Autor: Oguzhan-Burak Bozkurt
Durch den kontinuierlichen und raschen Fortschritt in jüngster Zeit auf den Gebieten von Big Data und KI-Technologien sind heutzutage insbesondere Teilbereiche des Informationsmanagements gefragter als je zuvor. Die Rolle des Informationsmanagers und Data Scientists besteht darin, Methoden zur Erfassung und Verarbeitung von Informationen aus unterschiedlichen Datenquellen anzuwenden. Zudem ist er befähigt, Entscheidungen darüber zu treffen, welche Verarbeitungsprozesse zur gezielten Knowledge Discovery aus umfangreichen Datensätzen geeignet sind. Hierbei kommt Data Mining ins Spiel, eine Methode, die die systematische Extraktion relevanter Informationen und Erkenntnisse aus großen Datenmengen umfasst.
In diesem Blogbeitrag werden wir tiefer in das Thema eintauchen und uns einem von vielen Verfahren des Data Mining, genauer der Sentimentanalyse im Text Mining, praxisnah annähern. Dabei bin ich der Ansicht, dass ein tieferes Verständnis erreicht wird, wenn das theoretisch Gelernte eigenständig umgesetzt werden kann, anstatt lediglich neue Buzzwörter kennenzulernen. Ziel ist eine Sentimentanalyse zu Beiträgen auf der Social Media Plattform X (ehemals Twitter) mit Verfahren aus dem Machine Learning bzw. einem passenden Modell aus Hugging Face umzusetzen.
Ihr könnt euch in die Hintergründe einlesen oder direkt zum Coden überspringen.
Einführung: Data Mining ⛏️
Data Mining umfasst die Extraktion von relevanten Informationen und Erkenntnissen aus umfangreichen Datensammlungen. Ähnlich wird auch der Begriff „Knowledge Discovery in Databases“ (KDD) verwendet. Die Hauptaufgabe besteht darin, Verhaltensmuster und Prognosen aus den Daten zu identifizieren, um darauf basierend Trends zu erkennen und angemessen darauf zu reagieren. Dieser analytische Prozess des Data Mining erfolgt mithilfe von computergestützten Methoden, deren Wurzeln in den Bereichen Mathematik, Informatik und insbesondere Statistik liegen. Data Mining kann als Teilprozess innerhalb des umfassenden Datenanalyseprozesses verstanden werden, der folgendermaßen strukturiert ist:

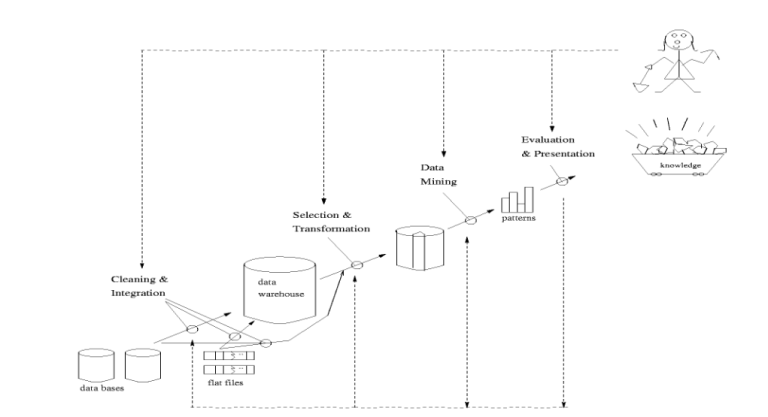
Die Data Mining Verfahren dienen dazu, den Datenbestand zu beschreiben und zukünftige Entwicklungen vorherzusagen. Hierbei kommen Klassifikations- und Regressionsmethoden aus dem statistischen Bereich zum Einsatz. Zuvor ist es jedoch notwendig, die Zielvariable festzulegen, die Daten aufzubereiten und Modelle zu erstellen. Die gebräuchlichen Methoden ermöglichen die Analyse spezifischer Kriterien wie Ausreißer- und Clusteranalyse, die Verallgemeinerung von Datensätzen, die Klassifizierung von Daten und die Untersuchung von Datenabhängigkeiten.
Zusätzlich zu den herkömmlichen statistischen Methoden können auch Deep Learning-Algorithmen verwendet werden. Hierbei werden Modelle aus dem Bereich des Machine Learning unter Anwendung von überwachtem (bei gelabelten Daten) oder unüberwachtem (bei nicht gelabelten Daten) Lernen eingesetzt, um die Zielvariablen möglichst präzise vorherzusagen. Eine wesentliche Voraussetzung für das Vorhersagemodell ist ein Trainingsdatensatz mit bereits definierten Zielvariablen, auf den das Modell anschließend trainiert wird.
ML-Based Text Mining 🤖
Ein Teilbereich des Data Mining, der auch maßgeblich maschinelles Lernen einbezieht, ist das Text Mining. Hierbei zielt das Text Mining darauf ab, unstrukturierte Daten aus Texten, wie beispielsweise in sozialen Netzwerken veröffentlichte Inhalte, Kundenbewertungen auf Online-Marktplätzen oder lokal gespeicherte Textdateien, in strukturierte Daten umzuwandeln. Für das Text Mining dienen oft Datenquellen, die nicht direkt zugänglich sind, weshalb Daten über APIs oder Web-Scraping beschafft werden. Im darauf folgenden Schritt werden Merkmale (Features) gebildet und die Daten vorverarbeitet. Hierbei erfolgt die Analyse der Texte mithilfe von natürlicher Sprachverarbeitung (Natural Language Processing – NLP) unter Berücksichtigung von Eigenschaften wie Wortfrequenz, Satzlänge und Sprache.
Maschinelles Lernen für Datenvorverarbeitung
Die Vorverarbeitung der Daten wird durch Techniken des maschinellen Lernens ermöglicht, zu denen Folgendes gehört:
Insgesamt kann der Text Mining-Prozess als Teil einer breiteren Datenanalyse oder Wissensentdeckung verstanden werden, bei dem die vorverarbeiteten Textdaten als Ausgangspunkt für weitere Schritte dienen.
The effort of using machines to mimic the human mind has always struck me as rather silly. I would rather use them to mimic something better.
Edsger Wybe Dijkstra
In unserem nächsten Abschnitt werden wir auf die Sentimentanalyse eingehen und schrittweise demonstrieren, wie sie mit Hilfe von Modellen auf Hugging Face für Beiträge auf der Plattform X (ehemalig Twitter) durchgeführt werden kann.
In my feelings mit Hugging Face 🤗
Das 2016 gegründete Unternehmen Hugging Face mit Sitz in New York City ist eine Data Science und Machine Learning Plattform. Ähnlich wie GitHub ist Hugging Face gleichzeitig ein Open Source Hub für AI-Experten und -Enthusiasten. Der Einsatz von Huggin Face ist es, KI-Modelle durch Open Source Infrastruktur und Repositories für die breite Maße zugänglicher zu machen. Populär ist die Plattform unter anderem für seine hauseigene Open Source Bibliothek Transformers, die auf ML-Frameworks wie PyTorch, TensorFlow und JAX aufbauend verschiedene vortrainierte Modelle aus den Bereichen NLP, Computer Vision, Audio und Multimodale anhand von APIs zur Verfügung stellt.

Für die Sentimentanalyse stehen uns über 200 Modelle auf der Plattform zur Verfügung. Wir werden im folgenden eine einfache Sentimentanalyse unter Verwendung von Transformers und Python durchführen. Unsere KI soll am Ende Ton, Gefühl und Stimmung eines Social Media Posts erkennen können.
Viel Spaß beim Bauen! 🦾
Let’s build! Sentimentanalyse mit Python 🐍
Zunächst brauchen wir Daten aus X/Twitter. Da im Anschluss auf die neuen Richtlinien die Twitter API jedoch extrem eingeschränkt wurde (rate limits, kostenspielige read Berechtigung) und es nun auch viele Scraping-Methoden getroffen hat, werden wir bereits vorhandene Daten aus Kaggle verwenden.

1. Datenbereitstellung: Kaggle
Wir entscheiden uns für einen Datensatz, der sich für eine Sentimentanalyse eignet. Da wir mit einem Text-Mining Modell in Transformers arbeiten werden, welches NLP verwendet um das Sentiment eines Textes zuordnen zu können, sollten wir uns für einen Datensatz entscheiden, in dem sich Texte für unsere Zielvariable (das Sentiment) befinden.
Hier kann ein Datensatz aus Kaggle verwendet werden, in dem über 80 Tausend englische Tweets über das Thema „Crypto“ in dem Zeitraum vom 28.08.2022 – 29.08.2022 gesammelt wurde: 🐦 🪙 💸 Crypto Tweets | 80k in English | Aug 2022 🐦 🪙 💸
Wir laden das Archiv herunter und entpacken die crypto-query-tweets.csv in unseren Projektordner.
2. Zielsetzung und Datenvorverarbeitung: Python + Pandas
Wir wollen in einer überschaubaren Anzahl an Tweets das jeweilige Sentiment zuordnen. Dazu schauen wir uns den Datensatz aus der CSV Datei genauer an. Uns interessieren dabei besonders Tweets von verifizierten Usern. Mit der Pandas Bibliothekt läss sich der Datensatz in Dataframes laden und nach bestimmten kriterien filtern.
wir installieren zunächst per pip-install die gewünschte Bibliothek und importieren diese in unsere Codebase.
pip install pandasAnschließends lesen wir die CSV-Datei ein und filtern entsprechend unseren Wünschen den Datensatz und geben diesen als Dataframe aus.
import pandas as pd
# CSV Datei lesen
csv_file_path = "crypto-query-tweets.csv"
df = pd.read_csv(csv_file_path, usecols=['date_time', 'username', 'verified', 'tweet_text'])
# Filter anwenden um nur verifizierte User zu erhalten
filtered_df = df[df['verified'] == True]
# Printe Dataframe
print(filtered_df)Wir erhalten folgende Ausgabe von 695 Zeilen und 4 Spalten:
date_time username verified tweet_text
19 2022-08-29 11:44:47+00:00 RR2Capital True #Ethereum (ETH)\n\nEthereum is currently the s...24 2022-08-29 11:44:45+00:00 RR2Capital True #Bitcoin (BTC)\n\nThe world’s first and larges...
25 2022-08-29 11:44:43+00:00 RR2Capital True TOP 10 TRENDING CRYPTO COINS FOR 2023\n \nWe h...
146 2022-08-29 11:42:39+00:00 ELLEmagazine True A Weekend in the Woods With Crypto’s Cool Kids...
155 2022-08-29 11:42:32+00:00 sofizamolo True Shill me your favorite #crypto project👇🏻🤩
... ... ... ... ...
79383 2022-08-28 12:36:34+00:00 hernanlafalce True @VerseOort My proposal is as good as your proj...
79813 2022-08-28 12:30:15+00:00 NEARProtocol True 💫NEARCON Speaker Announcement💫\n\nWe're bringi...
79846 2022-08-28 12:30:00+00:00 lcx True 🚀@LCX enables project teams to focus on produc...
79919 2022-08-28 12:28:56+00:00 iSocialFanz True Friday.. Heading to Columbus Ohio for a Web 3....
79995 2022-08-28 12:27:46+00:00 BloombergAsia True Bitcoin appeared stuck around $20,000 on Sunda...
[695 rows x 4 columns]3. Twitter-roBERTa-base for Sentiment Analysis + TweetEval
Nun können wir mit Hugging Face Transformers eine vortrainiertes Modell verwenden, um allen Tweets entsprechende Sentiment Scores zuzuweisen. Wir nehmen hierfür das Modell Twitter-roBERTa-base for Sentiment Analysis, welches mit über 50 Millionen Tweets trainiert wurde und auf das TweetEval Benchmark für Tweet-Klassifizierung aufbaut. Weitere Infos unter dieser BibTex entry:
@inproceedings{barbieri-etal-2020-tweeteval,
title = "{T}weet{E}val: Unified Benchmark and Comparative Evaluation for Tweet Classification",
author = "Barbieri, Francesco and
Camacho-Collados, Jose and
Espinosa Anke, Luis and
Neves, Leonardo",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.findings-emnlp.148",
doi = "10.18653/v1/2020.findings-emnlp.148",
pages = "1644--1650"
}Wir installieren alle für den weiteren Verlauf benötigten Bibliotheken.
pip install transformers numpy scipyDie Transformers Bibliothekt erlaubt uns den Zugriff auf das benötigte Modell für die Sentimentanalyse. Mit scipy softmax und numpy werden wir die Sentiment Scores ausgeben mit Werten zwischen 0.0 und 1.0, die folgendermaßen für alle 3 Labels ausgegeben werden:
Labels: 0 -> Negative; 1 -> Neutral; 2 -> Positive
Importieren der Bibliotheken:
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
import numpy as np
from scipy.special import softmax
import csv
import urllib.requestWir schreiben eine Methode zum vorverarbeiten des Texts. Hier sollen später Usernamen und Links aussortiert werden. Außerdem vergeben wir das gewünschte Modell mit dem gewünschten Task (’sentiment‘) in eine vorgesehene Variable und laden einen AutoTokenizer ein, um später eine einfach Eingabe-Enkodierung zu generieren.
# Vorverarbeitung des texts
def preprocess(text):
new_text = []
for t in text.split(" "):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
task='sentiment'
MODEL = f"cardiffnlp/twitter-roberta-base-{task}"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
Als nächstes laden wir das Label Mapping aus TweetEval für das zugeordnete Task ’sentiment‘ herunter. Das Modell für die Sequenzklassifizierung kann nun gespeichert und in der ‚model‘ Variable hinterlegt werden.
# download label mapping
labels=[]
mapping_link = f"https://raw.githubusercontent.com/cardiffnlp/tweeteval/main/datasets/{task}/mapping.txt"
with urllib.request.urlopen(mapping_link) as f:
html = f.read().decode('utf-8').split("\n")
csvreader = csv.reader(html, delimiter='\t')
labels = [row[1] for row in csvreader if len(row) > 1]
# Modell laden
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
model.save_pretrained(MODEL)
Im nächsten Schritt schreiben wir zwei Methoden, die dabei helfen sollen zeilenweise Tweet-Texte zu enkodieren und ein Sentiment Score zu vergeben. In einem Array sentiment_results legen wir alle Labels und entsprechende Scores ab.
# Sentiment Scores für alle Tweets erhalten
def get_sentiment(text):
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
scores = output.logits[0].detach().numpy()
scores = softmax(scores)
return scores
# Sentimentanalyse für jede Zeile im Datensatz anwenden
def analyze_sentiment(row):
scores = get_sentiment(row['tweet_text'])
ranking = np.argsort(scores)
ranking = ranking[::-1]
sentiment_results = []
for i in range(scores.shape[0]):
l = labels[ranking[i]]
s = scores[ranking[i]]
sentiment_results.append((l, np.round(float(s), 4)))
return sentiment_results
Zum Schluss wir das Dataframe um unser Ergebnis erweitert. Hierzu erstellen wir eine neue Spalte ’sentiment‘ und fügen mit der apply-Funktion die Ergebnisse aus unserer vorherigen Methode analyze_sentiement hinzu. Am Ende geben wir unser neues Dataframe in der Konsole aus.
# Ergebnisse in neue Spalte "sentiment" speichern
filtered_df['sentiment'] = filtered_df.apply(analyze_sentiment, axis=1)
# Ausgabe des neuen DataFrames
print(filtered_df)Wir erhalten ein neues Dataframe mit einer weiteren Spalte in der das Label und die Sentiment-Scores festgehalten werden! 🤗🚀

Den gesamten Code könnt ihr euch auch auf meinem GitHub Profil ansehen oder klonen.
Referenzen
Han, Jiawei (2006). Data Mining: Concepts and Techniques, Simon Fraser University.
Barbieri, F., Camacho-Collados, J., Espinosa Anke, L., & Neves, L. (2020). Tweet Eval: Unified Benchmark and Comparative Evaluation for Tweet Classification. In Findings of the Association for Computational Linguistics: EMNLP 2020, S. 1644-1650. https://aclanthology.org/2020.findings-emnlp.148.
Hugging Face Transformers: https://huggingface.co/docs/transformers/index. Zuletzt aktualisiert am 27.08.2023.
Kaggle Dataset: Leonel do Nascimento, Tiago; „Crypto Tweets | 80k in ENG | Aug 2022 „: https://www.kaggle.com/datasets/tleonel/crypto-tweets-80k-in-eng-aug-2022. (CC0 Public Domain Lizens), zuletzt aktualisiert am 27.08.2023.
Wartena, Christian & Koraljka Golub (2021). Evaluierung von Verschlagwortung im Kontext des Information Retrievals. In Qualität in der Inhaltserschließung, 70:325–48. Bibliotheks- und Informationspraxis. De Gruyter, 2021. https://doi.org/10.1515/9783110691597.