterschiedlich. Einige Bibliotheken setzen den Fokus auf Nachhaltigkeit, die durch neue Technik erreicht werden kann. Die Universität Hildesheim ist mit ihrer Smart Library bereits 2012 gestartet. Das Energiemanagement der Universitätsbibliothek wird mit einem „Smart-Home-System“ gesteuert. Dieses System beinhaltet zum Beispiel Sensoren, die den Lichteinfall in einem Raum registrieren und den Beleuchtungsbedarf selbständig regeln. [7]
Auch die Bibliothek der technischen Universität (DTU) in Dänemark zeigt in dem folgenden Video, wie eine Smart Library aussehen kann:
In dem Video wird gezeigt, wie in der Bibliothek neue Technik eingesetzt wird. Sensoren gestalten die Arbeitsumgebung für die Student*innen, indem die Raumwärme oder die Beleuchtung der Anzahl der Personen im Raum angepasst wird. Eine App hilft den Student*innen das gesuchten Buch in dem Regal zu finden. Zusammen gefasst versteht sich die DTU als eine Umgebung, in der neue Technologien ausprobiert werden können.[3]
Die Teilhabe von Kunden*innen und das selbstständige Arbeiten wollen Makerspaces in Bibliotheken fördern. Ein Beispiel ist die Hoeb4U der Bücherhallen Hamburg oder der Makerspace der Sächsischen Landesbibliothek – Staats- und Universitätsbibliothek Dresden. In der Hoeb4U können nicht nur ein Häkelset oder Bastelmaterialien ausgeliehen werden, sondern es finden auch Veranstaltungen vor Ort statt.[2] In Dresden liegt der Fokus auf Technik, so kann ein 3D- Drucker oder eine Kamera ausgeliehen und vor Ort ausprobiert werden. Zugleich bekommen Nutzer*innen von Fachpersonal oder anderen Nutzer*innen Hilfe bei der Benutzung der Makerspaces.[6]
Fazit
Bibliotheken entwickeln sich ständig weiter und haben dabei die Bedürfnisse der Kund*innen fest im Blick. Der Anspruch an eine Bibliothek hat sich gewandelt. Einerseits möchten Kund*innen das Medienangebot einer Bibliothek nutzen, andererseits auch das Angebot an Veranstaltungen wahrnehmen und sich mit anderen Kund*innen austauschen und treffen. Die Kennzeichen einer Smart City spielen dabei eine wichtige Rolle: gemeinsam genutzte Räume senken die CO2 Emission und es findet ein Austausch zwischen unterschiedlichen Gruppen der Bevölkerung statt. Kund*innen haben die Möglichkeit sich aktiv einzubringen und durch niedrigschwellige Angebote werden Teilhabe und Inklusion gefördert.
Letztendlich stellt sich die Frage: Ist eine Bibliothek nicht von Anfang bereits eine Smart Library? Im Laufe ihrer Geschichte musste sie sich immer wieder an die Bedürfnisse ihrer Kund*innen anpassen und sich verändern – lange bevor das Wort Smart in Mode kam.
Verwendete Quellen
1bee smart city (2020): smart city indicators. Online unter https://hub.beesmart.city/en/smart-city-indicators [Abruf am 18.01.2021]
2Büchrhallen Hamburg (2021): Jugendbibliothek Hoeb4U.Konzept. Online unter: [Abruf am 15.01.2021]
3DTUdk(2018):DTU Smart Library-What is it? [Video]. Online unter: https://www.youtube.com/watch?v=qEc7_8xpdj4 [Abruf am 15.01.2021]
4Duden (2020): Wörterbuch. Online unter https://www.duden.de/rechtschreibung/smart [Abruf am 15.01.2021]
5Smart City Hub Switzerland (o. J.): Smart City Wheel. Online unter https://www.smartcityhub.ch/smart_city_wheel.120en.html [Abruf am 18.01.2021]
6SLUB Dresden (2021): SLUB Makerspace. Online unter https://www.slub-dresden.de/mitmachen/slub-makerspace/ [Abruf am 18.01.2021]
7Universität Hildesheim (2012): „Smart Library“ – Energieverbrauch senken durch intelligente Steuerungssysteme. Ein Vorhaben im Rahmen der „Sustainable University Hildesheim. Zuletzt aktualisiert am 25.08.2020. Online unter . [Abruf am 14.01.2021]
8Wolf, Sabine (2019): Definition einer Smart Library und Erläuterung der Smart Map. Ein State -of-the-Art Ansatz. In: Freyberg, Linda; Wolf, Sabine (Hg.): Smart Libraries. Konzepte,Methoden und Strategien. Wiesbaden: b.i.t. Verlag gmbh (b.i.t. online innovativ, Bd. 76), S. 21-26
Dieser Beitrag ist im Studiengang Informationsmanagement an der Hochschule Hannover im Rahmen des Kurses Content Management (Wintersemester 2020/21, Prof. Dr.-Ing. Steinberg) entstanden. Die besten Beiträge stellen wir Euch hier in den nächsten Wochen nach und nach vor.
Kommentare werden geladen …
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.