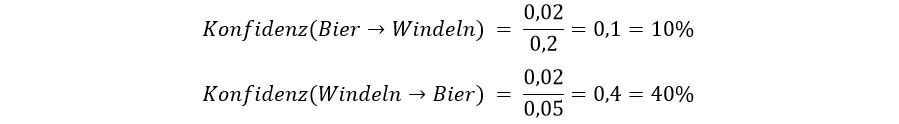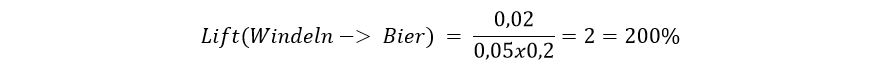Autor*in: Julia Solohub

SEO. Vielleicht bist auch du über diesen Begriff gestolpert, aber wusstest nie was er bedeutet. In diesem Beitrag versuche ich es dir mal zu erklären. Stell dir vor du würdest nach Informationen für deine Präsentation im Internet suchen. Wahrscheinlich suchst du dafür in Google so wie es die Mehrheit tut. Dazu gibst du deine Suchanfrage in die Suchmaschine ein und erhältst innerhalb weniger Sekunden eine Überflutung an Webseiten. Die Ergebnisse sind dann auf mehreren Seiten verteilt. Bestimmt ergeht es dir wie den meisten und du klickst die ersten Ergebnisse an. Doch wie schaffen es genau diese Webseiten auf den ersten Seiten einer Suchmaschine zu erscheinen? Dafür ist SEO verantwortlich. Aber was ist denn nun SEO? Und wie funktioniert es? Das erfährst du hier.
Orientierungshilfe
Definition von SEO
SEO ist die Abkürzung für Search Engine Optimization, zu Deutsch Suchmaschinenoptimierung. Es ist ein Teil des Suchmaschinenmarketings und wird für das Online Marketing angewendet. Dabei stehen das Erzielen von Umsatz, Steigerung der Popularität und der Besucherzahl sowie die Erhöhung der Reichweite im Fokus. Bei SEO werden Maßnahmen ergriffen, damit Webseiten und deren Inhalte in Suchmaschinen besser aufgefunden und als eine der ersten Treffer (Ranking) platziert werden. Dies gilt nicht nur für Webseiten, sondern auch für Bilder und Videos [4]. Hierfür werden verschiedene Rankingfaktoren beachtet und nach denen optimiert.

SEO wird in zwei Bereiche unterteilt: In die Onpage Optimierung und in die Offpage Optimierung. Im Folgenden wird zunächst auf die Onpage Optimierung und danach auf die Offpage Optimierung näher eingegangen
Onpage Optimierung
Unter Onpage Optimierung versteht man Maßnahmen der Suchmaschinenoptimierung, die auf der eigenen Webseite vorgenommen werden. Hierbei sollen die Faktoren Technik, Inhalt und Struktur der Webseite nach Suchmaschinenkriterien verbessert werden. In der Regel sind das Faktoren für Google [2]. „Ziel der Onpage Optimierung ist es vor allem, ein möglichst gutes Ranking in Suchmaschinen zu erreichen“ [8].
Rankingfaktoren der Onpage Optimierung
In diesem Abschnitt werden ein paar Beispiele für Rankingfaktoren aufgelistet.
Rankingfaktor Inhalt
„Einzigartige, aktuelle und hochwertige Inhalte beeinflussen diverse Rankingfaktoren und sind der Schlüssel zu einer hohen Kundenzufriedenheit“ [8]. Sie steigern die Verweildauer und senken die Absprungsrate [8].
Um guten Inhalt zu verfassen, muss man sich in die Sicht des Nutzers hineinversetzen. Daher müssen folgende Fragen beantwortet werden: Löst der Inhalt ein Problem? Ist er individuell gestaltet und geschrieben? Unterscheidet er sich zu anderen Webseiten? Wird überhaupt nach dem Problem gesucht?
Zu dem Inhalt zählt ebenfalls wie dieser strukturiert ist. Die Verwendung aussagekräftiger Überschriften spielt hierbei eine große Rolle. Als Hauptüberschrift der Webseite muss eine H1 Überschrift verwendet werden. Für Überschriften der zweiten Ordnung die H2 Überschrift und so weiter. Ebenfalls sollte der Text gut lesbar sein. Komplizierte Satzstruktur und Rechtschreibfehler sollten vermieden werden. Ebenfalls erleichtern Absätze dem Nutzer das Lesen. Des Weiteren muss auf die Formatierung geachtet werden. Wenn sie nötig ist, sollte sie eingesetzt werden wie z.B. bei Aufzählungen oder Tabellen. Ebenfalls ist für die Orientierung ein Inhaltsverzeichnis von Vorteil. Als positiv gewertet wird auch das Einbinden einer Interaktionsmöglichkeit. Das weckt das Interesse des Nutzers und bindet ihn in den Inhalt ein. Dies kann dazu führen, dass der Text somit verständlicher ist. Beispiele für Interaktionsmöglichkeiten sind ein Quiz am Ende des Textes oder freie Felder für Kommentare [9].
Für das Auffinden der Webseite müssen Keywords eingesetzt werden, die man bei der Suchanfrage verwenden würde. Diese müssen möglichst häufig im Text vorkommen. Dies gilt ebenfalls für die URL, bei der der Besucher sofort weiß, auf welcher Webseite er sich befindet und wovon diese handelt.
Damit sich die Verweildauer der Besucher erhöht, ist es gut Multimedia Elemente, wie Bilder oder Videos, auf deine Webseite zu platzieren [2]. Bei Bildern müssen einige Kriterien beachtet werden. Bilder müssen komprimiert und auf die richtige Größe zugeschnitten werden. Bei der Bildbenennung sollten Keywords sowohl im Titel als auch im Dateinamen enthalten sein. Hinzu kommt das Nutzen von Titel und ALT-Attributen, um das Bild zusätzlich zu beschreiben [9].
Rankingfaktor Technik
Die Inhalte deiner Webseite müssen gut lesbar sein. Dies bedeutet, dass die Webseite an mobile Endgeräte angepasst werden muss. Dazu zählen z.B. Handys und Tablets. Ebenso muss der Zugang zur Webseite gewährleistet sein (Barrierefreiheit). Weiterhin ist eine hohe Ladegeschwindigkeit wichtig, damit der Besucher auf der Webseite verweilt [2].
Studien haben gezeigt, dass die durchschnittliche Wartezeit beim Laden einer Webseite 3 Sekunden beträgt [1]. Also immer daran denken! Ebenfalls muss man an die Nutzerfreundlichkeit der Webseite denken. Das bedeutet jeder muss sich auf der Webseite gut zurechtfinden. Eine gute Navigation muss gegeben sein.
Des Weiteren helfen Interne Verlinkungen innerhalb einer Webseite nicht nur bei dem Zurechtfinden, sondern auch zur Nachverfolgung, wo man sich aktuell befindet. Dies kann man durch eine verlinkte Menüführung, Links zu Unterseiten oder Breadcrumbs erreichen. Breadcrumbs ist eine Unternavigation, die zur Orientierung dient. Dabei wird ein Pfad von Seiten angezeigt, die man durchklicken muss, um auf die aktuelle Seite zu gelangen. Solche Breadcrumbs wirken sich im Suchmaschinenranking bei Google positiv aus.
Je schneller ein Besucher die benötigte Seite auf einer Webseite erreicht, desto besser. Dies bedeutet, wenn der Benutzer durch wenig Durchklicken an sein Ziel kommt, wirkt es sich positiv auf das Ranking aus. Das heißt durch wenig Deep Links gelangt der User an sein Ziel [2].
⇒ „Richtwert: von der Homepage zur Zielseite in drei Klicks“[2].
Rankingfaktor Struktur
HTML Kenntnisse sind hier von Vorteil. Das Nutzen von Tags und Überschriften sowie die Strukturierung des Textes fließen in das Ranking mit ein [2]. Ebenso ist das Einsetzen von Meta-Tags wichtig. Hierzu ein paar Beispiele:
- Verwendung von Keywords im Title Tag, das als Seitenbenennung und Überschrift in Suchergebnissen dient, vermittelt dem Nutzer den Inhalt der Seite
- Zum Ranking zählt ebenfalls die Beschreibung des Inhalts durch das Einsetzen von Meta-Description Tags
- Ein weiteres Beispiel ist die Benennung von Bildern durch das (IMG)Title Tag. Dies erleichtert Google das Verstehen des Bildinhalts
- Der Tag kann auch für Verlinkungen verwendet werden [8].
Dieses Video erläutert nochmal das Gelesene [6].
Offpage Optimierung
Bisher war die Rede nur von Onpage Optimierung. Dabei gibt es einen zweiten Bereich von SEO: Die Offpage Optimierung. Was ist denn nun der Unterschied zwischen den beiden Bereichen? Der Unterschied liegt bei den Maßnahmen der Optimierung. Hierbei werden Maßnahmen ergriffen, die außerhalb der eigenen Webseite stattfinden. Ein weiterer Unterschied ist, dass im Gegensatz zu der Onpage Optimierung, die Offpage Optimierung nicht aktiv beeinflussbar ist.
Wir erinnern uns: Das Ziel von SEO ist es dem User die passenden und besten Ergebnisse zu seiner Suchanfrage zu liefern. Dafür müssen Suchmaschinen, korrekte und gute Inhalte auf die ersteren Plätze der Trefferseite platzieren. Jedoch können Suchmaschinen die Inhalte weder lesen noch deren Richtigkeit beurteilen. Aus diesem Grund kommen andere Nutzer ins Spiel.
Wird eine Webseite mehrmals verlinkt und von anderen Webseiten empfohlen, signalisiert das der Suchmaschine, dass der Inhalt einer Webseite gut sein muss. Die mehrfachen Verlinkungen sind so genannte Backlinks. Wenn eine Webseite mehrere Backlinks erhält, entsteht eine externe Verlinkungsstruktur. Aus diesem Grund steigt die Reichweite und der Bekanntheitsgrad. Dies ist das Hauptziel von Offpage Optimierung. Doch wie veranlasst man nun am besten die Bildung von Backlinks?
Methoden der Offpage Optimierung
Persönliche Kontakte
Wenn man Kontakte hat, die selber Webseitenbetreiber sind oder Webseitenbetreiber im Bekanntenkreis haben, kann man sie fragen, ob sie die Webseite verlinken [2].
Linkbuilding
Beim Linkbuilding soll eine Website so viele Backlinks wie möglich erhalten. Vor allem gut für das Ranking ist es, wenn die Website organisch die Backlinks aufbaut. Das signalisiert der Suchmaschine, dass die Nutzer gerne und von selbst die Seite aufgrund ihres Inhalts verlinken. Gekaufte Backlinks werden von Google erkannt und können abgestraft werden. Ebenso wirken sich der Linktext, die Linkposition und die Anzahl der Links von einer Quelle auf die Stärke der Verknüpfung aus. Nach diesen Faktoren wertet Google die Stärke der Verknüpfung aus [11]. Ein guter Trick für die Erzeugung von Backlinks ist, wenn man selbst Verlinkungen von anderen Webseiten auf seiner eigenen Webseite setzt. Die Webseitenbetreiber können das sehen und einen auf der eigenen Webseite zurück verlinken [2]. Hier ein paar Beispiele für gute Backlink-Quellen: Social Media, Artikeltexte, Verzeichnisse, Kommentare und Foren [10].
Soziale Netzwerke
Verlinkungen in Kommentaren oder Posts auf verschiedenen sozialen Netzwerken, wie Instagram, Twitter, YouTube, können gute Backlinks einbringen [2]. Nutzer können mit den Inhalten interagieren und sorgen durch den viralen Effekt dafür, dass sich dieser verbreitet und dadurch viele weitere Nutzer auf die Website aufmerksam werden [10]. „Ein hohes Suchvolumen nach einem Markennamen oder die häufige Erwähnung eines Unternehmens im Netz könnten darauf hindeuten, dass eine Marke über hohe Brand Awareness verfügt und bekannt ist. Zudem lassen sich viele Backlinks und eine hohe Aktivität sowie hohe Followerzahlen in Social Media als deutliche Hinweise auf eine erfolgreiche Marke anführen“ [11]. Diese „Social Signals“ werden von Google positiv bewertet und fördern das Ranking der Website [10].
Social Media trägt einen großen Teil zu Verlinkungen bei. Um den oben genannten Punkt zu verdeutlichen zeigt diese Tabelle einen Ausschnitt der Anzahl der Nutzer von den meist genutzten sozialen Netzwerken (Stand: Januar 2019) [3].
| Soziales Netzwerk | Userzahl |
|---|---|
| 2,27 Milliarden | |
| YouTube | 1,900 Milliarden |
| 1,000 Milliarden | |
| 360 Millionen |
Branchenbücher
Durch das Eintragen einer Webseite in Branchenbücher, wird dem Nutzer verholfen die Webseite online über die Branche zu finden. Somit können ebenfalls Backlinks erzeugt werden [2].
Dieses Video erläutert nochmal das Gelesene [7].
Eine kurze Zusammenfassung in Form einer Infografik verschafft dir einen besseren Überblick über die SEO Maßnahmen [5].
SEO und UX
SEO und die User Experience hängen miteinander zusammen und auch voneinander ab. Google kann mittlerweile die Inhalte der Webseiten semantisch erfassen und zuordnen. Ebenso kann die Suchmaschine die Bedienbarkeit einer Webseite bewerten. Dazu zählen z.B. versteckte Inhalte hinter Tabs, die man auf den ersten Blick nicht sieht. Jedoch erkennt Google solche Inhalte und kann sie dementsprechend positiv oder negativ bewerten. In Bezug auf die Rankingfaktoren von Google, zeigt sich ein Zusammenhang zwischen SEO und UX. Setzt man bestimmte Rankingfaktoren um, steigt die UX. Hier einige Beispiele:
- Durch den Einsatz von HTTPS wird die Sicherheit der Seitenbesucher erhöht
- Kurze Ladezeiten machen das Abrufen von Webseiten leichter
- Durch Anpassung an mobile Endgeräte wird ein Abruf von Webseiten auf Smartphones und anderen Geräten ermöglicht
- Webseiten, die wenig Werbung und viele hilfreichen Inhalten enthalten, helfen dem Nutzer das zu finden, wonach er sucht
- Durch eine Einteilung der Webseite in Kategorien wird das Auffinden der Webseite erleichtert.
Je einfacher Google es hat, wie ein Nutzer die Webseite zu bedienen, desto besser ist die User Experience sowie die ergriffenen Maßnahmen von SEO. In Folge dessen steigt die Webseite im Ranking [12].
Fazit
Die Onpage- und Offpage Optimierung sind ein wichtiger Teil der Suchmaschinenoptimierung. Bei Onpage Optimierung dreht sich alles um das Auffinden einer Webseite in einer Suchmaschine (meistens Google), indem man die Webseite nach verschiedenen Rankingfaktoren optimiert. Das kann aktiv beeinflusst werden und passiert gezielt auf der Webseite. Technische, strukturelle und inhaltliche Aspekte zählen zu diesen Rankingfaktoren. Ein wesentlicher Vorteil der Onpage Optimierung ist die Erhöhung des Traffic der eigenen Webseite. Zudem dreht sich dabei alles um die Usability [8].
Zusätzlich zu der Onpage Optimierung hilft die Offpage Optimierung die Webseite und die eventuell damit verbundene Marke bekannt zu machen und die Reichweite zu steigern. Hierfür sind Backlinks für Google ein wichtiges Rankingkriterium. Insbesondere die Verlinkungen auf den sozialen Medien wirken sich auf das Ranking aus. Im Gegensatz zu der Onpage Optimierung ist die Offpage Optimierung nicht aktiv beeinflussbar ist. Hierfür spielen die Nutzer eine große Rolle. Sie interagieren mit den Inhalten und verbreiten diese viral. Dadurch werden weitere Nutzer auf die Webseite aufmerksam. Infolgedessen entscheiden und bewerten sie den Inhalt der Webseite und teilen diese. Entscheidend für das Verbreiten und somit das Erzeugen von Backlinks sind guter Content, Nutzerfreundlichkeit und starke Interaktion mit den Kunden/Nutzern. All dies sorgt für bessere SEO-Ergebnisse [11].
Quellenverzeichnis
1: Quietsch, Phillip (o. J.): Google Report: verschenktes Conversion-Potenzial durch lange mobile Ladezeiten. Online unter [Abruf am 04.12.2019]
10: Hanseranking (2020): Offpage SEO. Online unter [Abruf am 25.01.2020]










































































































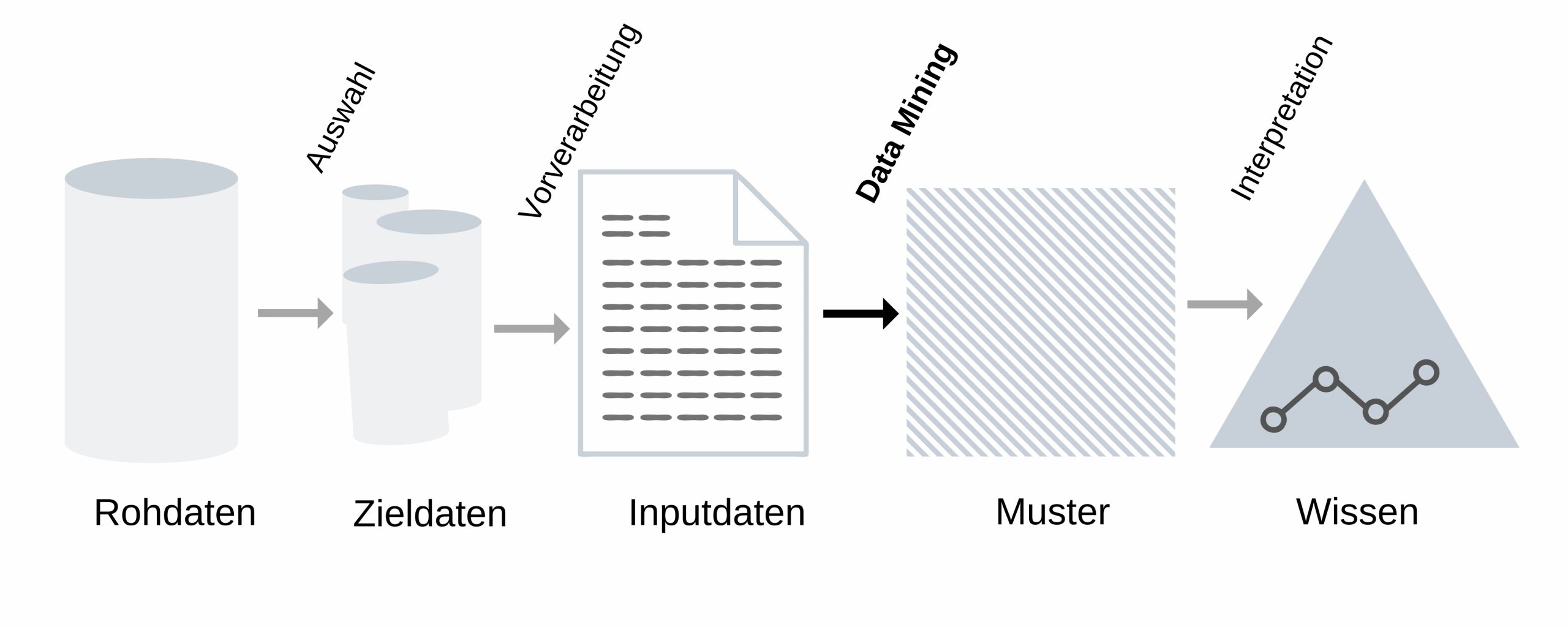
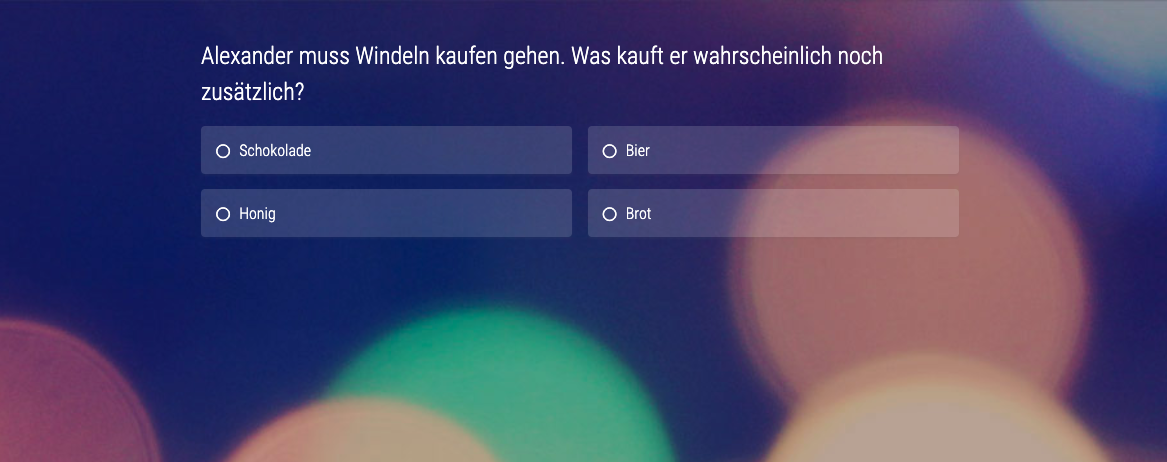
 Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.
Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.