Typische Themen aus dem Studiengang Informationsmanagement.
Rund um Informationsmanagement


Web Science Lab
Typische Themen aus dem Studiengang Informationsmanagement.

In seiner sehr gut gelungenen Bachelorarbei behandelt Valentin Griese das Thema „Realisierbarkeit der webseitenübergreifenden Nutzerverfolgung ohne die Verwendung von Cookies in der Europäischen Union„.
Die Nutzerverfolgung im Internet durch die Verwendung von Browsercookies ist gängige Praxis, doch haben diverse datenschutzrechtliche Entwicklungen der letzten Jahre zugunsten der Verbraucher diese Form des Trackings in vielerlei Hinsicht eingeschränkt und auch die Usability von Websites maßgeblich beeinträchtigt. Um weiterhin eine Personalisierung von Werbung und anderen Inhalten unter Wahrung der Nutzbarkeit und Rechte der Nutzer zu gewährleisten, ist es unausweichlich, eine neue Methode zur Identifizierung von Besuchern zu etablieren. Das Ziel dieser Arbeit ist, verschiedene Trackingtechnologien unter Berücksichtigung gegebener Rahmenbedingungen im Rechtsraum der Europäischen Union in ihrer Funktionsweise zu vergleichen und die nach derzeitigem Stand realistische Nachfolgetechnologie zum Tracking via Cookies zu benennen – Fingerprinting. Dieses überzeugt in Bezug auf seine Langlebigkeit und rechtliche Vereinbarkeit, den Implementierungsaufwand sowie den Umfang der sammelbaren Daten. Darauf aufbauend ist eine statistische Untersuchung zur Verbreitung von Methoden aus dem Feld des Fingerprintings auf den meistgenutzten Internetseiten durchgeführt worden. Dabei ergibt sich, dass Informationen, die zur Erstellung eines Fingerprints genutzt werden können, von fast allen Websites abgefragt werden, jedoch durchschnittlich nur wenige verschiedene Arten von Fingerprints genutzt werden. Auf einigen Websites werden durch größere dritte Unternehmen Fingerprints erfasst, der Opt-in-Status hingegen hat in den meisten Fällen für die Praktizierung von Fingerprinting keine Relevanz. Da Fingerprinting auch für schädliche Zwecke, zum Beispiel das Verteilen von potenterer Schadsoftware, verwendet werden kann, ist die Reaktion von Browserentwicklern und -nutzern auf die Entwicklung von derzeitigen und zukünftigen Fingerprintingkonzepten ungewiss, und auch die rechtliche Lage der nächste Jahre hängt von angekündigten Verordnungen ab, die in ihrem Inhalt noch nicht bekannt sind.
Die Bachelorarbeit von Valentin wurde vorbildlich über SerWisS veröffentlicht und ist als Volltext zu finden unter:
https://doi.org/10.25968/opus-1717
Bildquelle: unsplash.com/dor_farber


Hier finden Sie einen Überblick zu ersten Ergebnissen im Forschungsprojekt nITo.
[su_posts posts_per_page=“-1″ tax_term=“329″ order=“desc“]
Seit diesem Sommersemester (März 20) ist das WebLab an einem neuen Forschungsprojekt mit dem Titel „nITo: Nutzerzentrierte IT-Kompetenzoptimierung“ beteiligt
nITo befasst sich mit IT-Kompetenz-Exploration in Hannover.
Aktuell ist eine Bachelorarbeit zu nITo bereits abgeschlossen und vier weitere laufen. Falls Sie auch noch ein Thema suchen, werden Sie vielleicht hier fündig.
Weitere Einzelheiten wie Forschungsziel und -schwerpunkte finden Sie hier.

Autori*nnen: Judith Hauschulz und Verena-Christin Schmidt
Die Warenkorbanalyse gehört zum Data Mining und ist ein Anwendungs-gebiet der Assoziationsanalyse. Wenn du diese Begriffe hörst, ist dir wahrscheinlich klar, dass es um Daten geht. Aber das klingt nun vielleicht etwas trocken, deshalb fangen wir nochmal neu an:
 dir beim Online-Shopping „passende“ Artikel vorgeschlagen werden?
dir beim Online-Shopping „passende“ Artikel vorgeschlagen werden?Dann bist du hier genau richtig! Wir erklären dir, wie das funktioniert. Doch dazu fangen wir erst einmal beim Allgemeinen an: dem Data Mining.
Eigentlich heißt Data Mining nur „Datenschürfen“. Dabei soll aus Daten Wissen erzeugt werden.1 Mit Wissen ist hier ein Muster gemeint, das für NutzerInnen interessant ist oder auch interessant sein kann. Ein Muster besteht dann wiederum aus Beziehungen zwischen Daten oder Regelmäßigkeiten und wird Datenmustererkennung genannt. 2
In der Graphik kannst du den Ablauf des Data Minings ablesen. Das Ganze stellt einen Prozess dar, bei dem das Ziel ist, dass man neue Erkenntnisse gewinnt. Dabei beschränkt man zuerst eine große Menge an Rohdaten auf eine kleinere Auswahl, sodass sie anschließend verarbeitet werden können. So dienen sie also als Grundlage für die Muster, die das Data Mining aufdecken soll.3
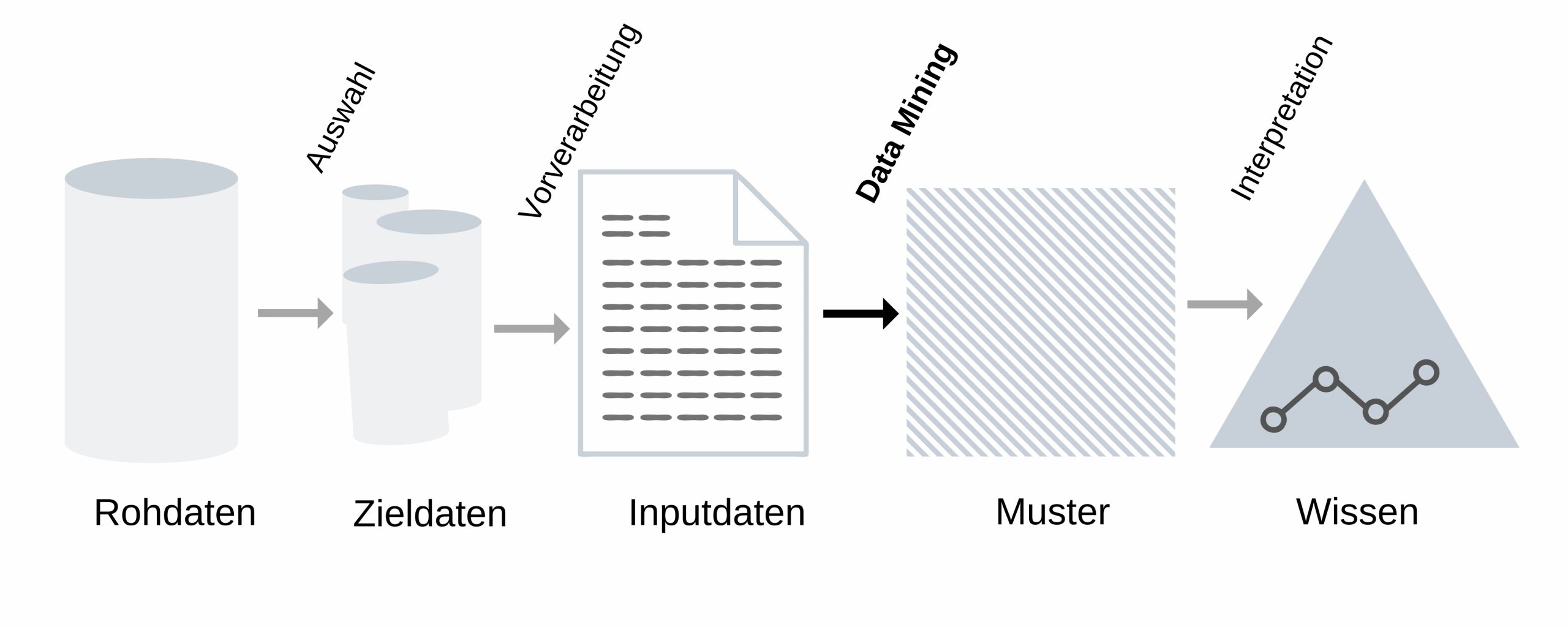
Es gibt sehr viele Verfahren im Data Mining. Wir erklären dir aber nur die Assoziationsanalyse, weil sie relevant für die Analyse von Waren ist. Sie zählt zu den bekannteren beziehungsweise typischen Methoden des Data Minings.4
"Die Assoziationsanalyse gehört zu einem der grundlegendsten Verfahren in der Datenanalyse und spielt im wirtschaftlichen Bereich eine große Rolle."5
Mit der Assoziationsanalyse kannst du Abhängigkeiten und Zusammenhänge in großen Datenmengen ermitteln. Dazu benutzt man sogenannte Items. Stell sie dir am besten wie Produkte im Supermarkt vor! Mit diesen Items können wir dann Berechnungen durchführen. Wir könnten also schauen, ob zwei von ihnen auffällig oft gemeinsam vorkommen.
Es kann aber auch passieren, dass ein Item besonders dann auftritt, wenn ein anderes Item vorhanden ist. Ein Item kann sogar das Vorkommen eines anderen Items begünstigen. Wenn das eintritt, lassen sich da-raus Assoziationsregeln ableiten.1 Aus ihnen können wir beispielsweise Vorhersagen treffen oder Empfehlungen aussprechen.
Als Ergebnis erhalten wir Regeln, die folgende Form haben:
"Wenn Item A vorliegt, dann tritt in X Prozent
"6
Diese Regeln der Assoziationsanalyse können wir benutzen, um zum Beispiel Wechselwirkungen verschiedener Medikamente zu erforschen. Und auch wenn man Zusammenhänge bei der Wahl von Anlageformen bei Banken aufdecken möchte, ist sie nützlich.7 Ein wesentlich bekannteres Beispiel ist aber die Empfehlung von Artikeln im Online-Handel. Wenn wir einen Artikel aufrufen, dann zeigt uns die Seite oft, was andere KundInnen noch gekauft haben.8 Solche Vorhersagen lassen sich auch aufgrund von Warenkorbanalysen treffen.
In einer Folge der Serie “Numb3rs – Die Logik des Verbrechens” geht es um ein beliebtes Beispiel der Warenkorbanalyse. Windeln und Bier werden hier sehr oft zusammen gekauft. Auch wenn es erstaunlich erscheint, so haben sie eine logische Erklärung dafür: Männer, die von ihren Frauen zum Windelkauf aufgefordert werden, kaufen gerne noch Bier dazu. Damit haben sie etwas, worauf sie sich nach der „Arbeit mit dem Kind“ freuen und was sie genießen können. Darum kommt es zu dem Ergebnis, dass das Bierregal auf dem Weg von den Windeln zur Kasse platziert und so der Umsatz gesteigert wird.9
Bei der Warenkorbanalyse wertet man die Einkäufe von KundInnen aus, um dadurch verschiedene Items zu untersuchen. Die Items bestehen hier aus den Artikeln von zum Beispiel Supermärkten. Alle Kaufaktionen zusammengefasst ergeben die Datenbasis.7
Fast alle Unternehmen, die Waren verkaufen, haben die Daten, die für das Data Mining mit der Warenkorbanalyse nötig sind. Schon einige Kassenbons reichen aus und es wird kein spezielles System benötigt. Damit lassen sich dann stark nachgefragte Produkte ermitteln oder Verbindungen zwischen verschiedenen Waren untersuchen.10 Mit der Analyse können wir also auch erfahren, wie oft ein Produkt mit einem anderen im Warenkorb landet. Um dabei die „Spreu vom Weizen“ zu trennen, werden Assoziationsregeln erstellt.11 Aber wie können wir denn nun Muster finden?
 Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.12
Wenn Menschen Lebensmittel einkaufen gehen, haben sie meistens eine Einkaufsliste dabei, damit sie nichts vergessen. Auf manchen Listen befinden sich viele gesunde Produkte, wohingegen auf anderen eher Bier und Chips stehen. Daraus können wir schon Muster erkennen, durch die sich die Waren im Supermarkt entsprechend sortieren lassen.12
Wenn wir Zusammenhänge und Abhängigkeiten berechnen wollen, müssen wir (leider) etwas mathematisch werden. Aber keine Angst, wir benutzen dafür ein leicht verständliches und nachvollziehbares Beispiel.
Zuerst brauchen wir die drei Kennzahlen Support, Konfidenz und Lift. In der Tabelle steht ein Beispiel, dass dir helfen wird, um diese Kennzahlen zu verstehen. Bei uns geht es lediglich um zwei Produkte. Insgesamt untersuchen wir hier aber 1.000.000 Transaktionen beziehungsweise Einkäufe. Darin kommen auch 200.000-mal der Kauf von Bier und 50.000-mal der Kauf von Windeln vor. Die KundInnen dieses Supermarkts haben Bier und Windeln sogar 20.000-mal gleichzeitig gekauft.
| Anzahl | Waren |
|---|---|
| 1.000.000 | Transaktionen insgesamt |
| 200.000 | Bier |
| 50.000 | Windeln |
| 20.000 | Windeln und Bier |
Wie oft werden Bier und Windeln denn nun zusammen gekauft? Um das zu erfahren, berechnen wir den Support. Dafür setzen wir zuerst die Anzahl der Käufe von Bier und Windeln separat ins Verhältnis aller vorliegenden Einkäufe. Danach machen wir das genauso mit der Anzahl der gemeinsamen Käufe, sodass wir einen Support von 2% erhalten.

Die Konfidenz sagt uns, wie oft eine Assoziationsregel („Wenn Bier gekauft wird, dann werden auch Windeln gekauft“) richtig ist. Sie gibt außerdem einen Hinweis darauf, wie stark der Zusammenhang zwischen Bier und Windeln ist.11
Wenn wir die Konfidenz berechnen wollen, brauchen wir die Support-Werte. Zu Beginn teilen wir dabei den gemeinsamen Support durch den einzelnen Support des Biers. Daraus ergibt sich eine Konfidenz von 10%. Weil das noch nicht besonders viel ist, drehen wir die Assoziationsregel einfach mal um. Somit ergibt sich eine Konfidenz von 40%, da nun die Anzahl der Windel-Einkäufe die Bezugsgröße darstellt.
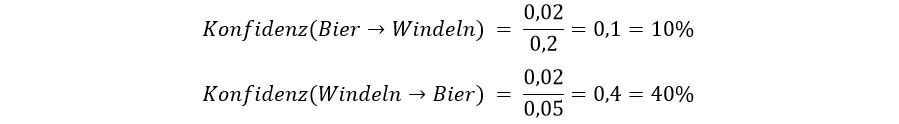
Die zweite Regel zeigt also ein Muster auf, das der Supermarkt so nutzen kann: Wenn das Bier in Sichtweite der Windeln positioniert wird, dann wird beides häufiger zusammen gekauft werden.7
Ob der Kauf von Bier und Windeln nun wirklich zusammenhängt, verrät der Lift. Er sagt uns auch, um wieviel wahrscheinlicher Windeln den Kauf von Bier machen. Dafür müssen wir den gemeinsamen Support durch das Produkt der einzelnen Support-Werte teilen.
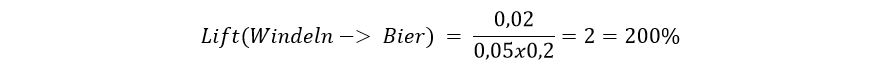
Das Ergebnis ist ein Lift von 200%. Das heißt, dass der Kauf von Windeln die Wahrscheinlichkeit für den zusätzlichen Kauf von Bier sogar verdoppelt!
Zur Erklärung: Ein Lift von 100% würde stattdessen bedeuten, dass beide Items unabhängig voneinander sind. Bei einem Lift, der kleiner als 100% ist, ist es unwahrscheinlich ist, dass beide Items zusammen auftreten.11
Wie du siehst, ist es eigentlich doch ganz einfach, Muster und Abhängigkeiten zu entdecken. Wenn wir uns aber nicht nur mit zwei, sondern mit allen Artikeln eines Supermarkts beschäftigen würden, so wäre es deutlich schwieriger. Wir hätten dann ja viel mehr Daten, wodurch sich der Umfang der Berechnungen massiv erhöhen würde. Umso besser ist aber dadurch das Endergebnis. Aus einer großen und umfangreichen Warenkorbanalyse gewinnt man nämlich nicht nur ein paar Muster, sondern das gesamte Einkaufsverhalten der KundInnen. Das können Unternehmen für Dinge nutzen, wie zum Beispiel:
Sobald Unternehmen die Warenkorbanalyse benutzen, geht es aber auch immer darum, das Angebot zu optimieren und den Umsatz zu steigern.10
Gut aufgepasst? Überprüfe jetzt dein Wissen mit dem Quiz zum Data Mining mit der Warenkorbanalyse!
Wenn du mehr darüber erfahren willst, warum wir diesen Beitrag geschrieben haben, dann lies dir doch unser Konzept durch. Darin erklären wir auch, wie wir beim Verfassen von „Data Mining mit der Warenkorbanalyse“ vorgegangen sind.
1 vgl. Cleve, Jürgen; Lämmel, Uwe (2016): Data Mining. 2. Auflage. Berlin, Boston: De Gruyter Saur
5 Begerow, Markus u.a. (2019): Assoziationsanalyse. Online unter https://www.datenbanken-verstehen.de/lexikon/assoziationsanalyse/ [Abruf am 20.12.2019]
8 vgl. Zaki, Mohammed J. ; Meira Jr., Wagner (2013): Data Mining and Analysis. Fundamental Concepts and Algorithms. Online unter https://repo.palkeo.com/algo/information-retrieval/Data%20mining%20and%20analysis.pdf [Abruf am 16.12.2019]
9 vgl. Swoyer, Stephen (2016): Beer and Diapers. The impossible correlation. Online unter https://tdwi.org/articles/2016/11/15/beer-and-diapers-impossible-correlation.aspx [Abruf am 17.12.2019]
10 vgl. Poliakov, Vladimir (2019): Data Science. Warenkorbanalyse in 30 Minuten. Online unter https://www.heise.de/developer/artikel/Data-Science-Warenkorbanalyse-in-30-Minuten-4425737.html [Abruf am 13.12.2019]
11 vgl.Rabanser, Alexander (2018): Warenkorbanalyse Teil 1. Analytische Grundlagen und Korrelationsanalyse in Excel. Online unter https://linearis.at/blog/2018/04/06/warenkorbanalyse-teil-1-analytische-grundlagen-und-korrelationsanalyse-in-excel/ [Abruf am 13.12.2019]
Dieser Beitrag ist im Rahmen der Lehrveranstaltung Content Management im Wintersemester 2019/20 bei Andre Kreutzmann (und Monika Steinberg) entstanden.

Autorin: Linda Görzen
Dieser Beitrag im Überblick:

”Signals always point to something. In this sense, a signal is not a thing but a relationship. Data becomes useful knowledge of something that matters when it builds a bridge between a question and an answer. This connection is the signal.”
― Stephen Few, Signal: Understanding What Matters in a World of Noise[5]
Unter Data Mining versteht man einen Prozess, bei dem man mithilfe anspruchsvoller mathematischer und statistischer Algorithmen in großen Datenmengen nach Mustern, Trends und Zusammenhängen sucht.[1] Die Besonderheit des Data Mining ist die automatische Generierung der neuen Hypothesen aus den Datenmengen.[4] So kann man beispielsweise anhand der Verkaufsdaten untersuchen, ob und wann Kunden, die Produkt A gekauft haben, auch Produkt B kaufen.
Ziele der Untersuchung einer Datenmenge können unterschiedlich sein. Je nach Ziel gibt es im Data Mining dafür passende Aufgabenstellungen beziehungsweise -typen und dazugehörige Methoden. Typische Aufgabentypen sind Klassifikation, Regressionsanalyse, Assoziationsanalyse, Ausreißererkennung und Clusteranalyse. Darüber hinaus werden die Aufgabentypen des Data Mining oftmals nur in zwei Gruppen eingeteilt. Diese sind Beobachtungsprobleme (Clusteranalyse, Ausreißererkennung) und Prognoseprobleme (Klassifikation, Regressionsanalyse). [6]
Die Objekte der vorhandenen Daten werden anhand ihrer Merkmale in Klassen zusammengefasst. Die dadurch gebildeten Klassenmengen dienen als Grundlage für die Entwicklung eines Klassifikationsmodells. Mit dem Klassifikationsmodell lässt sich nun die Klassenzugehörigkeit eines neuen Objekts automatisch vorhersagen.[2]
Die Regressionsanalyse basiert auf den Konzepten der Varianz und Kovarianz. Dies bedeutet, es wird nach Zusammenhängen beziehungsweise Abhängigkeiten zwischen Variablen gesucht. Meistens setzt man eine Regressionsanalyse bei Prognosen und Vorhersagen ein.[3]
So ist es möglich, aus den historischen Daten der Umsätze eines Kunden und seinem Wohnort eine Kennzahl zu ermitteln. Diese Kennzahl kann beispielsweise der zu erwartende Umsatz, den der Kunde in Zukunft einbringen wird, sein.[8]
Bei der Assoziationsanalyse untersucht man die einzelnen Datensätze eines Datenbestandes auf Zusammenhänge, bei denen auf ein Ereignis konsequent ein anderes folgt. [8] Diese Zusammenhänge werden über Wenn-dann-Regeln beschrieben. Typischer Anwendungsbereich der Assoziationsanalyse ist die Untersuchung des Warenkorbes. Ein Beispiel dafür ist folgendes: Wenn ein Kunde Mehl kauft, dann kauft er wahrscheinlich auch die Butter. Die Assoziationsanalyse kann aber auch für die Untersuchung komplexerer Zusammenhänge benutzt werden. Etwa, in welchem Zeitabstand nach dem Kauf des Produktes A, der Kauf des Produktes B erfolgt. [1]
Ausreißer sind die Werte, die deutlich von den erwarteten Werten abweichen und gar nicht in die Messreihe passen. Sie können die Datenergebnisse stark verzerren und ungültig machen. Aus diesem Grund muss ein Datenbestand von den Ausreißern bereinigt werden. [3] Die Verfahren zur Analyse von Ausreißern sollen mithilfe der historischen Daten die Wahrscheinlichkeit ermitteln, mit der ein neuer Datensatz ein Ausreißer ist. Dieser soll dann entweder automatisch gelöscht oder zur manuellen Analyse gesammelt werden. [8]
Die zentrale Aufgabe einer Clusteranalyse ist es, neue Kategorien bzw. Gruppen zu identifizieren. Denn im Gegensatz zu Klassenanalyse sind bei dieser Methode die Klassen nicht vorgegeben. Bei der Clusteranalyse werden große Datenmengen in kleinere Gruppen eingeteilt (siehe Abbildung 1). Die Mitglieder eines Clusters sollen möglichst ähnliche (homogen) Eigenschaften aufweisen. Die einzelnen Clusterkategorien sollen sich wiederum möglichst stark unterscheiden (heterogen).[7]
Da die Cluster ohne Vorwissen generiert werden, ist es nicht immer eindeutig, was die Cluster ähnlich macht und ob sie auch inhaltlich relevant sind. Für eine Aufklärung sind zusätzliche Analysen zuständig.[7]
Abbildung 1: Clusteranalyse[9] (Autor: Chire Linzenz: CC BY-SA)
Im folgenden Video sind weitere Informationen zum Thema Methoden beziehungsweise Aufgabentypen des Data Mining mit dazugehörigen Beispielen zu finden:
Das Anwendungspotenzial des Data Mining ist vielfältig, da es in unterschiedlichen Bereichen verwendet werden kann. Aber vor allem in der Wirtschaft spielt es eine große Rolle. Mit dem Einsatz der Datenanalyse durch Data Mining können sich Händler besser auf das Kaufverhalten der Kunden anpassen und ihnen ein besseres Einkaufsserlebnis sowohl online als auch im Laden anbieten. Ferner können Banken und Versicherungen die Bonität ihrer Kunden schneller beurteilen.
Nichtsdestotrotz sollte man immer bedenken, dass die Daten nicht immer vollständig oder zum Teil fehlerhaft sein können, was zu verfälschten Resultaten führt. Somit ist die Qualität der Daten ausschlaggebend für aussagekräftige Ergebnisse.
Quellen:
1 Computerwoche (2015): Was ist bei Predictiv Analytics? Online unter: https://www.tecchannel.de/a/was-ist-was-bei-predictive-analytics,3199559,2 [Abruf am 25.01.2020]
2 Dürr, Holger (2004): Anwendungen des Data Mining in der Praxis. Online unter: [Abruf am 25.01.2020]
3 Entwickler.de (2014): Data Mining: typische Verfahren und Praxisbeispiele. Online unter: [Abruf am 25.01.2020]
4 Enzyklopädie der Wirtschaftsinformatik Online – Lexikon (2019): Data Mining. Online unter: [Abruf am 25.01.2020]
5 Goodreads (2020): Signal Quotes. Online unter: https://www.goodreads.com/work/quotes/45158439-signal-understanding-what-matters-in-a-world-of-noise [Abruf am 30.01.2020]
6 MSO Digital (2019): Data Mining. Online unter: https://www.mso-digital.de/wiki/data-mining/ [Abruf am 25.01.2020]
7 Novustat (2019): Data Mining Methoden – ein verständlicher Überblick über die wichtigsten Verfahren. Online unter: https://novustat.com/statistik-blog/data-mining-methoden-ueberblick.html [Abruf am 25.01.2020]
8 Ordix AG (o. J.): Data Mining in der Praxis (Teil I). Online unter: [Abruf am 25.01.2020]
9 Wikipedia commons (2016): EM-Gausian-data.svg. Online unter: https://commons.wikimedia.org/wiki/File:EM-Gaussian-data.svg [Abruf am 31.01.2020]
Dieser Beitrag ist im Rahmen der Lehrveranstaltung Content Management im Wintersemester 2019/20 bei Andre Kreutzmann (und Monika Steinberg) entstanden.
In seiner Bachelorarbeit mit dem Titel “Analyse und Klassifikation der hannoverschen IT Kompetenzen in einer variablen Datenbasis“ schreibt Matthias Olbrisch (2019) in seinem Abstrakt:
„Die allgemeine Digitalisierung und besonders die IT-Branche in Hannover, stellen Arbeitgeber*innen vor große Herausforderungen. Berufsbezeichnungen im IT-Sektor zeichnen sich im Gegensatz zu klassischen Berufsfeldern nicht dadurch aus, dass sie vereinheitlicht sind. Unterschiedlichste Berufsbezeichnungen verlangen oftmals identische Kompetenzen. Die Kompetenzen und Fähigkeiten der Arbeitnehmer*innen stehen ebenso immer mehr im Fokus der Arbeitgeber*innen, wie die Bereitschaft der permanenten Weiterbildung.
Zielgebend der vorliegenden Abschlussarbeit ist eine Datenbasis zu liefern, die den Anspruch hat, die bereits beschriebenen Herausforderungen zu analysieren und zu klassifizieren. Zunächst ist daher eine Klassifikation, der auf dem hannoverschen Jobmarkt gesuchten IT-Kompetenzen, zu erstellen. Vorbereitend wird eine Marktanalyse angefertigt, die sowohl Jobsuchmaschinen auf ihre Kompetenzorientierung als auch IT-Kompetenzklassifikationen untersucht.
Die erstellte Klassifikation bildet anschließend die Grundlage für das Kompetenzmatching zwischen Klassifikation und den Kompetenzen, die hannoversche IT-Studierende erlernen, um zu verdeutlichen, in welchen Kompetenzen Weiterbildungsbedarf besteht. Die entstandene Datenbasis wird in einer MySQL Datenbank präsentiert, um eine möglichst flexible Verwendung und Weiterentwicklung des Datenbestands zu ermöglichen.“
Die Bachelorarbeit von Matthias ist Teil unseres Forschungsprojekts nITo (Nutzerzentrierte IT-Kompetenzoptimierung). Sie wurde vorbildlich über SerWisS veröffentlicht und ist als Volltext zu finden unter:

In der Bachelorarbeit von Sarah Büchting (2019) mit dem Titel „Webbasierte Programmierplattformen für Kinder im Vergleich“ wird thematisiert, wie Coding zu Zwecken der sich im Umbruch befindenden MINT-Bildung eingesetzt werden kann und welche Kompetenzen durch das Erlernen von Programmierfähigkeiten gefördert werden.
Darüber hinaus wird ein Bezug zur Informatik als Herkunftswissenschaft des Coding hergestellt und die Relevanz einer frühzeitigen Aneignung von Programmierfähigkeiten in einer digitalen Gesellschaft beleuchtet.
Eine Analyse der webbasierten Programmierplattformen Open Roberta Lab, Scratch, Sprite Lab von Code.org und TurtleCoder, die zur Vermittlung von Programmierfähigkeiten bei Kindern genutzt werden können, gibt Aufschluss darüber, ob sich die benannten Programmierplattformen auch für den Einsatz in außerschulischen Bildungseinrichtungen, wie etwa öffentlichen Bibliotheken, eignen.
Die Bachelorarbeit von Sarah wurde vorbildlich über SerWisS veröffentlicht und ist als Volltext zu finden unter:

Wir wünschen Euch ein frohes 2020 und einen guten Start ins neue Jahrzehnt!
Viel Begeisterung, Glück und Gesundheit!
Euer WebLab-Team <3



































































































